 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvisible Stitch: Generating Smooth 3D Scenes with Depth Inpainting
Paper and Code
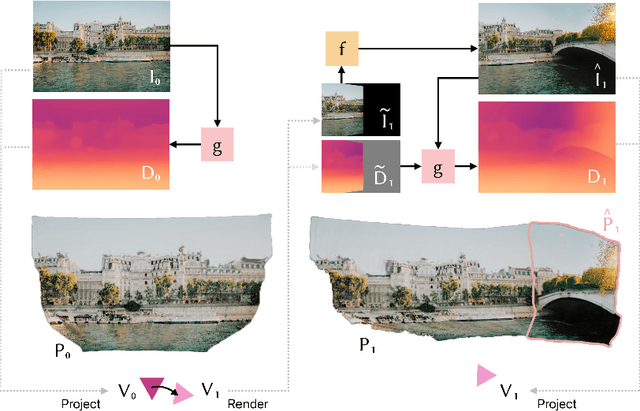
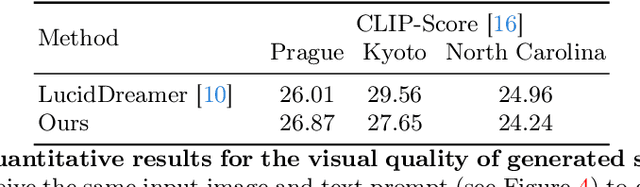
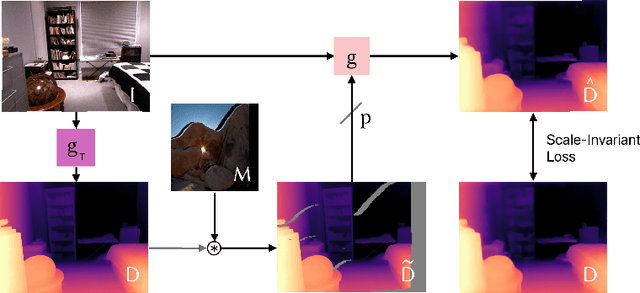
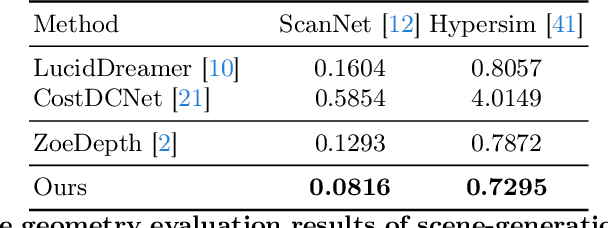
3D scene generation has quickly become a challenging new research direction, fueled by consistent improvements of 2D generative diffusion models. Most prior work in this area generates scenes by iteratively stitching newly generated frames with existing geometry. These works often depend on pre-trained monocular depth estimators to lift the generated images into 3D, fusing them with the existing scene representation. These approaches are then often evaluated via a text metric, measuring the similarity between the generated images and a given text prompt. In this work, we make two fundamental contributions to the field of 3D scene generation. First, we note that lifting images to 3D with a monocular depth estimation model is suboptimal as it ignores the geometry of the existing scene. We thus introduce a novel depth completion model, trained via teacher distillation and self-training to learn the 3D fusion process, resulting in improved geometric coherence of the scene. Second, we introduce a new benchmarking scheme for scene generation methods that is based on ground truth geometry, and thus measures the quality of the structure of the scene.