 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadGame: An AI-Powered Platform for Radiology Education
Sep 16, 2025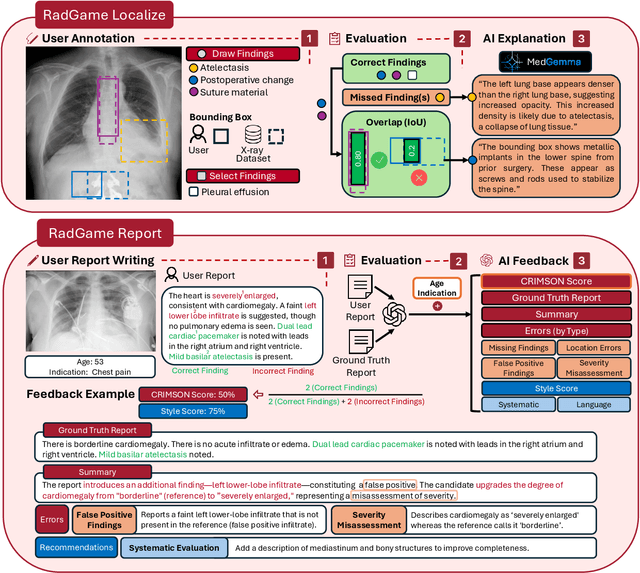
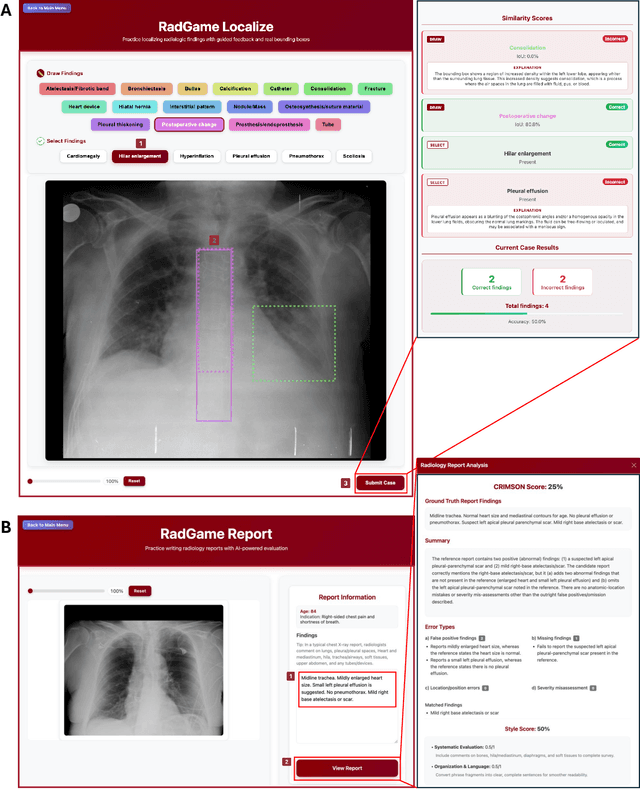
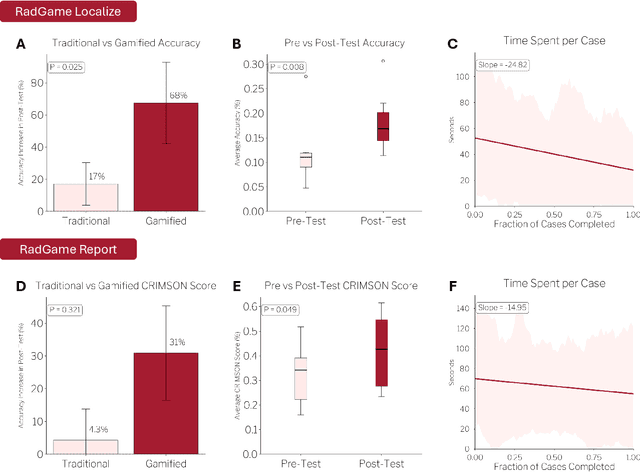

We introduce RadGame, an AI-powered gamified platform for radiology education that targets two core skills: localizing findings and generating reports. Traditional radiology training is based on passive exposure to cases or active practice with real-time input from supervising radiologists, limiting opportunities for immediate and scalable feedback. RadGame addresses this gap by combining gamification with large-scale public datasets and automated, AI-driven feedback that provides clear, structured guidance to human learners. In RadGame Localize, players draw bounding boxes around abnormalities, which are automatically compared to radiologist-drawn annotations from public datasets, and visual explanations are generated by vision-language models for user missed findings. In RadGame Report, players compose findings given a chest X-ray, patient age and indication, and receive structured AI feedback based on radiology report generation metrics, highlighting errors and omissions compared to a radiologist's written ground truth report from public datasets, producing a final performance and style score. In a prospective evaluation, participants using RadGame achieved a 68% improvement in localization accuracy compared to 17% with traditional passive methods and a 31% improvement in report-writing accuracy compared to 4% with traditional methods after seeing the same cases. RadGame highlights the potential of AI-driven gamification to deliver scalable, feedback-rich radiology training and reimagines the application of medical AI resources in education.
