 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynCity: Training-Free Generation of 3D Worlds
Mar 20, 2025We address the challenge of generating 3D worlds from textual descriptions. We propose SynCity, a training- and optimization-free approach, which leverages the geometric precision of pre-trained 3D generative models and the artistic versatility of 2D image generators to create large, high-quality 3D spaces. While most 3D generative models are object-centric and cannot generate large-scale worlds, we show how 3D and 2D generators can be combined to generate ever-expanding scenes. Through a tile-based approach, we allow fine-grained control over the layout and the appearance of scenes. The world is generated tile-by-tile, and each new tile is generated within its world-context and then fused with the scene. SynCity generates compelling and immersive scenes that are rich in detail and diversity.
Invisible Stitch: Generating Smooth 3D Scenes with Depth Inpainting
Apr 30, 2024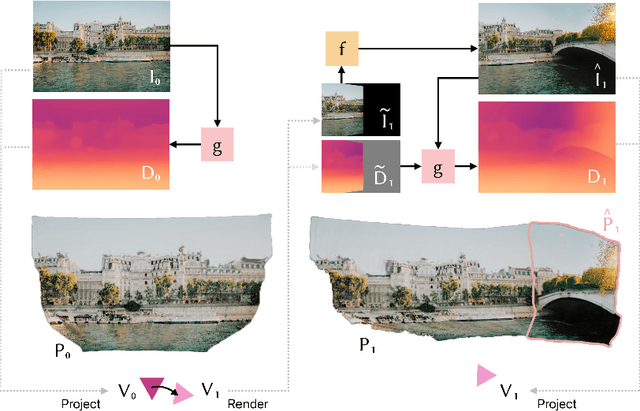
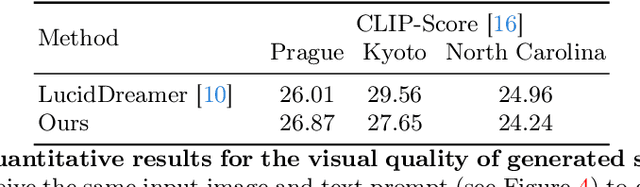
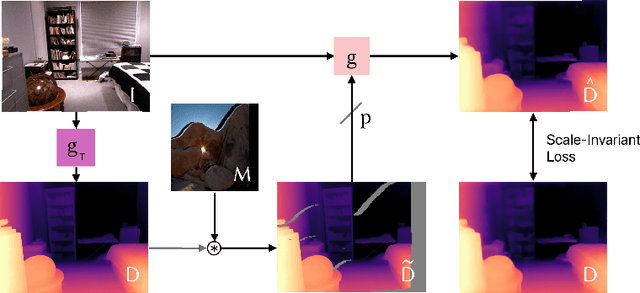
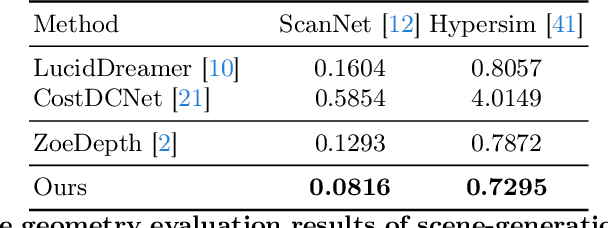
3D scene generation has quickly become a challenging new research direction, fueled by consistent improvements of 2D generative diffusion models. Most prior work in this area generates scenes by iteratively stitching newly generated frames with existing geometry. These works often depend on pre-trained monocular depth estimators to lift the generated images into 3D, fusing them with the existing scene representation. These approaches are then often evaluated via a text metric, measuring the similarity between the generated images and a given text prompt. In this work, we make two fundamental contributions to the field of 3D scene generation. First, we note that lifting images to 3D with a monocular depth estimation model is suboptimal as it ignores the geometry of the existing scene. We thus introduce a novel depth completion model, trained via teacher distillation and self-training to learn the 3D fusion process, resulting in improved geometric coherence of the scene. Second, we introduce a new benchmarking scheme for scene generation methods that is based on ground truth geometry, and thus measures the quality of the structure of the scene.
