 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
Deep Insights into Cognitive Decline: A Survey of Leveraging Non-Intrusive Modalities with Deep Learning Techniques
Oct 24, 2024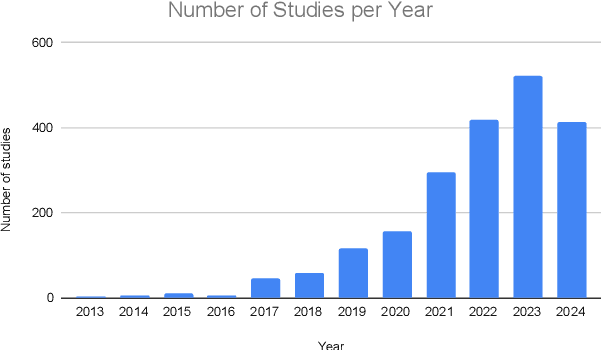
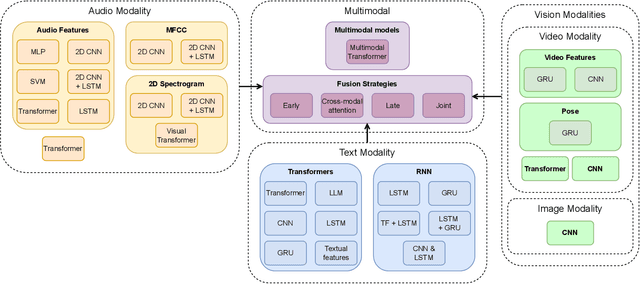
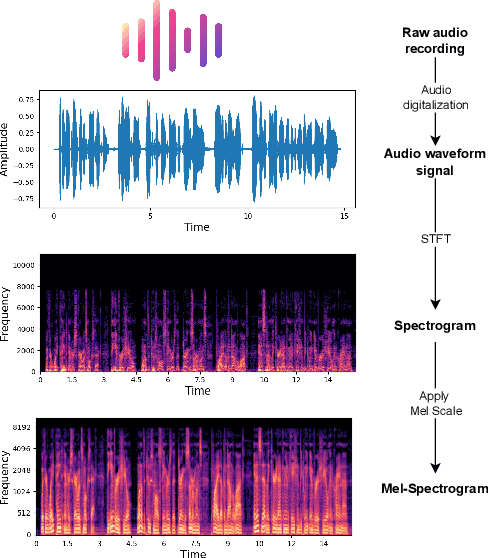
Cognitive decline is a natural part of aging, often resulting in reduced cognitive abilities. In some cases, however, this decline is more pronounced, typically due to disorders such as Alzheimer's disease. Early detection of anomalous cognitive decline is crucial, as it can facilitate timely professional intervention. While medical data can help in this detection, it often involves invasive procedures. An alternative approach is to employ non-intrusive techniques such as speech or handwriting analysis, which do not necessarily affect daily activities. This survey reviews the most relevant methodologies that use deep learning techniques to automate the cognitive decline estimation task, including audio, text, and visual processing. We discuss the key features and advantages of each modality and methodology, including state-of-the-art approaches like Transformer architecture and foundation models. In addition, we present works that integrate different modalities to develop multimodal models. We also highlight the most significant datasets and the quantitative results from studies using these resources. From this review, several conclusions emerge. In most cases, the textual modality achieves the best results and is the most relevant for detecting cognitive decline. Moreover, combining various approaches from individual modalities into a multimodal model consistently enhances performance across nearly all scenarios.
Cognitive Insights Across Languages: Enhancing Multimodal Interview Analysis
Jun 11, 2024Cognitive decline is a natural process that occurs as individuals age. Early diagnosis of anomalous decline is crucial for initiating professional treatment that can enhance the quality of life of those affected. To address this issue, we propose a multimodal model capable of predicting Mild Cognitive Impairment and cognitive scores. The TAUKADIAL dataset is used to conduct the evaluation, which comprises audio recordings of clinical interviews. The proposed model demonstrates the ability to transcribe and differentiate between languages used in the interviews. Subsequently, the model extracts audio and text features, combining them into a multimodal architecture to achieve robust and generalized results. Our approach involves in-depth research to implement various features obtained from the proposed modalities.