One Patient, Many Contexts: Scaling Medical AI Through Contextual Intelligence
Jun 11, 2025

Medical foundation models, including language models trained on clinical notes, vision-language models on medical images, and multimodal models on electronic health records, can summarize clinical notes, answer medical questions, and assist in decision-making. Adapting these models to new populations, specialties, or settings typically requires fine-tuning, careful prompting, or retrieval from knowledge bases. This can be impractical, and limits their ability to interpret unfamiliar inputs and adjust to clinical situations not represented during training. As a result, models are prone to contextual errors, where predictions appear reasonable but fail to account for critical patient-specific or contextual information. These errors stem from a fundamental limitation that current models struggle with: dynamically adjusting their behavior across evolving contexts of medical care. In this Perspective, we outline a vision for context-switching in medical AI: models that dynamically adapt their reasoning without retraining to new specialties, populations, workflows, and clinical roles. We envision context-switching AI to diagnose, manage, and treat a wide range of diseases across specialties and regions, and expand access to medical care.
Advancing Conversational Diagnostic AI with Multimodal Reasoning
May 06, 2025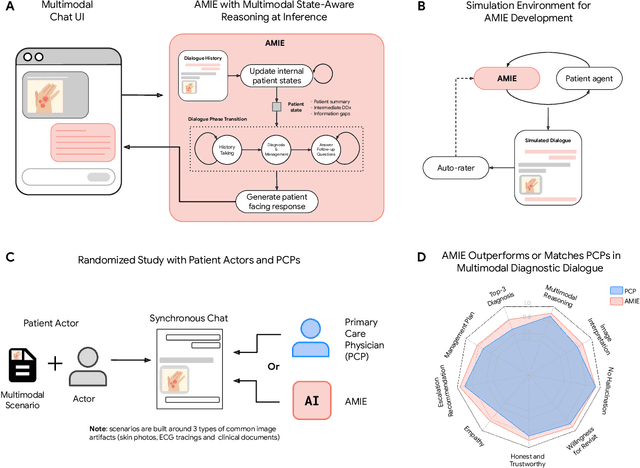
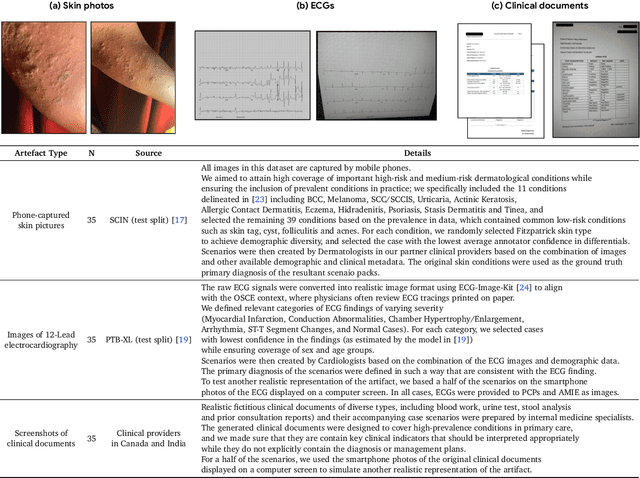
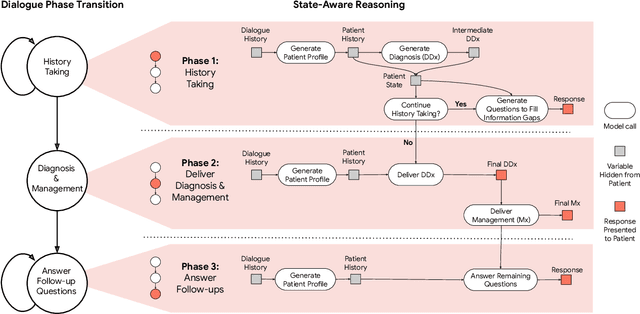
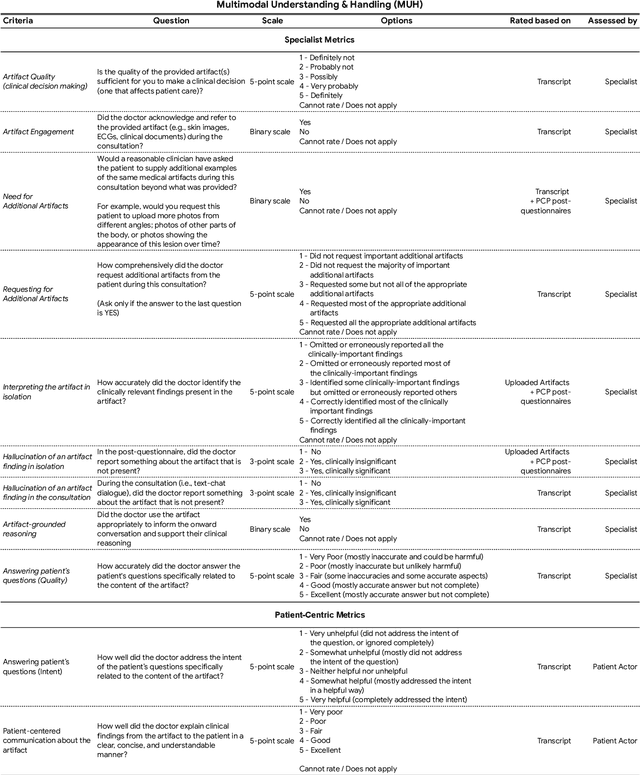
