 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamBeast: Distilling 3D Fantastical Animals with Part-Aware Knowledge Transfer
Sep 12, 2024



We present DreamBeast, a novel method based on score distillation sampling (SDS) for generating fantastical 3D animal assets composed of distinct parts. Existing SDS methods often struggle with this generation task due to a limited understanding of part-level semantics in text-to-image diffusion models. While recent diffusion models, such as Stable Diffusion 3, demonstrate a better part-level understanding, they are prohibitively slow and exhibit other common problems associated with single-view diffusion models. DreamBeast overcomes this limitation through a novel part-aware knowledge transfer mechanism. For each generated asset, we efficiently extract part-level knowledge from the Stable Diffusion 3 model into a 3D Part-Affinity implicit representation. This enables us to instantly generate Part-Affinity maps from arbitrary camera views, which we then use to modulate the guidance of a multi-view diffusion model during SDS to create 3D assets of fantastical animals. DreamBeast significantly enhances the quality of generated 3D creatures with user-specified part compositions while reducing computational overhead, as demonstrated by extensive quantitative and qualitative evaluations.
Modeling Real-Time Interactive Conversations as Timed Diarized Transcripts
May 21, 2024
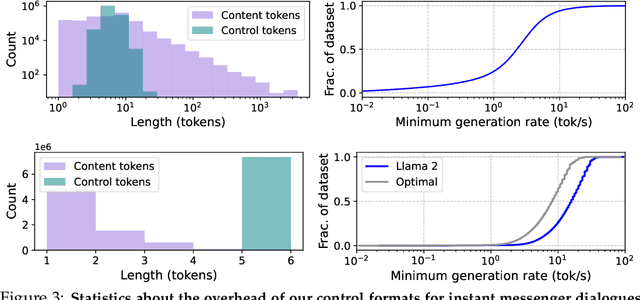


Chatbots built upon language models have exploded in popularity, but they have largely been limited to synchronous, turn-by-turn dialogues. In this paper we present a simple yet general method to simulate real-time interactive conversations using pretrained text-only language models, by modeling timed diarized transcripts and decoding them with causal rejection sampling. We demonstrate the promise of this method with two case studies: instant messenger dialogues and spoken conversations, which require generation at about 30 tok/s and 20 tok/s respectively to maintain real-time interactivity. These capabilities can be added into language models using relatively little data and run on commodity hardware.
GES: Generalized Exponential Splatting for Efficient Radiance Field Rendering
Feb 15, 2024



Advancements in 3D Gaussian Splatting have significantly accelerated 3D reconstruction and generation. However, it may require a large number of Gaussians, which creates a substantial memory footprint. This paper introduces GES (Generalized Exponential Splatting), a novel representation that employs Generalized Exponential Function (GEF) to model 3D scenes, requiring far fewer particles to represent a scene and thus significantly outperforming Gaussian Splatting methods in efficiency with a plug-and-play replacement ability for Gaussian-based utilities. GES is validated theoretically and empirically in both principled 1D setup and realistic 3D scenes. It is shown to represent signals with sharp edges more accurately, which are typically challenging for Gaussians due to their inherent low-pass characteristics. Our empirical analysis demonstrates that GEF outperforms Gaussians in fitting natural-occurring signals (e.g. squares, triangles, and parabolic signals), thereby reducing the need for extensive splitting operations that increase the memory footprint of Gaussian Splatting. With the aid of a frequency-modulated loss, GES achieves competitive performance in novel-view synthesis benchmarks while requiring less than half the memory storage of Gaussian Splatting and increasing the rendering speed by up to 39%. The code is available on the project website https://abdullahamdi.com/ges .
IM-3D: Iterative Multiview Diffusion and Reconstruction for High-Quality 3D Generation
Feb 13, 2024Most text-to-3D generators build upon off-the-shelf text-to-image models trained on billions of images. They use variants of Score Distillation Sampling (SDS), which is slow, somewhat unstable, and prone to artifacts. A mitigation is to fine-tune the 2D generator to be multi-view aware, which can help distillation or can be combined with reconstruction networks to output 3D objects directly. In this paper, we further explore the design space of text-to-3D models. We significantly improve multi-view generation by considering video instead of image generators. Combined with a 3D reconstruction algorithm which, by using Gaussian splatting, can optimize a robust image-based loss, we directly produce high-quality 3D outputs from the generated views. Our new method, IM-3D, reduces the number of evaluations of the 2D generator network 10-100x, resulting in a much more efficient pipeline, better quality, fewer geometric inconsistencies, and higher yield of usable 3D assets.
Fixed Point Diffusion Models
Jan 16, 2024
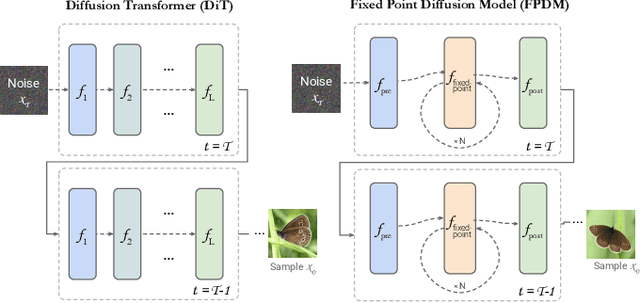

