 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasyV2V: A High-quality Instruction-based Video Editing Framework
Dec 18, 2025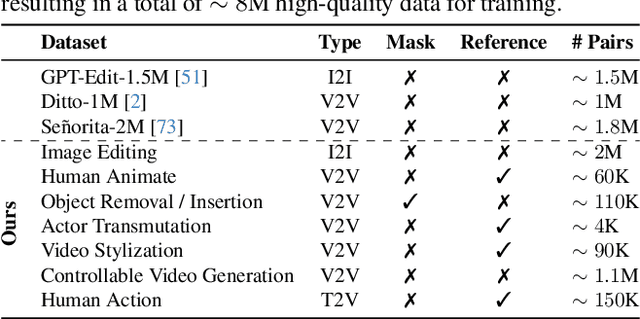

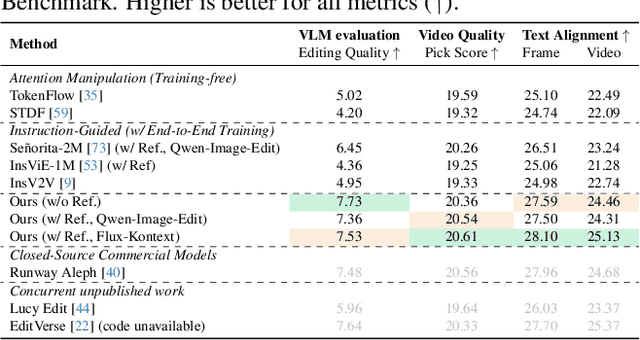
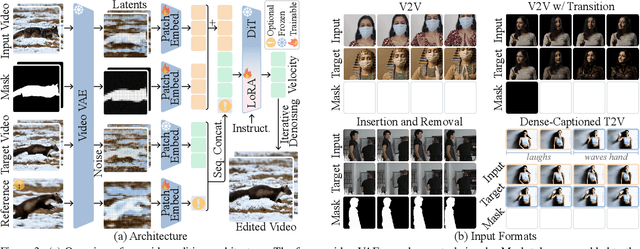
While image editing has advanced rapidly, video editing remains less explored, facing challenges in consistency, control, and generalization. We study the design space of data, architecture, and control, and introduce \emph{EasyV2V}, a simple and effective framework for instruction-based video editing. On the data side, we compose existing experts with fast inverses to build diverse video pairs, lift image edit pairs into videos via single-frame supervision and pseudo pairs with shared affine motion, mine dense-captioned clips for video pairs, and add transition supervision to teach how edits unfold. On the model side, we observe that pretrained text-to-video models possess editing capability, motivating a simplified design. Simple sequence concatenation for conditioning with light LoRA fine-tuning suffices to train a strong model. For control, we unify spatiotemporal control via a single mask mechanism and support optional reference images. Overall, EasyV2V works with flexible inputs, e.g., video+text, video+mask+text, video+mask+reference+text, and achieves state-of-the-art video editing results, surpassing concurrent and commercial systems. Project page: https://snap-research.github.io/easyv2v/
Can Video Diffusion Model Reconstruct 4D Geometry?
Mar 27, 2025Reconstructing dynamic 3D scenes (i.e., 4D geometry) from monocular video is an important yet challenging problem. Conventional multiview geometry-based approaches often struggle with dynamic motion, whereas recent learning-based methods either require specialized 4D representation or sophisticated optimization. In this paper, we present Sora3R, a novel framework that taps into the rich spatiotemporal priors of large-scale video diffusion models to directly infer 4D pointmaps from casual videos. Sora3R follows a two-stage pipeline: (1) we adapt a pointmap VAE from a pretrained video VAE, ensuring compatibility between the geometry and video latent spaces; (2) we finetune a diffusion backbone in combined video and pointmap latent space to generate coherent 4D pointmaps for every frame. Sora3R operates in a fully feedforward manner, requiring no external modules (e.g., depth, optical flow, or segmentation) or iterative global alignment. Extensive experiments demonstrate that Sora3R reliably recovers both camera poses and detailed scene geometry, achieving performance on par with state-of-the-art methods for dynamic 4D reconstruction across diverse scenarios.
TrackNeRF: Bundle Adjusting NeRF from Sparse and Noisy Views via Feature Tracks
Aug 20, 2024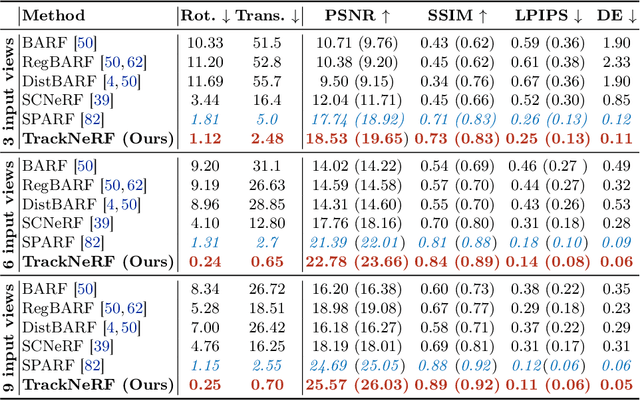
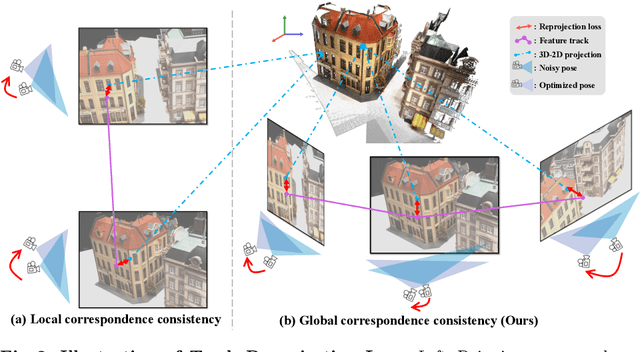
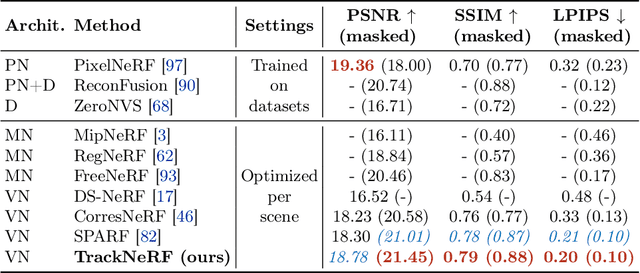