Large Language Models (LLMs) have demonstrated great potential for conducting diagnostic conversations but evaluation has been largely limited to language-only interactions, deviating from the real-world requirements of remote care delivery. Instant messaging platforms permit clinicians and patients to upload and discuss multimodal medical artifacts seamlessly in medical consultation, but the ability of LLMs to reason over such data while preserving other attributes of competent diagnostic conversation remains unknown. Here we advance the conversational diagnosis and management performance of the Articulate Medical Intelligence Explorer (AMIE) through a new capability to gather and interpret multimodal data, and reason about this precisely during consultations. Leveraging Gemini 2.0 Flash, our system implements a state-aware dialogue framework, where conversation flow is dynamically controlled by intermediate model outputs reflecting patient states and evolving diagnoses. Follow-up questions are strategically directed by uncertainty in such patient states, leading to a more structured multimodal history-taking process that emulates experienced clinicians. We compared AMIE to primary care physicians (PCPs) in a randomized, blinded, OSCE-style study of chat-based consultations with patient actors. We constructed 105 evaluation scenarios using artifacts like smartphone skin photos, ECGs, and PDFs of clinical documents across diverse conditions and demographics. Our rubric assessed multimodal capabilities and other clinically meaningful axes like history-taking, diagnostic accuracy, management reasoning, communication, and empathy. Specialist evaluation showed AMIE to be superior to PCPs on 7/9 multimodal and 29/32 non-multimodal axes (including diagnostic accuracy). The results show clear progress in multimodal conversational diagnostic AI, but real-world translation needs further research.
