 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrack2View: 4D-Consistent Camera-Controlled Video Generation via Paired 3D Point Tracks
Jun 14, 2026Re-rendering an existing video from a novel camera viewpoint requires the output to follow the prescribed camera trajectory while preserving the appearance and dynamics of the original scene across every frame. Existing methods rely on per-frame pose embeddings, noisy point-cloud renderings, or implicit learned correspondences, none of which provides an explicit, temporally continuous link between source and target pixels. We propose Track2View, which conditions a video diffusion transformer on paired 3D point tracks: sparse trajectories of scene points projected into both the source and target camera views. These tracks provide explicit spatiotemporal correspondences that are temporally continuous by construction, encoding what content should appear where and when. At the core of Track2View is a dual-view track conditioner that transfers visual context from source to target view through parameter-free geometric operations and learned temporal aggregation, ensuring generalization to arbitrary camera trajectories without memorizing specific motions. We further introduce a data curation pipeline that extracts one-to-one track correspondences by running a 3D point tracker on temporally concatenated multi-camera view pairs. On a 400-video benchmark spanning static and dynamic scenes, Track2View achieves state-of-the-art results across visual quality, view synchronization, and camera accuracy, reducing rotation error by 30-65% and translation error by 61-72% relative to leading baselines. Project page is available at this https URL: https://qjizhi.github.io/track2view
Stitched Value Model for Diffusion Alignment
May 19, 2026For practical use, diffusion- or flow-based generative models must be aligned with task-specific rewards, such as prompt fidelity or aesthetic preference. That alignment is challenging because the reward is defined for clean output images, but the alignment procedure requires value function estimates at noisy intermediate latents. Existing methods resort to Tweedie-style or Monte Carlo approximations, trading off estimator bias against computational cost: Tweedie estimates are efficient but biased, while Monte Carlo estimates are more accurate but require expensive rollouts. A natural alternative would be a learned value function, but it remains an open question how to effectively train a strong and general value model specifically for noisy latents. Here, we propose StitchVM, a model stitching framework that efficiently transfers reward models pretrained for clean images to the noisy latent regime. StitchVM starts from an existing, truncated pixel-space reward model and attaches a frozen diffusion backbone to it as its head. From the pixel-space model, the resulting hybrid retains a carefully pretrained, robust reward capability; from the diffusion backbone, it inherits its native ability to handle noisy latents. The stitching procedure is exceptionally lightweight, e.g., stitching and finetuning CLIP ViT-L and SD 3.5 Medium takes only 10 GPU-hours. By lifting powerful pixel-space reward models to latent space, StitchVM opens up a new style of diffusion alignment: instead of rough, yet costly per-sample approximation of the value function, the correct function for the actual, noisy latents is constructed once and then amortized over many samples and iterations. We show that this approach yields improvements across a broad range of downstream steering and post-training methods: DPS becomes $3.2\times$ faster while halving peak GPU memory, and DiffusionNFT becomes $2.3\times$ faster.
VGGRPO: Towards World-Consistent Video Generation with 4D Latent Reward
Mar 27, 2026Large-scale video diffusion models achieve impressive visual quality, yet often fail to preserve geometric consistency. Prior approaches improve consistency either by augmenting the generator with additional modules or applying geometry-aware alignment. However, architectural modifications can compromise the generalization of internet-scale pretrained models, while existing alignment methods are limited to static scenes and rely on RGB-space rewards that require repeated VAE decoding, incurring substantial compute overhead and failing to generalize to highly dynamic real-world scenes. To preserve the pretrained capacity while improving geometric consistency, we propose VGGRPO (Visual Geometry GRPO), a latent geometry-guided framework for geometry-aware video post-training. VGGRPO introduces a Latent Geometry Model (LGM) that stitches video diffusion latents to geometry foundation models, enabling direct decoding of scene geometry from the latent space. By constructing LGM from a geometry model with 4D reconstruction capability, VGGRPO naturally extends to dynamic scenes, overcoming the static-scene limitations of prior methods. Building on this, we perform latent-space Group Relative Policy Optimization with two complementary rewards: a camera motion smoothness reward that penalizes jittery trajectories, and a geometry reprojection consistency reward that enforces cross-view geometric coherence. Experiments on both static and dynamic benchmarks show that VGGRPO improves camera stability, geometry consistency, and overall quality while eliminating costly VAE decoding, making latent-space geometry-guided reinforcement an efficient and flexible approach to world-consistent video generation.
