 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperhuman performance of a large language model on the reasoning tasks of a physician
Dec 14, 2024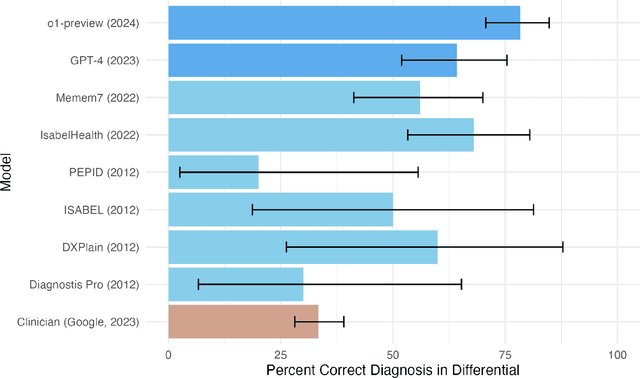
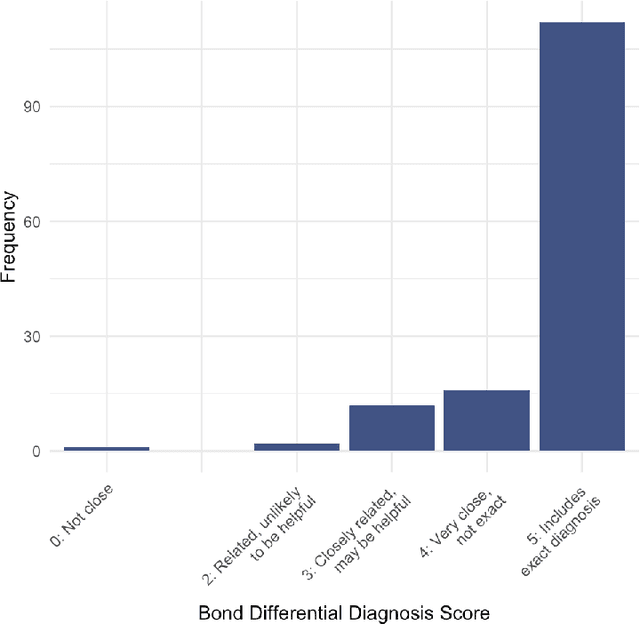

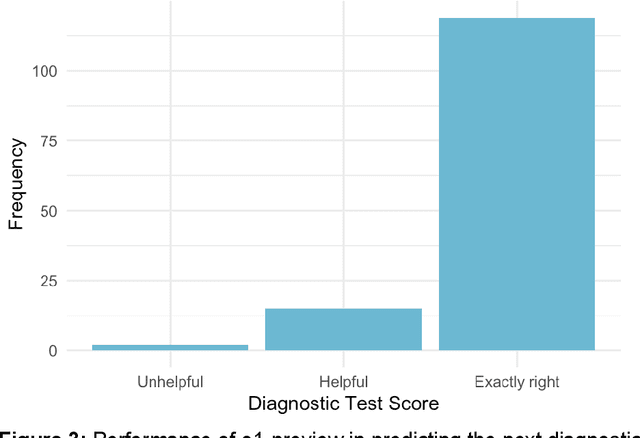
Performance of large language models (LLMs) on medical tasks has traditionally been evaluated using multiple choice question benchmarks. However, such benchmarks are highly constrained, saturated with repeated impressive performance by LLMs, and have an unclear relationship to performance in real clinical scenarios. Clinical reasoning, the process by which physicians employ critical thinking to gather and synthesize clinical data to diagnose and manage medical problems, remains an attractive benchmark for model performance. Prior LLMs have shown promise in outperforming clinicians in routine and complex diagnostic scenarios. We sought to evaluate OpenAI's o1-preview model, a model developed to increase run-time via chain of thought processes prior to generating a response. We characterize the performance of o1-preview with five experiments including differential diagnosis generation, display of diagnostic reasoning, triage differential diagnosis, probabilistic reasoning, and management reasoning, adjudicated by physician experts with validated psychometrics. Our primary outcome was comparison of the o1-preview output to identical prior experiments that have historical human controls and benchmarks of previous LLMs. Significant improvements were observed with differential diagnosis generation and quality of diagnostic and management reasoning. No improvements were observed with probabilistic reasoning or triage differential diagnosis. This study highlights o1-preview's ability to perform strongly on tasks that require complex critical thinking such as diagnosis and management while its performance on probabilistic reasoning tasks was similar to past models. New robust benchmarks and scalable evaluation of LLM capabilities compared to human physicians are needed along with trials evaluating AI in real clinical settings.
Accuracy of a Vision-Language Model on Challenging Medical Cases
Nov 09, 2023Background: General-purpose large language models that utilize both text and images have not been evaluated on a diverse array of challenging medical cases. Methods: Using 934 cases from the NEJM Image Challenge published between 2005 and 2023, we evaluated the accuracy of the recently released Generative Pre-trained Transformer 4 with Vision model (GPT-4V) compared to human respondents overall and stratified by question difficulty, image type, and skin tone. We further conducted a physician evaluation of GPT-4V on 69 NEJM clinicopathological conferences (CPCs). Analyses were conducted for models utilizing text alone, images alone, and both text and images. Results: GPT-4V achieved an overall accuracy of 61% (95% CI, 58 to 64%) compared to 49% (95% CI, 49 to 50%) for humans. GPT-4V outperformed humans at all levels of difficulty and disagreement, skin tones, and image types; the exception was radiographic images, where performance was equivalent between GPT-4V and human respondents. Longer, more informative captions were associated with improved performance for GPT-4V but similar performance for human respondents. GPT-4V included the correct diagnosis in its differential for 80% (95% CI, 68 to 88%) of CPCs when using text alone, compared to 58% (95% CI, 45 to 70%) of CPCs when using both images and text. Conclusions: GPT-4V outperformed human respondents on challenging medical cases and was able to synthesize information from both images and text, but performance deteriorated when images were added to highly informative text. Overall, our results suggest that multimodal AI models may be useful in medical diagnostic reasoning but that their accuracy may depend heavily on context.
Augmenting medical image classifiers with synthetic data from latent diffusion models
Aug 23, 2023