BRIDGE: Benchmarking Large Language Models for Understanding Real-world Clinical Practice Text
May 01, 2025



Large language models (LLMs) hold great promise for medical applications and are evolving rapidly, with new models being released at an accelerated pace. However, current evaluations of LLMs in clinical contexts remain limited. Most existing benchmarks rely on medical exam-style questions or PubMed-derived text, failing to capture the complexity of real-world electronic health record (EHR) data. Others focus narrowly on specific application scenarios, limiting their generalizability across broader clinical use. To address this gap, we present BRIDGE, a comprehensive multilingual benchmark comprising 87 tasks sourced from real-world clinical data sources across nine languages. We systematically evaluated 52 state-of-the-art LLMs (including DeepSeek-R1, GPT-4o, Gemini, and Llama 4) under various inference strategies. With a total of 13,572 experiments, our results reveal substantial performance variation across model sizes, languages, natural language processing tasks, and clinical specialties. Notably, we demonstrate that open-source LLMs can achieve performance comparable to proprietary models, while medically fine-tuned LLMs based on older architectures often underperform versus updated general-purpose models. The BRIDGE and its corresponding leaderboard serve as a foundational resource and a unique reference for the development and evaluation of new LLMs in real-world clinical text understanding. The BRIDGE leaderboard: https://huggingface.co/spaces/YLab-Open/BRIDGE-Medical-Leaderboard
Towards Conversational AI for Disease Management
Mar 08, 2025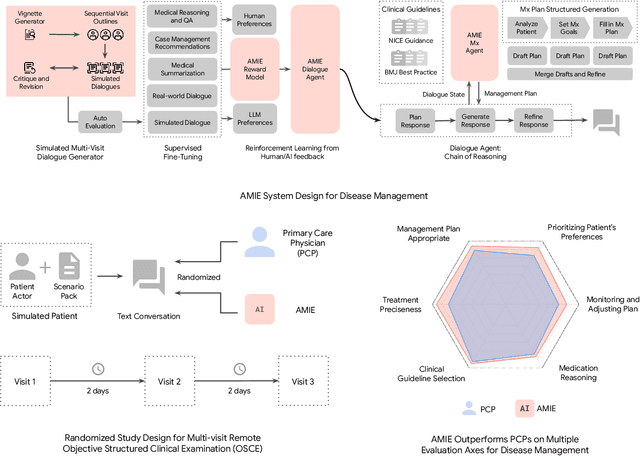

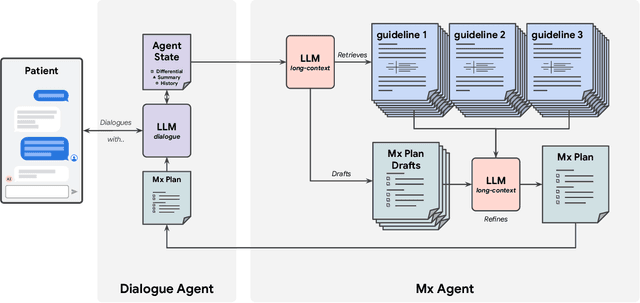
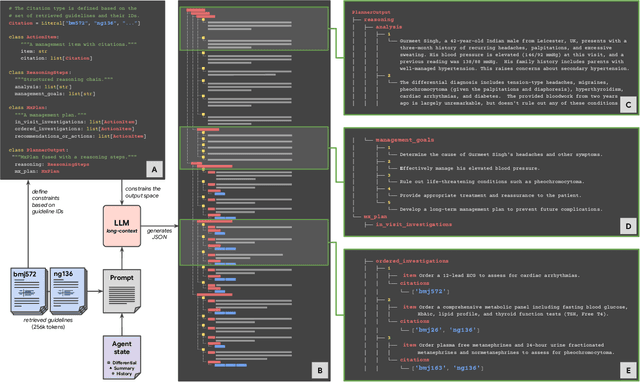
While large language models (LLMs) have shown promise in diagnostic dialogue, their capabilities for effective management reasoning - including disease progression, therapeutic response, and safe medication prescription - remain under-explored. We advance the previously demonstrated diagnostic capabilities of the Articulate Medical Intelligence Explorer (AMIE) through a new LLM-based agentic system optimised for clinical management and dialogue, incorporating reasoning over the evolution of disease and multiple patient visit encounters, response to therapy, and professional competence in medication prescription. To ground its reasoning in authoritative clinical knowledge, AMIE leverages Gemini's long-context