Video Understanding: From Geometry and Semantics to Unified Models
Mar 18, 2026Video understanding aims to enable models to perceive, reason about, and interact with the dynamic visual world. In contrast to image understanding, video understanding inherently requires modeling temporal dynamics and evolving visual context, placing stronger demands on spatiotemporal reasoning and making it a foundational problem in computer vision. In this survey, we present a structured overview of video understanding by organizing the literature into three complementary perspectives: low-level video geometry understanding, high-level semantic understanding, and unified video understanding models. We further highlight a broader shift from isolated, task-specific pipelines toward unified modeling paradigms that can be adapted to diverse downstream objectives, enabling a more systematic view of recent progress. By consolidating these perspectives, this survey provides a coherent map of the evolving video understanding landscape, summarizes key modeling trends and design principles, and outlines open challenges toward building robust, scalable, and unified video foundation models.
* A comprehensive survey of video understanding, spanning low-level geometry, high-level semantics, and unified understanding models
Revisiting the Perception-Distortion Trade-off with Spatial-Semantic Guided Super-Resolution
Mar 14, 2026Image super-resolution (SR) aims to reconstruct high resolution images with both high perceptual quality and low distortion, but is fundamentally limited by the perception-distortion trade-off. GAN-based SR methods reduce distortion but still struggle with realistic fine-grained textures, whereas diffusion-based approaches synthesize rich details but often deviate from the input, hallucinating structures and degrading fidelity. This tension raises a key challenge: how to exploit the powerful generative priors of diffusion models without sacrificing fidelity. To address this, we propose SpaSemSR, a spatial-semantic guided diffusion framework with two complementary guidances. First, spatial-grounded textual guidance integrates object-level spatial cues with semantic prompts, aligning textual and visual structures to reduce distortion. Second, semantic-enhanced visual guidance with a multi-encoder design and semantic degradation constraints unifies multimodal semantic priors, improving perceptual realism under severe degradations. These complementary guidances are adaptively fused into the diffusion process via spatial-semantic attention, suppressing distortion and hallucination while retaining the strengths of diffusion models. Extensive experiments on multiple benchmarks show that SpaSemSR achieves a superior perception-distortion balance, producing both realistic and faithful restorations.
VecGlypher: Unified Vector Glyph Generation with Language Models
Feb 25, 2026Vector glyphs are the atomic units of digital typography, yet most learning-based pipelines still depend on carefully curated exemplar sheets and raster-to-vector postprocessing, which limits accessibility and editability. We introduce VecGlypher, a single multimodal language model that generates high-fidelity vector glyphs directly from text descriptions or image exemplars. Given a style prompt, optional reference glyph images, and a target character, VecGlypher autoregressively emits SVG path tokens, avoiding raster intermediates and producing editable, watertight outlines in one pass. A typography-aware data and training recipe makes this possible: (i) a large-scale continuation stage on 39K noisy Envato fonts to master SVG syntax and long-horizon geometry, followed by (ii) post-training on 2.5K expert-annotated Google Fonts with descriptive tags and exemplars to align language and imagery with geometry; preprocessing normalizes coordinate frames, canonicalizes paths, de-duplicates families, and quantizes coordinates for stable long-sequence decoding. On cross-family OOD evaluation, VecGlypher substantially outperforms both general-purpose LLMs and specialized vector-font baselines for text-only generation, while image-referenced generation reaches a state-of-the-art performance, with marked gains over DeepVecFont-v2 and DualVector. Ablations show that model scale and the two-stage recipe are critical and that absolute-coordinate serialization yields the best geometry. VecGlypher lowers the barrier to font creation by letting users design with words or exemplars, and provides a scalable foundation for future multimodal design tools.