Neural radiance fields (NeRFs) generally require many images with accurate poses for accurate novel view synthesis, which does not reflect realistic setups where views can be sparse and poses can be noisy. Previous solutions for learning NeRFs with sparse views and noisy poses only consider local geometry consistency with pairs of views. Closely following \textit{bundle adjustment} in Structure-from-Motion (SfM), we introduce TrackNeRF for more globally consistent geometry reconstruction and more accurate pose optimization. TrackNeRF introduces \textit{feature tracks}, \ie connected pixel trajectories across \textit{all} visible views that correspond to the \textit{same} 3D points. By enforcing reprojection consistency among feature tracks, TrackNeRF encourages holistic 3D consistency explicitly. Through extensive experiments, TrackNeRF sets a new benchmark in noisy and sparse view reconstruction. In particular, TrackNeRF shows significant improvements over the state-of-the-art BARF and SPARF by $\sim8$ and $\sim1$ in terms of PSNR on DTU under various sparse and noisy view setups. The code is available at \href{https://tracknerf.github.io/}.
Hybrid Structure-from-Motion and Camera Relocalization for Enhanced Egocentric Localization
Jul 10, 2024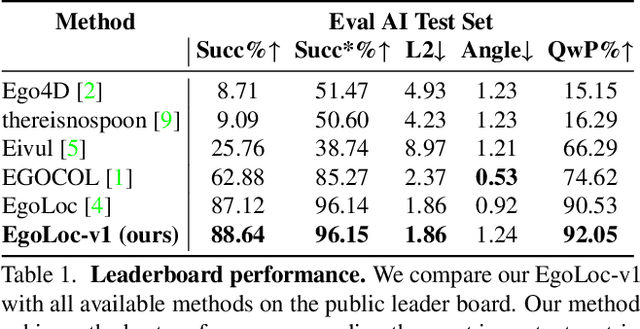
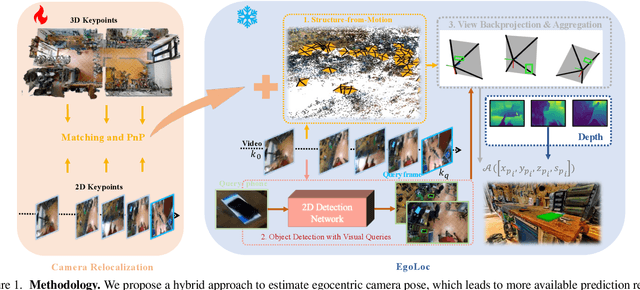
We built our pipeline EgoLoc-v1, mainly inspired by EgoLoc. We propose a model ensemble strategy to improve the camera pose estimation part of the VQ3D task, which has been proven to be essential in previous work. The core idea is not only to do SfM for egocentric videos but also to do 2D-3D matching between existing 3D scans and 2D video frames. In this way, we have a hybrid SfM and camera relocalization pipeline, which can provide us with more camera poses, leading to higher QwP and overall success rate. Our method achieves the best performance regarding the most important metric, the overall success rate. We surpass previous state-of-the-art, the competitive EgoLoc, by $1.5\%$. The code is available at \url{https://github.com/Wayne-Mai/egoloc_v1}.
Vivid-ZOO: Multi-View Video Generation with Diffusion Model
Jun 12, 2024