Understanding Self-Supervised Features for Learning Unsupervised Instance Segmentation
Nov 24, 2023
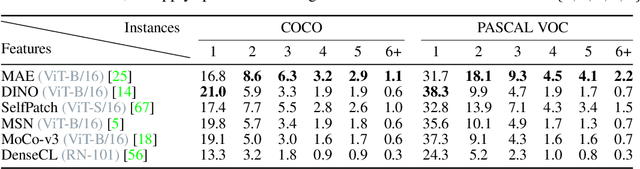
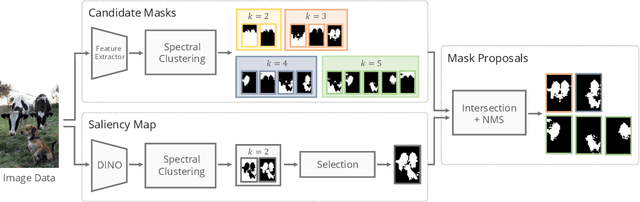
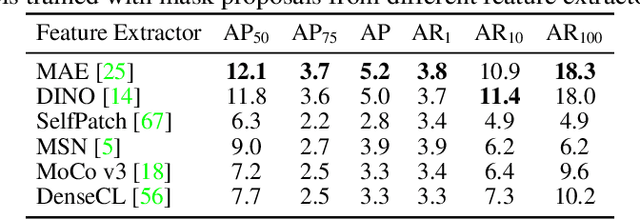
Self-supervised learning (SSL) can be used to solve complex visual tasks without human labels. Self-supervised representations encode useful semantic information about images, and as a result, they have already been used for tasks such as unsupervised semantic segmentation. In this paper, we investigate self-supervised representations for instance segmentation without any manual annotations. We find that the features of different SSL methods vary in their level of instance-awareness. In particular, DINO features, which are known to be excellent semantic descriptors, lack behind MAE features in their sensitivity for separating instances.
Interpretable Vertebral Fracture Diagnosis
Mar 30, 2022
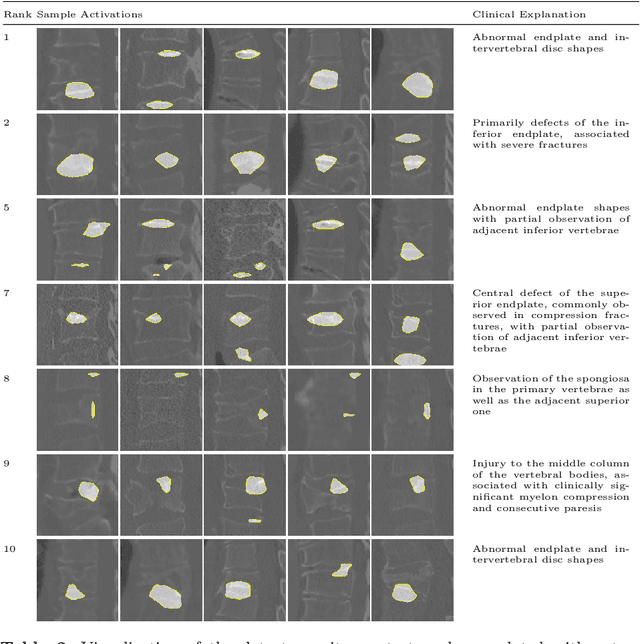
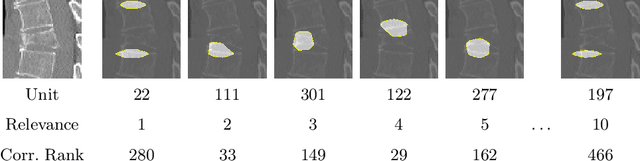
Do black-box neural network models learn clinically relevant features for fracture diagnosis? The answer not only establishes reliability quenches scientific curiosity but also leads to explainable and verbose findings that can assist the radiologists in the final and increase trust. This work identifies the concepts networks use for vertebral fracture diagnosis in CT images. This is achieved by associating concepts to neurons highly correlated with a specific diagnosis in the dataset. The concepts are either associated with neurons by radiologists pre-hoc or are visualized during a specific prediction and left for the user's interpretation. We evaluate which concepts lead to correct diagnosis and which concepts lead to false positives. The proposed frameworks and analysis pave the way for reliable and explainable vertebral fracture diagnosis.