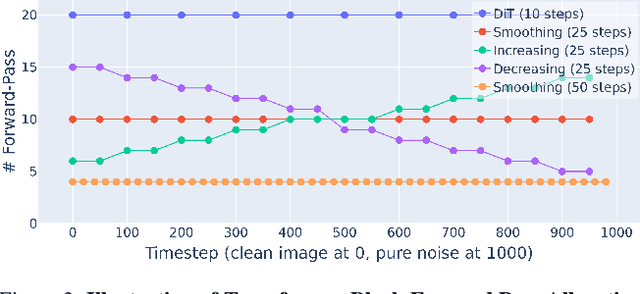
We introduce the Fixed Point Diffusion Model (FPDM), a novel approach to image generation that integrates the concept of fixed point solving into the framework of diffusion-based generative modeling. Our approach embeds an implicit fixed point solving layer into the denoising network of a diffusion model, transforming the diffusion process into a sequence of closely-related fixed point problems. Combined with a new stochastic training method, this approach significantly reduces model size, reduces memory usage, and accelerates training. Moreover, it enables the development of two new techniques to improve sampling efficiency: reallocating computation across timesteps and reusing fixed point solutions between timesteps. We conduct extensive experiments with state-of-the-art models on ImageNet, FFHQ, CelebA-HQ, and LSUN-Church, demonstrating substantial improvements in performance and efficiency. Compared to the state-of-the-art DiT model, FPDM contains 87% fewer parameters, consumes 60% less memory during training, and improves image generation quality in situations where sampling computation or time is limited. Our code and pretrained models are available at https://lukemelas.github.io/fixed-point-diffusion-models.
Understanding Self-Supervised Features for Learning Unsupervised Instance Segmentation
Nov 24, 2023
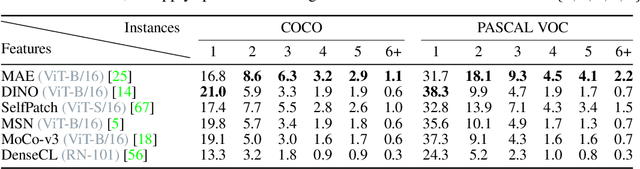
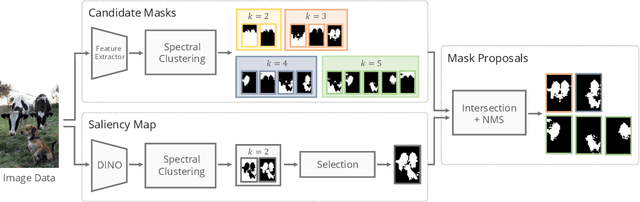
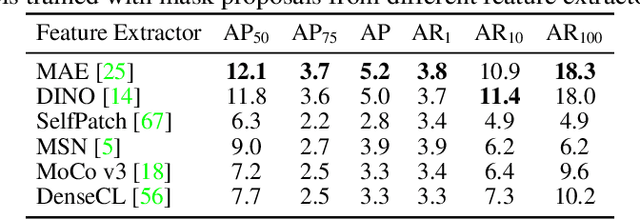
Self-supervised learning (SSL) can be used to solve complex visual tasks without human labels. Self-supervised representations encode useful semantic information about images, and as a result, they have already been used for tasks such as unsupervised semantic segmentation. In this paper, we investigate self-supervised representations for instance segmentation without any manual annotations. We find that the features of different SSL methods vary in their level of instance-awareness. In particular, DINO features, which are known to be excellent semantic descriptors, lack behind MAE features in their sensitivity for separating instances.
A Benchmark for Learning to Translate a New Language from One Grammar Book
Sep 28, 2023Large language models (LLMs) can perform impressive feats with in-context learning or lightweight finetuning. It is natural to wonder how well these models adapt to genuinely new tasks, but how does one find tasks that are unseen in internet-scale training sets? We turn to a field that is explicitly motivated and bottlenecked by a scarcity of web data: low-resource languages. In this paper, we introduce MTOB (Machine Translation from One Book), a benchmark for learning to translate between English and Kalamang -- a language with less than 200 speakers and therefore virtually no presence on the web -- using several hundred pages of field linguistics reference materials. This task framing is novel in that it asks a model to learn a language from a single human-readable book of grammar explanations, rather than a large mined corpus of in-domain data, more akin to L2 learning than L1 acquisition. We demonstrate that baselines using current LLMs are promising but fall short of human performance, achieving 44.7 chrF on Kalamang to English translation and 45.8 chrF on English to Kalamang translation, compared to 51.6 and 57.0 chrF by a human who learned Kalamang from the same reference materials. We hope that MTOB will help measure LLM capabilities along a new dimension, and that the methods developed to solve it could help expand access to language technology for underserved communities by leveraging qualitatively different kinds of data than traditional machine translation.
Augmenting medical image classifiers with synthetic data from latent diffusion models
Aug 23, 2023