While diffusion models have shown impressive performance in 2D image/video generation, diffusion-based Text-to-Multi-view-Video (T2MVid) generation remains underexplored. The new challenges posed by T2MVid generation lie in the lack of massive captioned multi-view videos and the complexity of modeling such multi-dimensional distribution. To this end, we propose a novel diffusion-based pipeline that generates high-quality multi-view videos centered around a dynamic 3D object from text. Specifically, we factor the T2MVid problem into viewpoint-space and time components. Such factorization allows us to combine and reuse layers of advanced pre-trained multi-view image and 2D video diffusion models to ensure multi-view consistency as well as temporal coherence for the generated multi-view videos, largely reducing the training cost. We further introduce alignment modules to align the latent spaces of layers from the pre-trained multi-view and the 2D video diffusion models, addressing the reused layers' incompatibility that arises from the domain gap between 2D and multi-view data. In support of this and future research, we further contribute a captioned multi-view video dataset. Experimental results demonstrate that our method generates high-quality multi-view videos, exhibiting vivid motions, temporal coherence, and multi-view consistency, given a variety of text prompts.
GES: Generalized Exponential Splatting for Efficient Radiance Field Rendering
Feb 15, 2024



Advancements in 3D Gaussian Splatting have significantly accelerated 3D reconstruction and generation. However, it may require a large number of Gaussians, which creates a substantial memory footprint. This paper introduces GES (Generalized Exponential Splatting), a novel representation that employs Generalized Exponential Function (GEF) to model 3D scenes, requiring far fewer particles to represent a scene and thus significantly outperforming Gaussian Splatting methods in efficiency with a plug-and-play replacement ability for Gaussian-based utilities. GES is validated theoretically and empirically in both principled 1D setup and realistic 3D scenes. It is shown to represent signals with sharp edges more accurately, which are typically challenging for Gaussians due to their inherent low-pass characteristics. Our empirical analysis demonstrates that GEF outperforms Gaussians in fitting natural-occurring signals (e.g. squares, triangles, and parabolic signals), thereby reducing the need for extensive splitting operations that increase the memory footprint of Gaussian Splatting. With the aid of a frequency-modulated loss, GES achieves competitive performance in novel-view synthesis benchmarks while requiring less than half the memory storage of Gaussian Splatting and increasing the rendering speed by up to 39%. The code is available on the project website https://abdullahamdi.com/ges .
Magic123: One Image to High-Quality 3D Object Generation Using Both 2D and 3D Diffusion Priors
Jun 30, 2023


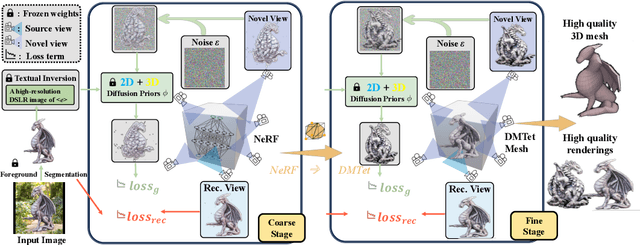
We present Magic123, a two-stage coarse-to-fine approach for high-quality, textured 3D meshes generation from a single unposed image in the wild using both2D and 3D priors. In the first stage, we optimize a neural radiance field to produce a coarse geometry. In the second stage, we adopt a memory-efficient differentiable mesh representation to yield a high-resolution mesh with a visually appealing texture. In both stages, the 3D content is learned through reference view supervision and novel views guided by a combination of 2D and 3D diffusion priors. We introduce a single trade-off parameter between the 2D and 3D priors to control exploration (more imaginative) and exploitation (more precise) of the generated geometry. Additionally, we employ textual inversion and monocular depth regularization to encourage consistent appearances across views and to prevent degenerate solutions, respectively. Magic123 demonstrates a significant improvement over previous image-to-3D techniques, as validated through extensive experiments on synthetic benchmarks and diverse real-world images. Our code, models, and generated 3D assets are available at https://github.com/guochengqian/Magic123.
Mindstorms in Natural Language-Based Societies of Mind
May 26, 2023



