 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal-aware Hierarchical Mask Classification for Video Semantic Segmentation
Paper and Code
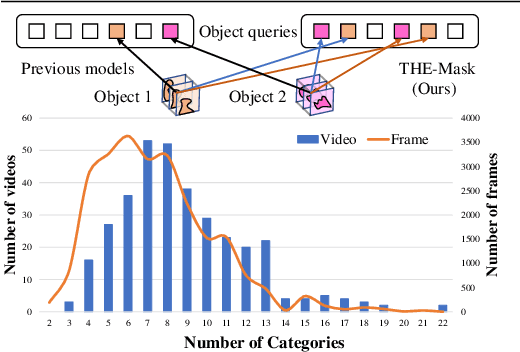
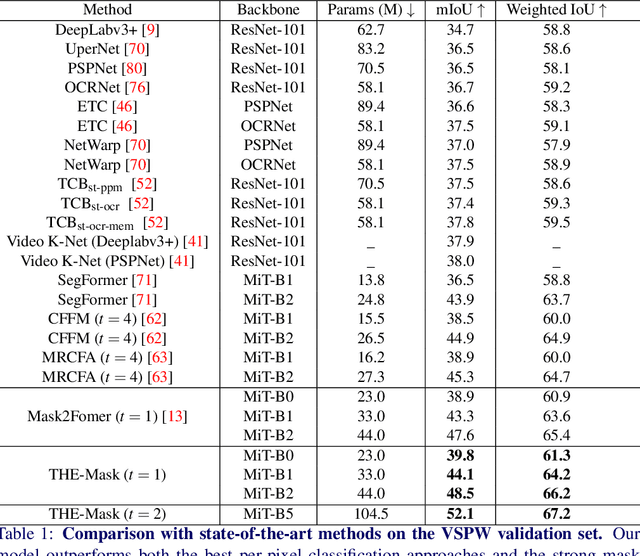
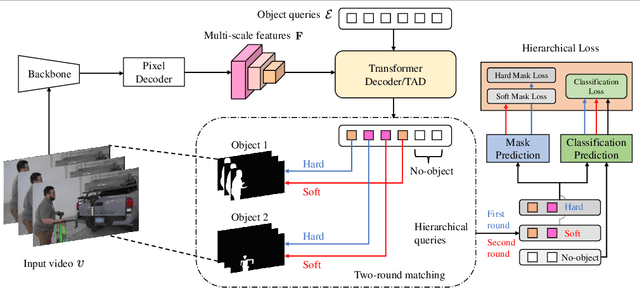

Modern approaches have proved the huge potential of addressing semantic segmentation as a mask classification task which is widely used in instance-level segmentation. This paradigm trains models by assigning part of object queries to ground truths via conventional one-to-one matching. However, we observe that the popular video semantic segmentation (VSS) dataset has limited categories per video, meaning less than 10% of queries could be matched to receive meaningful gradient updates during VSS training. This inefficiency limits the full expressive potential of all queries.Thus, we present a novel solution THE-Mask for VSS, which introduces temporal-aware hierarchical object queries for the first time. Specifically, we propose to use a simple two-round matching mechanism to involve more queries matched with minimal cost during training while without any extra cost during inference. To support our more-to-one assignment, in terms of the matching results, we further design a hierarchical loss to train queries with their corresponding hierarchy of primary or secondary. Moreover, to effectively capture temporal information across frames, we propose a temporal aggregation decoder that fits seamlessly into the mask-classification paradigm for VSS. Utilizing temporal-sensitive multi-level queries, our method achieves state-of-the-art performance on the latest challenging VSS benchmark VSPW without bells and whistles.