capabilities, combining in-context retrieval with structured reasoning to align its output with relevant and up-to-date clinical practice guidelines and drug formularies. In a randomized, blinded virtual Objective Structured Clinical Examination (OSCE) study, AMIE was compared to 21 primary care physicians (PCPs) across 100 multi-visit case scenarios designed to reflect UK NICE Guidance and BMJ Best Practice guidelines. AMIE was non-inferior to PCPs in management reasoning as assessed by specialist physicians and scored better in both preciseness of treatments and investigations, and in its alignment with and grounding of management plans in clinical guidelines. To benchmark medication reasoning, we developed RxQA, a multiple-choice question benchmark derived from two national drug formularies (US, UK) and validated by board-certified pharmacists. While AMIE and PCPs both benefited from the ability to access external drug information, AMIE outperformed PCPs on higher difficulty questions. While further research would be needed before real-world translation, AMIE's strong performance across evaluations marks a significant step towards conversational AI as a tool in disease management.
Superhuman performance of a large language model on the reasoning tasks of a physician
Dec 14, 2024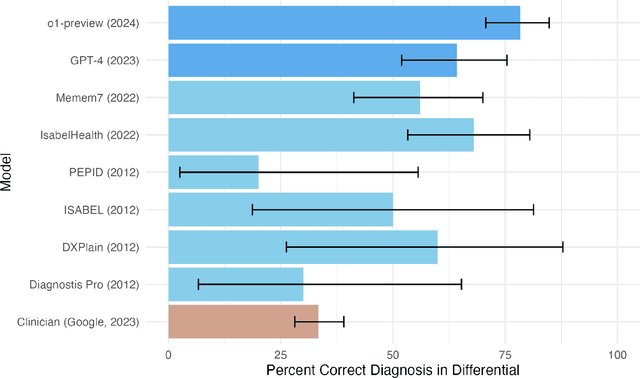
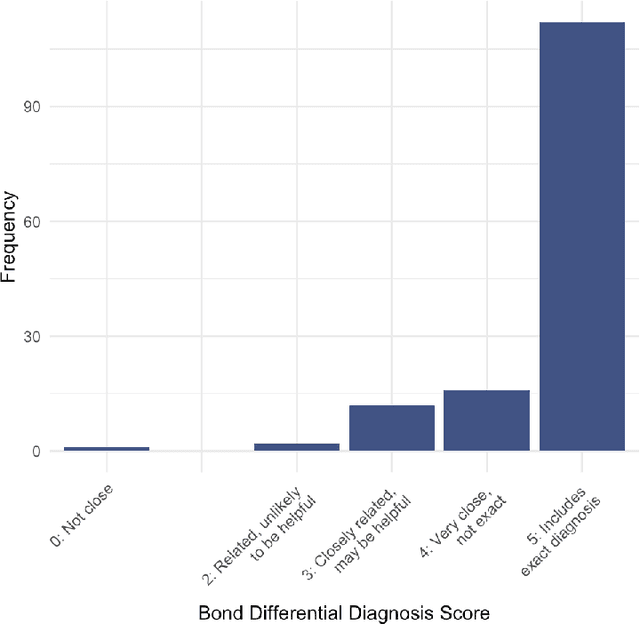

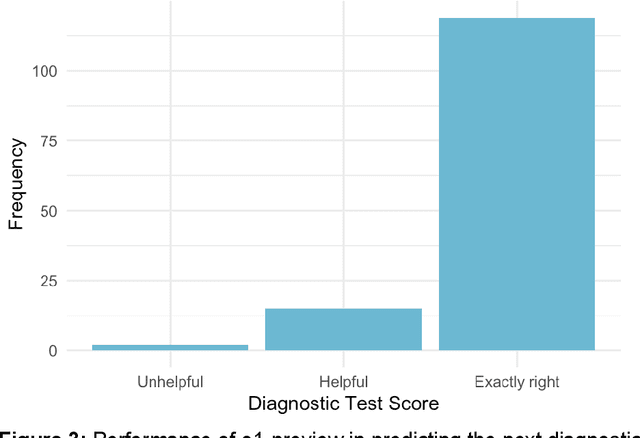
Performance of large language models (LLMs) on medical tasks has traditionally been evaluated using multiple choice question benchmarks. However, such benchmarks are highly constrained, saturated with repeated impressive performance by LLMs, and have an unclear relationship to performance in real clinical scenarios. Clinical reasoning, the process by which physicians employ critical thinking to gather and synthesize clinical data to diagnose and manage medical problems, remains an attractive benchmark for model performance. Prior LLMs have shown promise in outperforming clinicians in routine and complex diagnostic scenarios. We sought to evaluate OpenAI's o1-preview model, a model developed to increase run-time via chain of thought processes prior to generating a response. We characterize the performance of o1-preview with five experiments including differential diagnosis generation, display of diagnostic reasoning, triage differential diagnosis, probabilistic reasoning, and management reasoning, adjudicated by physician experts with validated psychometrics. Our primary outcome was comparison