While hundreds of artificial intelligence (AI) algorithms are now approved or cleared by the US Food and Drugs Administration (FDA), many studies have shown inconsistent generalization or latent bias, particularly for underrepresented populations. Some have proposed that generative AI could reduce the need for real data, but its utility in model development remains unclear. Skin disease serves as a useful case study in synthetic image generation due to the diversity of disease appearance, particularly across the protected attribute of skin tone. Here we show that latent diffusion models can scalably generate images of skin disease and that augmenting model training with these data improves performance in data-limited settings. These performance gains saturate at synthetic-to-real image ratios above 10:1 and are substantially smaller than the gains obtained from adding real images. As part of our analysis, we generate and analyze a new dataset of 458,920 synthetic images produced using several generation strategies. Our results suggest that synthetic data could serve as a force-multiplier for model development, but the collection of diverse real-world data remains the most important step to improve medical AI algorithms.
RealFusion: 360° Reconstruction of Any Object from a Single Image
Feb 23, 2023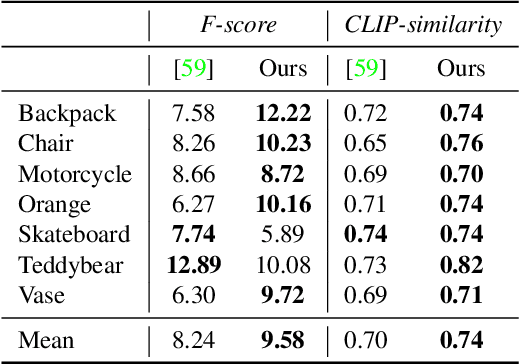
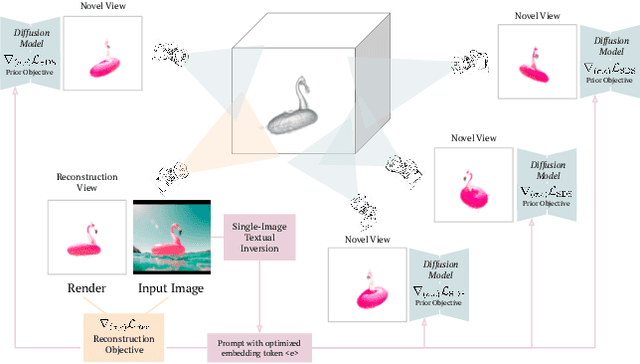


We consider the problem of reconstructing a full 360{\deg} photographic model of an object from a single image of it. We do so by fitting a neural radiance field to the image, but find this problem to be severely ill-posed. We thus take an off-the-self conditional image generator based on diffusion and engineer a prompt that encourages it to "dream up" novel views of the object. Using an approach inspired by DreamFields and DreamFusion, we fuse the given input view, the conditional prior, and other regularizers in a final, consistent reconstruction. We demonstrate state-of-the-art reconstruction results on benchmark images when compared to prior methods for monocular 3D reconstruction of objects. Qualitatively, our reconstructions provide a faithful match of the input view and a plausible extrapolation of its appearance and 3D shape, including to the side of the object not visible in the image.
$PC^2$: Projection-Conditioned Point Cloud Diffusion for Single-Image 3D Reconstruction
Feb 23, 2023Reconstructing the 3D shape of an object from a single RGB image is a long-standing and highly challenging problem in computer vision. In this paper, we propose a novel method for single-image 3D reconstruction which generates a sparse point cloud via a conditional denoising diffusion process. Our method takes as input a single RGB image along with its camera pose and gradually denoises a set of 3D points, whose positions are initially sampled randomly from a three-dimensional Gaussian distribution, into the shape of an object. The key to our method is a geometrically-consistent conditioning process which we call projection conditioning: at each step in the diffusion process, we project local image features onto the partially-denoised point cloud from the given camera pose. This projection conditioning process enables us to generate high-resolution sparse geometries that are well-aligned with the input image, and can additionally be used to predict point colors after shape reconstruction. Moreover, due to the probabilistic nature of the diffusion process, our method is naturally capable of generating multiple different shapes consistent with a single input image. In contrast to prior work, our approach not only performs well on synthetic benchmarks, but also gives large qualitative improvements on complex real-world data.