 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading or Guessing? Visual Grounding Failures of Vision-Language Models for OCR in Ancient Greek Editions
May 26, 2026Recent work has shown that Vision-Language Models (VLMs) used for optical character recognition (OCR) can generate plausible but visually unsupported text, suggesting reliance on language priors. Comparing open-weight VLMs with traditional OCR baselines on low-resource Ancient Greek critical editions, we show that VLM errors often remain fluent even when wrong, producing plausible Greek substitutions where traditional engines produce local recognition noise. To analyze visual evidence during decoding, we introduce controlled image perturbations and token-level grounding measures based on conditional versus image-free decoding distributions. Under character-level perturbations, VLMs diverge sharply from the perturbed ground truth while traditional OCR remains comparatively faithful; however, token-level analysis shows that prior reliance is model-specific: in an OCR-specialist model, fluent lexical errors are produced with little reliance on the image, whereas general-purpose VLMs remain conditioned on the visual input even when wrong. Decode-time interventions fail to reliably restore grounding, while post-OCR language-model correction improves several systems only by repairing text after generation. Our results extend prior evidence of OCR language-prior reliance to low-resource historical documents and a broader set of models, showing that fluent output is not necessarily visually grounded and motivating interpretability-driven evaluation beyond aggregate accuracy.
Structure-Aware Text Recognition for Ancient Greek Critical Editions
Mar 03, 2026Recent advances in visual language models (VLMs) have transformed end-to-end document understanding. However, their ability to interpret the complex layout semantics of historical scholarly texts remains limited. This paper investigates structure-aware text recognition for Ancient Greek critical editions, which have dense reference hierarchies and extensive marginal annotations. We introduce two novel resources: (i) a large-scale synthetic corpus of 185,000 page images generated from TEI/XML sources with controlled typographic and layout variation, and (ii) a curated benchmark of real scanned editions spanning more than a century of editorial and typographic practices. Using these datasets, we evaluate three state-of-the-art VLMs under both zero-shot and fine-tuning regimes. Our experiments reveal substantial limitations in current VLM architectures when confronted with highly structured historical documents. In zero-shot settings, most models significantly underperform compared to established off-the-shelf software. Nevertheless, the Qwen3VL-8B model achieves state-of-the-art performance, reaching a median Character Error Rate of 1.0\% on real scans. These results highlight both the current shortcomings and the future potential of VLMs for structure-aware recognition of complex scholarly documents.
Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory
May 28, 2025Modern vision-language models (VLMs) often fail at cultural competency evaluations and benchmarks. Given the diversity of applications built upon VLMs, there is renewed interest in understanding how they encode cultural nuances. While individual aspects of this problem have been studied, we still lack a comprehensive framework for systematically identifying and annotating the nuanced cultural dimensions present in images for VLMs. This position paper argues that foundational methodologies from visual culture studies (cultural studies, semiotics, and visual studies) are necessary for cultural analysis of images. Building upon this review, we propose a set of five frameworks, corresponding to cultural dimensions, that must be considered for a more complete analysis of the cultural competencies of VLMs.
NLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
Evaluating Multimodal Language Models as Visual Assistants for Visually Impaired Users
Mar 28, 2025This paper explores the effectiveness of Multimodal Large Language models (MLLMs) as assistive technologies for visually impaired individuals. We conduct a user survey to identify adoption patterns and key challenges users face with such technologies. Despite a high adoption rate of these models, our findings highlight concerns related to contextual understanding, cultural sensitivity, and complex scene understanding, particularly for individuals who may rely solely on them for visual interpretation. Informed by these results, we collate five user-centred tasks with image and video inputs, including a novel task on Optical Braille Recognition. Our systematic evaluation of twelve MLLMs reveals that further advancements are necessary to overcome limitations related to cultural context, multilingual support, Braille reading comprehension, assistive object recognition, and hallucinations. This work provides critical insights into the future direction of multimodal AI for accessibility, underscoring the need for more inclusive, robust, and trustworthy visual assistance technologies.
Ethical Concern Identification in NLP: A Corpus of ACL Anthology Ethics Statements
Nov 12, 2024



