 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Token Divergence: Measuring and Steering In-Context Computation Density
Dec 28, 2025Measuring the in-context computational effort of language models is a key challenge, as metrics like next-token loss fail to capture reasoning complexity. Prior methods based on latent state compressibility can be invasive and unstable. We propose Multiple Token Divergence (MTD), a simple measure of computational effort defined as the KL divergence between a model's full output distribution and that of a shallow, auxiliary prediction head. MTD can be computed directly from pre-trained models with multiple prediction heads, requiring no additional training. Building on this, we introduce Divergence Steering, a novel decoding method to control the computational character of generated text. We empirically show that MTD is more effective than prior methods at distinguishing complex tasks from simple ones. On mathematical reasoning benchmarks, MTD correlates positively with problem difficulty. Lower MTD is associated with more accurate reasoning. MTD provides a practical, lightweight tool for analyzing and steering the computational dynamics of language models.
Measuring In-Context Computation Complexity via Hidden State Prediction
Mar 17, 2025

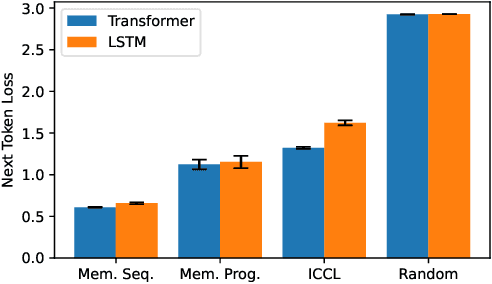

Detecting when a neural sequence model does "interesting" computation is an open problem. The next token prediction loss is a poor indicator: Low loss can stem from trivially predictable sequences that are uninteresting, while high loss may reflect unpredictable but also irrelevant information that can be ignored by the model. We propose a better metric: measuring the model's ability to predict its own future hidden states. We show empirically that this metric -- in contrast to the next token prediction loss -- correlates with the intuitive interestingness of the task. To measure predictability, we introduce the architecture-agnostic "prediction of hidden states" (PHi) layer that serves as an information bottleneck on the main pathway of the network (e.g., the residual stream in Transformers). We propose a novel learned predictive prior that enables us to measure the novel information gained in each computation step, which serves as our metric. We show empirically that our metric predicts the description length of formal languages learned in-context, the complexity of mathematical reasoning problems, and the correctness of self-generated reasoning chains.
Upside Down Reinforcement Learning with Policy Generators
Jan 27, 2025Upside Down Reinforcement Learning (UDRL) is a promising framework for solving reinforcement learning problems which focuses on learning command-conditioned policies. In this work, we extend UDRL to the task of learning a command-conditioned generator of deep neural network policies. We accomplish this using Hypernetworks - a variant of Fast Weight Programmers, which learn to decode input commands representing a desired expected return into command-specific weight matrices. Our method, dubbed Upside Down Reinforcement Learning with Policy Generators (UDRLPG), streamlines comparable techniques by removing the need for an evaluator or critic to update the weights of the generator. To counteract the increased variance in last returns caused by not having an evaluator, we decouple the sampling probability of the buffer from the absolute number of policies in it, which, together with a simple weighting strategy, improves the empirical convergence of the algorithm. Compared with existing algorithms, UDRLPG achieves competitive performance and high returns, sometimes outperforming more complex architectures. Our experiments show that a trained generator can generalize to create policies that achieve unseen returns zero-shot. The proposed method appears to be effective in mitigating some of the challenges associated with learning highly multimodal functions. Altogether, we believe that UDRLPG represents a promising step forward in achieving greater empirical sample efficiency in RL. A full implementation of UDRLPG is publicly available at https://github.com/JacopoD/udrlpg_
Automatic Album Sequencing
Nov 12, 2024