of the o1-preview output to identical prior experiments that have historical human controls and benchmarks of previous LLMs. Significant improvements were observed with differential diagnosis generation and quality of diagnostic and management reasoning. No improvements were observed with probabilistic reasoning or triage differential diagnosis. This study highlights o1-preview's ability to perform strongly on tasks that require complex critical thinking such as diagnosis and management while its performance on probabilistic reasoning tasks was similar to past models. New robust benchmarks and scalable evaluation of LLM capabilities compared to human physicians are needed along with trials evaluating AI in real clinical settings.
Accuracy of a Vision-Language Model on Challenging Medical Cases
Nov 09, 2023Background: General-purpose large language models that utilize both text and images have not been evaluated on a diverse array of challenging medical cases. Methods: Using 934 cases from the NEJM Image Challenge published between 2005 and 2023, we evaluated the accuracy of the recently released Generative Pre-trained Transformer 4 with Vision model (GPT-4V) compared to human respondents overall and stratified by question difficulty, image type, and skin tone. We further conducted a physician evaluation of GPT-4V on 69 NEJM clinicopathological conferences (CPCs). Analyses were conducted for models utilizing text alone, images alone, and both text and images. Results: GPT-4V achieved an overall accuracy of 61% (95% CI, 58 to 64%) compared to 49% (95% CI, 49 to 50%) for humans. GPT-4V outperformed humans at all levels of difficulty and disagreement, skin tones, and image types; the exception was radiographic images, where performance was equivalent between GPT-4V and human respondents. Longer, more informative captions were associated with improved performance for GPT-4V but similar performance for human respondents. GPT-4V included the correct diagnosis in its differential for 80% (95% CI, 68 to 88%) of CPCs when using text alone, compared to 58% (95% CI, 45 to 70%) of CPCs when using both images and text. Conclusions: GPT-4V outperformed human respondents on challenging medical cases and was able to synthesize information from both images and text, but performance deteriorated when images were added to highly informative text. Overall, our results suggest that multimodal AI models may be useful in medical diagnostic reasoning but that their accuracy may depend heavily on context.