What ethical concerns, if any, do LLM researchers have? We introduce EthiCon, a corpus of 1,580 ethical concern statements extracted from scientific papers published in the ACL Anthology. We extract ethical concern keywords from the statements and show promising results in automating the concern identification process. Through a survey, we compare the ethical concerns of the corpus to the concerns listed by the general public and professionals in the field. Finally, we compare our retrieved ethical concerns with existing taxonomies pointing to gaps and future research directions.
Vision-Language Models under Cultural and Inclusive Considerations
Jul 08, 2024



Large vision-language models (VLMs) can assist visually impaired people by describing images from their daily lives. Current evaluation datasets may not reflect diverse cultural user backgrounds or the situational context of this use case. To address this problem, we create a survey to determine caption preferences and propose a culture-centric evaluation benchmark by filtering VizWiz, an existing dataset with images taken by people who are blind. We then evaluate several VLMs, investigating their reliability as visual assistants in a culturally diverse setting. While our results for state-of-the-art models are promising, we identify challenges such as hallucination and misalignment of automatic evaluation metrics with human judgment. We make our survey, data, code, and model outputs publicly available.
Exploring Visual Culture Awareness in GPT-4V: A Comprehensive Probing
Feb 15, 2024Pretrained large Vision-Language models have drawn considerable interest in recent years due to their remarkable performance. Despite considerable efforts to assess these models from diverse perspectives, the extent of visual cultural awareness in the state-of-the-art GPT-4V model remains unexplored. To tackle this gap, we extensively probed GPT-4V using the MaRVL benchmark dataset, aiming to investigate its capabilities and limitations in visual understanding with a focus on cultural aspects. Specifically, we introduced three visual related tasks, i.e. caption classification, pairwise captioning, and culture tag selection, to systematically delve into fine-grained visual cultural evaluation. Experimental results indicate that GPT-4V excels at identifying cultural concepts but still exhibits weaker performance in low-resource languages, such as Tamil and Swahili. Notably, through human evaluation, GPT-4V proves to be more culturally relevant in image captioning tasks than the original MaRVL human annotations, suggesting a promising solution for future visual cultural benchmark construction.
Cultural Adaptation of Recipes
Oct 26, 2023Building upon the considerable advances in Large Language Models (LLMs), we are now equipped to address more sophisticated tasks demanding a nuanced understanding of cross-cultural contexts. A key example is recipe adaptation, which goes beyond simple translation to include a grasp of ingredients, culinary techniques, and dietary preferences specific to a given culture. We introduce a new task involving the translation and cultural adaptation of recipes between Chinese and English-speaking cuisines. To support this investigation, we present CulturalRecipes, a unique dataset comprised of automatically paired recipes written in Mandarin Chinese and English. This dataset is further enriched with a human-written and curated test set. In this intricate task of cross-cultural recipe adaptation, we evaluate the performance of various methods, including GPT-4 and other LLMs, traditional machine translation, and information retrieval techniques. Our comprehensive analysis includes both automatic and human evaluation metrics. While GPT-4 exhibits impressive abilities in adapting Chinese recipes into English, it still lags behind human expertise when translating English recipes into Chinese. This underscores the multifaceted nature of cultural adaptations. We anticipate that these insights will significantly contribute to future research on culturally-aware language models and their practical application in culturally diverse contexts.
Copyright Violations and Large Language Models
Oct 20, 2023

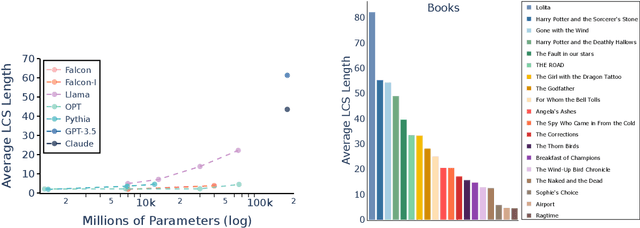

Language models may memorize more than just facts, including entire chunks of texts seen during training. Fair use exemptions to copyright laws typically allow for limited use of copyrighted material without permission from the copyright holder, but typically for extraction of information from copyrighted materials, rather than {\em verbatim} reproduction. This work explores the issue of copyright violations and large language models through the lens of verbatim memorization, focusing on possible redistribution of copyrighted text. We present experiments with a range of language models over a collection of popular books and coding problems, providing a conservative characterization of the extent to which language models can redistribute these materials. Overall, this research highlights the need for further examination and the potential impact on future developments in natural language processing to ensure adherence to copyright regulations. Code is at \url{https://github.com/coastalcph/CopyrightLLMs}.