While hundreds of artificial intelligence (AI) algorithms are now approved or cleared by the US Food and Drugs Administration (FDA), many studies have shown inconsistent generalization or latent bias, particularly for underrepresented populations. Some have proposed that generative AI could reduce the need for real data, but its utility in model development remains unclear. Skin disease serves as a useful case study in synthetic image generation due to the diversity of disease appearance, particularly across the protected attribute of skin tone. Here we show that latent diffusion models can scalably generate images of skin disease and that augmenting model training with these data improves performance in data-limited settings. These performance gains saturate at synthetic-to-real image ratios above 10:1 and are substantially smaller than the gains obtained from adding real images. As part of our analysis, we generate and analyze a new dataset of 458,920 synthetic images produced using several generation strategies. Our results suggest that synthetic data could serve as a force-multiplier for model development, but the collection of diverse real-world data remains the most important step to improve medical AI algorithms.
Improving dermatology classifiers across populations using images generated by large diffusion models
Nov 23, 2022Dermatological classification algorithms developed without sufficiently diverse training data may generalize poorly across populations. While intentional data collection and annotation offer the best means for improving representation, new computational approaches for generating training data may also aid in mitigating the effects of sampling bias. In this paper, we show that DALL$\cdot$E 2, a large-scale text-to-image diffusion model, can produce photorealistic images of skin disease across skin types. Using the Fitzpatrick 17k dataset as a benchmark, we demonstrate that augmenting training data with DALL$\cdot$E 2-generated synthetic images improves classification of skin disease overall and especially for underrepresented groups.
PixMatch: Unsupervised Domain Adaptation via Pixelwise Consistency Training
May 17, 2021


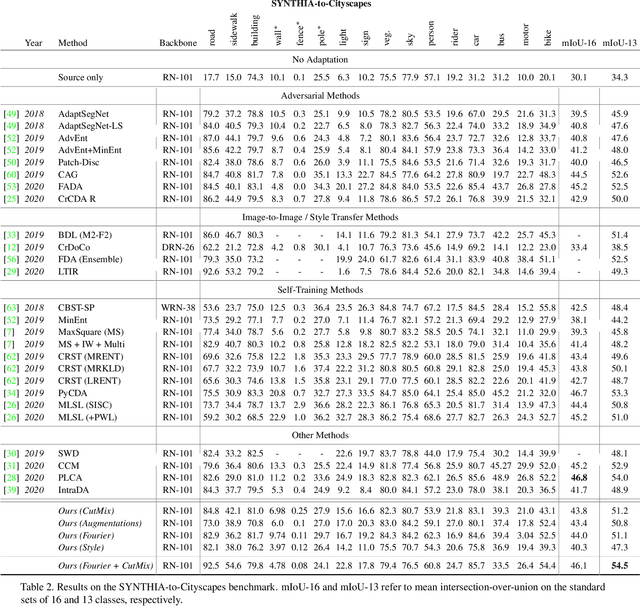
Unsupervised domain adaptation is a promising technique for semantic segmentation and other computer vision tasks for which large-scale data annotation is costly and time-consuming. In semantic segmentation, it is attractive to train models on annotated images from a simulated (source) domain and deploy them on real (target) domains. In this work, we present a novel framework for unsupervised domain adaptation based on the notion of target-domain consistency training. Intuitively, our work is based on the idea that in order to perform well on the target domain, a model's output should be consistent with respect to small perturbations of inputs in the target domain. Specifically, we introduce a new loss term to enforce pixelwise consistency between the model's predictions on a target image and a perturbed version of the same image. In comparison to popular adversarial adaptation methods, our approach is simpler, easier to implement, and more memory-efficient during training. Experiments and extensive ablation studies demonstrate that our simple approach achieves remarkably strong results on two challenging synthetic-to-real benchmarks, GTA5-to-Cityscapes and SYNTHIA-to-Cityscapes. Code is available at: https://github.com/lukemelas/pixmatch