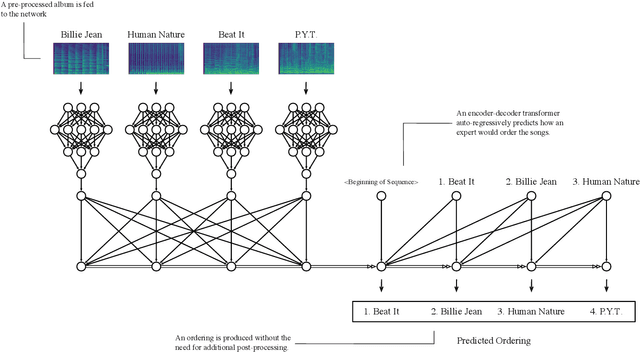
Album sequencing is a critical part of the album production process. Recently, a data-driven approach was proposed that sequences general collections of independent media by extracting the narrative essence of the items in the collections. While this approach implies an album sequencing technique, it is not widely accessible to a less technical audience, requiring advanced knowledge of machine learning techniques to use. To address this, we introduce a new user-friendly web-based tool that allows a less technical audience to upload music tracks, execute this technique in one click, and subsequently presents the result in a clean visualization to the user. To both increase the number of templates available to the user and address shortcomings of previous work, we also introduce a new direct transformer-based album sequencing method. We find that our more direct method outperforms a random baseline but does not reach the same performance as the narrative essence approach. Both methods are included in our web-based user interface, and this -- alongside a full copy of our implementation -- is publicly available at https://github.com/dylanashley/automatic-album-sequencing
Learning Useful Representations of Recurrent Neural Network Weight Matrices
Mar 18, 2024Recurrent Neural Networks (RNNs) are general-purpose parallel-sequential computers. The program of an RNN is its weight matrix. How to learn useful representations of RNN weights that facilitate RNN analysis as well as downstream tasks? While the mechanistic approach directly looks at some RNN's weights to predict its behavior, the functionalist approach analyzes its overall functionality -- specifically, its input-output mapping. We consider several mechanistic approaches for RNN weights and adapt the permutation equivariant Deep Weight Space layer for RNNs. Our two novel functionalist approaches extract information from RNN weights by 'interrogating' the RNN through probing inputs. We develop a theoretical framework that demonstrates conditions under which the functionalist approach can generate rich representations that help determine RNN behavior. We create and release the first two 'model zoo' datasets for RNN weight representation learning. One consists of generative models of a class of formal languages, and the other one of classifiers of sequentially processed MNIST digits. With the help of an emulation-based self-supervised learning technique we compare and evaluate the different RNN weight encoding techniques on multiple downstream applications. On the most challenging one, namely predicting which exact task the RNN was trained on, functionalist approaches show clear superiority.
Unsupervised Musical Object Discovery from Audio
Nov 14, 2023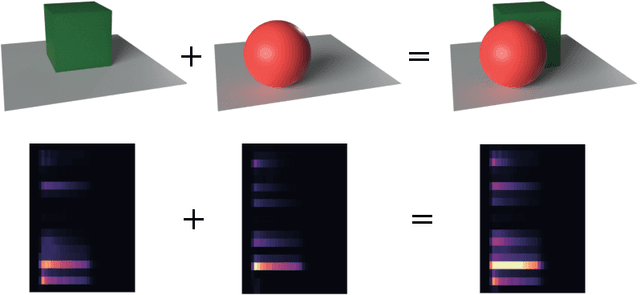

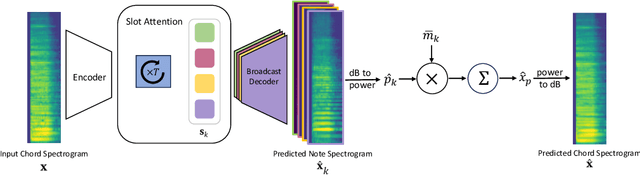
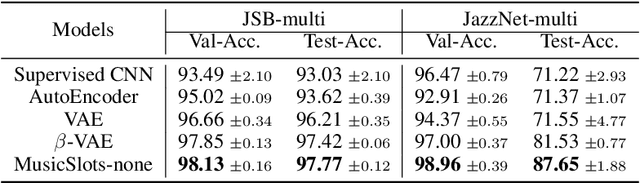
Current object-centric learning models such as the popular SlotAttention architecture allow for unsupervised visual scene decomposition. Our novel MusicSlots method adapts SlotAttention to the audio domain, to achieve unsupervised music decomposition. Since concepts of opacity and occlusion in vision have no auditory analogues, the softmax normalization of alpha masks in the decoders of visual object-centric models is not well-suited for decomposing audio objects. MusicSlots overcomes this problem. We introduce a spectrogram-based multi-object music dataset tailored to evaluate object-centric learning on western tonal music. MusicSlots achieves good performance on unsupervised note discovery and outperforms several established baselines on supervised note property prediction tasks.
Mindstorms in Natural Language-Based Societies of Mind
May 26, 2023



Both Minsky's "society of mind" and Schmidhuber's "learning to think" inspire diverse societies of large multimodal neural networks (NNs) that solve problems by interviewing each other in a "mindstorm." Recent implementations of NN-based societies of minds consist of large language models (LLMs) and other NN-based experts communicating through a natural language interface. In doing so, they overcome the limitations of single LLMs, improving multimodal zero-shot reasoning. In these natural language-based societies of mind (NLSOMs), new agents -- all communicating through the same universal symbolic language -- are easily added in a modular fashion. To demonstrate the power of NLSOMs, we assemble and experiment with several of them (having up to 129 members), leveraging mindstorms in them to solve some practical AI tasks: visual question answering, image captioning, text-to-image synthesis, 3D generation, egocentric retrieval, embodied AI, and general language-based task solving. We view this as a starting point towards much larger NLSOMs with billions of agents-some of which may be humans. And with this emergence of great societies of heterogeneous minds, many new research questions have suddenly become paramount to the future of artificial intelligence. What should be the social structure of an NLSOM? What would be the (dis)advantages of having a monarchical rather than a democratic structure? How can principles of NN economies be used to maximize the total reward of a reinforcement learning NLSOM? In this work, we identify, discuss, and try to answer some of these questions.
Learning One Abstract Bit at a Time Through Self-Invented Experiments Encoded as Neural Networks
Dec 29, 2022



