 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Narrative Information and the Distillation of Stories
Nov 22, 2022



The act of telling stories is a fundamental part of what it means to be human. This work introduces the concept of narrative information, which we define to be the overlap in information space between a story and the items that compose the story. Using contrastive learning methods, we show how modern artificial neural networks can be leveraged to distill stories and extract a representation of the narrative information. We then demonstrate how evolutionary algorithms can leverage this to extract a set of narrative templates and how these templates -- in tandem with a novel curve-fitting algorithm we introduce -- can reorder music albums to automatically induce stories in them. In the process of doing so, we give strong statistical evidence that these narrative information templates are present in existing albums. While we experiment only with music albums here, the premises of our work extend to any form of (largely) independent media.
Automatic Embedding of Stories Into Collections of Independent Media
Nov 03, 2021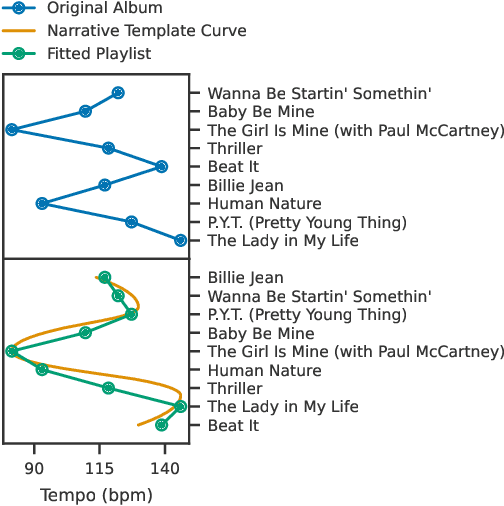
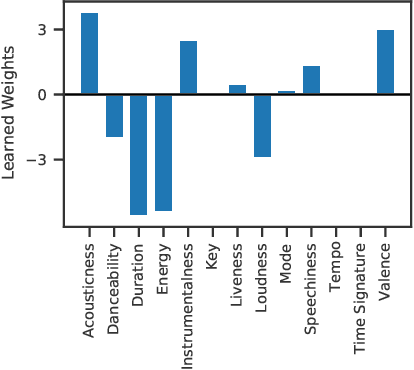

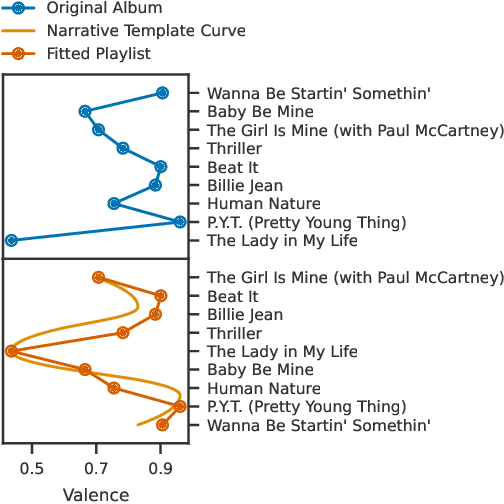
We look at how machine learning techniques that derive properties of items in a collection of independent media can be used to automatically embed stories into such collections. To do so, we use models that extract the tempo of songs to make a music playlist follow a narrative arc. Our work specifies an open-source tool that uses pre-trained neural network models to extract the global tempo of a set of raw audio files and applies these measures to create a narrative-following playlist. This tool is available at https://github.com/dylanashley/playlist-story-builder/releases/tag/v1.0.0
Local Search Yields a PTAS for k-Means in Doubling Metrics
Jan 09, 2017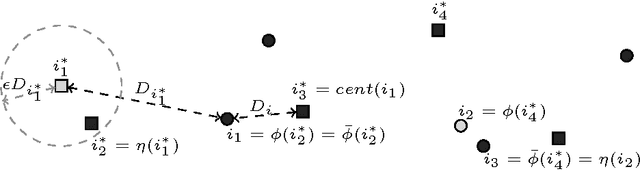



The most well known and ubiquitous clustering problem encountered in nearly every branch of science is undoubtedly $k$-means: given a set of data points and a parameter $k$, select $k$ centres and partition the data points into $k$ clusters around these centres so that the sum of squares of distances of the points to their cluster centre is minimized. Typically these data points lie $\mathbb{R}^d$ for some $d\geq 2$. $k$-means and the first algorithms for it were introduced in the 1950's. Since then, hundreds of papers have studied this problem and many algorithms have been proposed for it. The most commonly used algorithm is known as Lloyd-Forgy, which is also referred to as "the" $k$-means algorithm, and various extensions of it often work very well in practice. However, they may produce solutions whose cost is arbitrarily large compared to the optimum solution. Kanungo et al. [2004] analyzed a simple local search heuristic to get a polynomial-time algorithm with approximation ratio $9+\epsilon$ for any fixed $\epsilon>0$ for $k$-means in Euclidean space. Finding an algorithm with a better approximation guarantee has remained one of the biggest open questions in this area, in particular whether one can get a true PTAS for fixed dimension Euclidean space. We settle this problem by showing that a simple local search algorithm provides a PTAS for $k$-means in $\mathbb{R}^d$ for any fixed $d$. More precisely, for any error parameter $\epsilon>0$, the local search algorithm that considers swaps of up to $\rho=d^{O(d)}\cdot{\epsilon}^{-O(d/\epsilon)}$ centres at a time finds a solution using exactly $k$ centres whose cost is at most a $(1+\epsilon)$-factor greater than the optimum. Finally, we provide the first demonstration that local search yields a PTAS for the uncapacitated facility location problem and $k$-median with non-uniform opening costs in doubling metrics.