Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Self-Supervised Features for Learning Unsupervised Instance Segmentation
Paper and Code
Nov 24, 2023
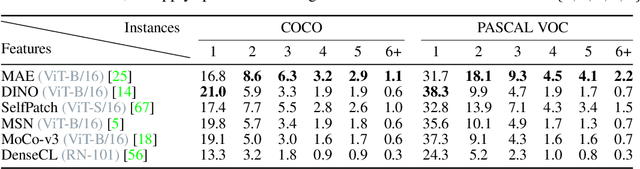
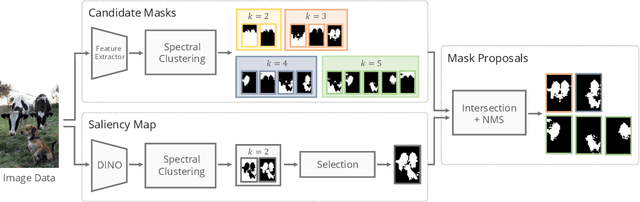
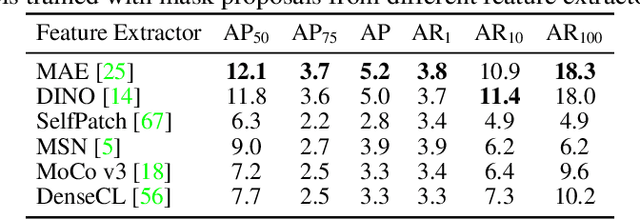
Self-supervised learning (SSL) can be used to solve complex visual tasks without human labels. Self-supervised representations encode useful semantic information about images, and as a result, they have already been used for tasks such as unsupervised semantic segmentation. In this paper, we investigate self-supervised representations for instance segmentation without any manual annotations. We find that the features of different SSL methods vary in their level of instance-awareness. In particular, DINO features, which are known to be excellent semantic descriptors, lack behind MAE features in their sensitivity for separating instances.
View paper on