There are two important things in science: (A) Finding answers to given questions, and (B) Coming up with good questions. Our artificial scientists not only learn to answer given questions, but also continually invent new questions, by proposing hypotheses to be verified or falsified through potentially complex and time-consuming experiments, including thought experiments akin to those of mathematicians. While an artificial scientist expands its knowledge, it remains biased towards the simplest, least costly experiments that still have surprising outcomes, until they become boring. We present an empirical analysis of the automatic generation of interesting experiments. In the first setting, we investigate self-invented experiments in a reinforcement-providing environment and show that they lead to effective exploration. In the second setting, pure thought experiments are implemented as the weights of recurrent neural networks generated by a neural experiment generator. Initially interesting thought experiments may become boring over time.
On Narrative Information and the Distillation of Stories
Nov 22, 2022



The act of telling stories is a fundamental part of what it means to be human. This work introduces the concept of narrative information, which we define to be the overlap in information space between a story and the items that compose the story. Using contrastive learning methods, we show how modern artificial neural networks can be leveraged to distill stories and extract a representation of the narrative information. We then demonstrate how evolutionary algorithms can leverage this to extract a set of narrative templates and how these templates -- in tandem with a novel curve-fitting algorithm we introduce -- can reorder music albums to automatically induce stories in them. In the process of doing so, we give strong statistical evidence that these narrative information templates are present in existing albums. While we experiment only with music albums here, the premises of our work extend to any form of (largely) independent media.
Goal-Conditioned Generators of Deep Policies
Jul 04, 2022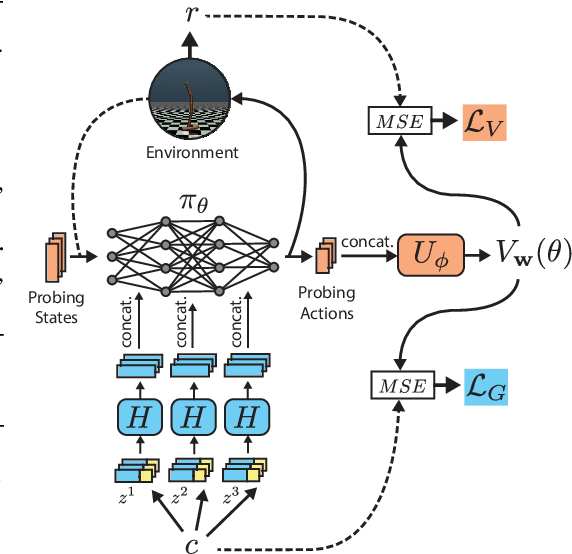

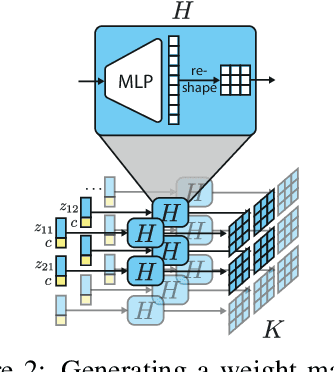
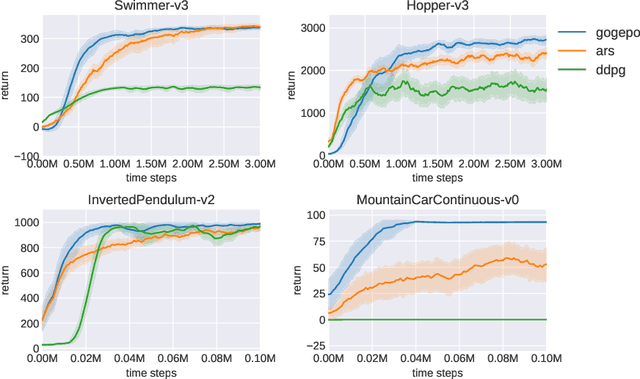
Goal-conditioned Reinforcement Learning (RL) aims at learning optimal policies, given goals encoded in special command inputs. Here we study goal-conditioned neural nets (NNs) that learn to generate deep NN policies in form of context-specific weight matrices, similar to Fast Weight Programmers and other methods from the 1990s. Using context commands of the form "generate a policy that achieves a desired expected return," our NN generators combine powerful exploration of parameter space with generalization across commands to iteratively find better and better policies. A form of weight-sharing HyperNetworks and policy embeddings scales our method to generate deep NNs. Experiments show how a single learned policy generator can produce policies that achieve any return seen during training. Finally, we evaluate our algorithm on a set of continuous control tasks where it exhibits competitive performance. Our code is public.