Both Minsky's "society of mind" and Schmidhuber's "learning to think" inspire diverse societies of large multimodal neural networks (NNs) that solve problems by interviewing each other in a "mindstorm." Recent implementations of NN-based societies of minds consist of large language models (LLMs) and other NN-based experts communicating through a natural language interface. In doing so, they overcome the limitations of single LLMs, improving multimodal zero-shot reasoning. In these natural language-based societies of mind (NLSOMs), new agents -- all communicating through the same universal symbolic language -- are easily added in a modular fashion. To demonstrate the power of NLSOMs, we assemble and experiment with several of them (having up to 129 members), leveraging mindstorms in them to solve some practical AI tasks: visual question answering, image captioning, text-to-image synthesis, 3D generation, egocentric retrieval, embodied AI, and general language-based task solving. We view this as a starting point towards much larger NLSOMs with billions of agents-some of which may be humans. And with this emergence of great societies of heterogeneous minds, many new research questions have suddenly become paramount to the future of artificial intelligence. What should be the social structure of an NLSOM? What would be the (dis)advantages of having a monarchical rather than a democratic structure? How can principles of NN economies be used to maximize the total reward of a reinforcement learning NLSOM? In this work, we identify, discuss, and try to answer some of these questions.
LLM as A Robotic Brain: Unifying Egocentric Memory and Control
Apr 27, 2023



Embodied AI focuses on the study and development of intelligent systems that possess a physical or virtual embodiment (i.e. robots) and are able to dynamically interact with their environment. Memory and control are the two essential parts of an embodied system and usually require separate frameworks to model each of them. In this paper, we propose a novel and generalizable framework called LLM-Brain: using Large-scale Language Model as a robotic brain to unify egocentric memory and control. The LLM-Brain framework integrates multiple multimodal language models for robotic tasks, utilizing a zero-shot learning approach. All components within LLM-Brain communicate using natural language in closed-loop multi-round dialogues that encompass perception, planning, control, and memory. The core of the system is an embodied LLM to maintain egocentric memory and control the robot. We demonstrate LLM-Brain by examining two downstream tasks: active exploration and embodied question answering. The active exploration tasks require the robot to extensively explore an unknown environment within a limited number of actions. Meanwhile, the embodied question answering tasks necessitate that the robot answers questions based on observations acquired during prior explorations.
Localizing Objects in 3D from Egocentric Videos with Visual Queries
Dec 14, 2022



With the recent advances in video and 3D understanding, novel 4D spatio-temporal challenges fusing both concepts have emerged. Towards this direction, the Ego4D Episodic Memory Benchmark proposed a task for Visual Queries with 3D Localization (VQ3D). Given an egocentric video clip and an image crop depicting a query object, the goal is to localize the 3D position of the center of that query object with respect to the camera pose of a query frame. Current methods tackle the problem of VQ3D by lifting the 2D localization results of the sister task Visual Queries with 2D Localization (VQ2D) into a 3D reconstruction. Yet, we point out that the low number of Queries with Poses (QwP) from previous VQ3D methods severally hinders their overall success rate and highlights the need for further effort in 3D modeling to tackle the VQ3D task. In this work, we formalize a pipeline that better entangles 3D multiview geometry with 2D object retrieval from egocentric videos. We estimate more robust camera poses, leading to more successful object queries and substantially improved VQ3D performance. In practice, our method reaches a top-1 overall success rate of 86.36% on the Ego4D Episodic Memory Benchmark VQ3D, a 10x improvement over the previous state-of-the-art. In addition, we provide a complete empirical study highlighting the remaining challenges in VQ3D.