Thinking in Frames: How Visual Context and Test-Time Scaling Empower Video Reasoning
Jan 28, 2026Vision-Language Models have excelled at textual reasoning, but they often struggle with fine-grained spatial understanding and continuous action planning, failing to simulate the dynamics required for complex visual reasoning. In this work, we formulate visual reasoning by means of video generation models, positing that generated frames can act as intermediate reasoning steps between initial states and solutions. We evaluate their capacity in two distinct regimes: Maze Navigation for sequential discrete planning with low visual change and Tangram Puzzle for continuous manipulation with high visual change. Our experiments reveal three critical insights: (1) Robust Zero-Shot Generalization: In both tasks, the model demonstrates strong performance on unseen data distributions without specific finetuning. (2) Visual Context: The model effectively uses visual context as explicit control, such as agent icons and tangram shapes, enabling it to maintain high visual consistency and adapt its planning capability robustly to unseen patterns. (3) Visual Test-Time Scaling: We observe a test-time scaling law in sequential planning; increasing the generated video length (visual inference budget) empowers better zero-shot generalization to spatially and temporally complex paths. These findings suggest that video generation is not merely a media tool, but a scalable, generalizable paradigm for visual reasoning.
HiStream: Efficient High-Resolution Video Generation via Redundancy-Eliminated Streaming
Dec 24, 2025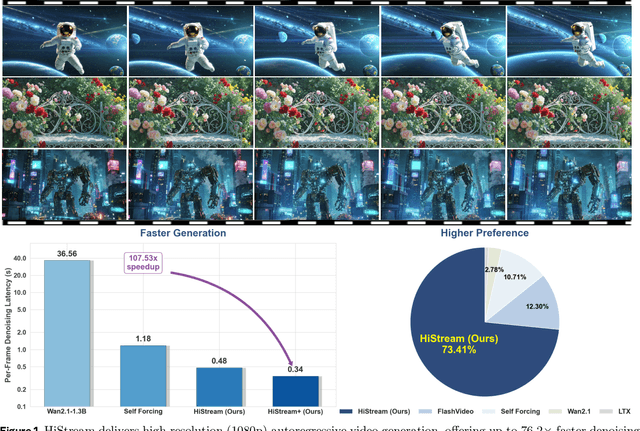
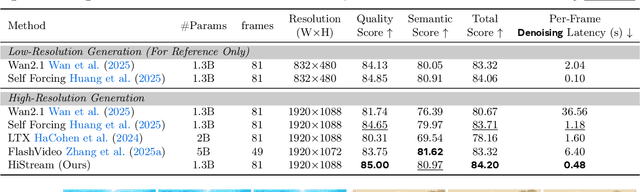
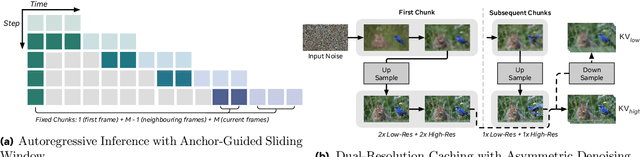
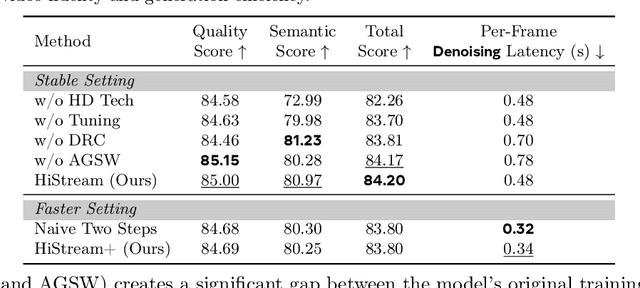
High-resolution video generation, while crucial for digital media and film, is computationally bottlenecked by the quadratic complexity of diffusion models, making practical inference infeasible. To address this, we introduce HiStream, an efficient autoregressive framework that systematically reduces redundancy across three axes: i) Spatial Compression: denoising at low resolution before refining at high resolution with cached features; ii) Temporal Compression: a chunk-by-chunk strategy with a fixed-size anchor cache, ensuring stable inference speed; and iii) Timestep Compression: applying fewer denoising steps to subsequent, cache-conditioned chunks. On 1080p benchmarks, our primary HiStream model (i+ii) achieves state-of-the-art visual quality while demonstrating up to 76.2x faster denoising compared to the Wan2.1 baseline and negligible quality loss. Our faster variant, HiStream+, applies all three optimizations (i+ii+iii), achieving a 107.5x acceleration over the baseline, offering a compelling trade-off between speed and quality, thereby making high-resolution video generation both practical and scalable.
OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory
Dec 08, 2025
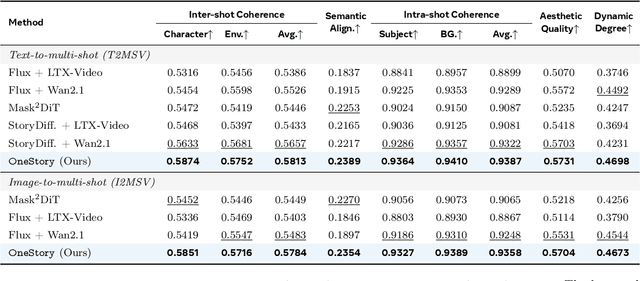
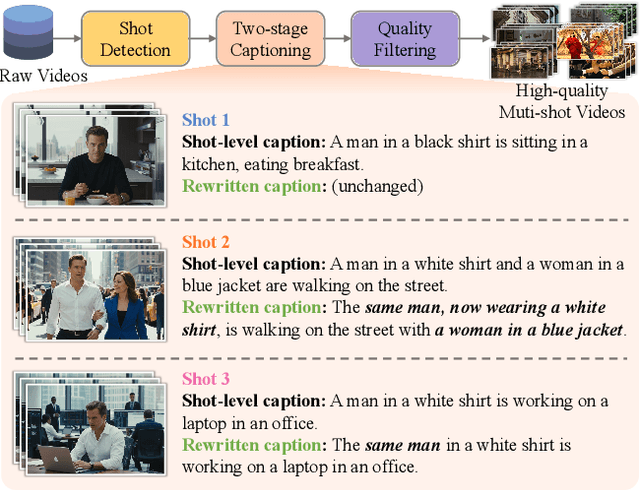

Storytelling in real-world videos often unfolds through multiple shots -- discontinuous yet semantically connected clips that together convey a coherent narrative. However, existing multi-shot video generation (MSV) methods struggle to effectively model long-range cross-shot context, as they rely on limited temporal windows or single keyframe conditioning, leading to degraded performance under complex narratives. In this work, we propose OneStory, enabling global yet compact cross-shot context modeling for consistent and scalable narrative generation. OneStory reformulates MSV as a next-shot generation task, enabling autoregressive shot synthesis while leveraging pretrained image-to-video (I2V) models for strong visual conditioning. We introduce two key modules: a Frame Selection module that constructs a semantically-relevant global memory based on informative frames from prior shots, and an Adaptive Conditioner that performs importance-guided patchification to generate compact context for direct conditioning. We further curate a high-quality multi-shot dataset with referential captions to mirror real-world storytelling patterns, and design effective training strategies under the next-shot paradigm. Finetuned from a pretrained I2V model on our curated 60K dataset, OneStory achieves state-of-the-art narrative coherence across diverse and complex scenes in both text- and image-conditioned settings, enabling controllable and immersive long-form video storytelling.
Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory
May 28, 2025Modern vision-language models (VLMs) often fail at cultural competency evaluations and benchmarks. Given the diversity of applications built upon VLMs, there is renewed interest in understanding how they encode cultural nuances. While individual aspects of this problem have been studied, we still lack a comprehensive framework for systematically identifying and annotating the nuanced cultural dimensions present in images for VLMs. This position paper argues that foundational methodologies from visual culture studies (cultural studies, semiotics, and visual studies) are necessary for cultural analysis of images. Building upon this review, we propose a set of five frameworks, corresponding to cultural dimensions, that must be considered for a more complete analysis of the cultural competencies of VLMs.