 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Convergence and Stability of Upside-Down Reinforcement Learning, Goal-Conditioned Supervised Learning, and Online Decision Transformers
Feb 08, 2025This article provides a rigorous analysis of convergence and stability of Episodic Upside-Down Reinforcement Learning, Goal-Conditioned Supervised Learning and Online Decision Transformers. These algorithms performed competitively across various benchmarks, from games to robotic tasks, but their theoretical understanding is limited to specific environmental conditions. This work initiates a theoretical foundation for algorithms that build on the broad paradigm of approaching reinforcement learning through supervised learning or sequence modeling. At the core of this investigation lies the analysis of conditions on the underlying environment, under which the algorithms can identify optimal solutions. We also assess whether emerging solutions remain stable in situations where the environment is subject to tiny levels of noise. Specifically, we study the continuity and asymptotic convergence of command-conditioned policies, values and the goal-reaching objective depending on the transition kernel of the underlying Markov Decision Process. We demonstrate that near-optimal behavior is achieved if the transition kernel is located in a sufficiently small neighborhood of a deterministic kernel. The mentioned quantities are continuous (with respect to a specific topology) at deterministic kernels, both asymptotically and after a finite number of learning cycles. The developed methods allow us to present the first explicit estimates on the convergence and stability of policies and values in terms of the underlying transition kernels. On the theoretical side we introduce a number of new concepts to reinforcement learning, like working in segment spaces, studying continuity in quotient topologies and the application of the fixed-point theory of dynamical systems. The theoretical study is accompanied by a detailed investigation of example environments and numerical experiments.
Upside Down Reinforcement Learning with Policy Generators
Jan 27, 2025Upside Down Reinforcement Learning (UDRL) is a promising framework for solving reinforcement learning problems which focuses on learning command-conditioned policies. In this work, we extend UDRL to the task of learning a command-conditioned generator of deep neural network policies. We accomplish this using Hypernetworks - a variant of Fast Weight Programmers, which learn to decode input commands representing a desired expected return into command-specific weight matrices. Our method, dubbed Upside Down Reinforcement Learning with Policy Generators (UDRLPG), streamlines comparable techniques by removing the need for an evaluator or critic to update the weights of the generator. To counteract the increased variance in last returns caused by not having an evaluator, we decouple the sampling probability of the buffer from the absolute number of policies in it, which, together with a simple weighting strategy, improves the empirical convergence of the algorithm. Compared with existing algorithms, UDRLPG achieves competitive performance and high returns, sometimes outperforming more complex architectures. Our experiments show that a trained generator can generalize to create policies that achieve unseen returns zero-shot. The proposed method appears to be effective in mitigating some of the challenges associated with learning highly multimodal functions. Altogether, we believe that UDRLPG represents a promising step forward in achieving greater empirical sample efficiency in RL. A full implementation of UDRLPG is publicly available at https://github.com/JacopoD/udrlpg_
How to Correctly do Semantic Backpropagation on Language-based Agentic Systems
Dec 04, 2024Language-based agentic systems have shown great promise in recent years, transitioning from solving small-scale research problems to being deployed in challenging real-world tasks. However, optimizing these systems often requires substantial manual labor. Recent studies have demonstrated that these systems can be represented as computational graphs, enabling automatic optimization. Despite these advancements, most current efforts in Graph-based Agentic System Optimization (GASO) fail to properly assign feedback to the system's components given feedback on the system's output. To address this challenge, we formalize the concept of semantic backpropagation with semantic gradients -- a generalization that aligns several key optimization techniques, including reverse-mode automatic differentiation and the more recent TextGrad by exploiting the relationship among nodes with a common successor. This serves as a method for computing directional information about how changes to each component of an agentic system might improve the system's output. To use these gradients, we propose a method called semantic gradient descent which enables us to solve GASO effectively. Our results on both BIG-Bench Hard and GSM8K show that our approach outperforms existing state-of-the-art methods for solving GASO problems. A detailed ablation study on the LIAR dataset demonstrates the parsimonious nature of our method. A full copy of our implementation is publicly available at https://github.com/HishamAlyahya/semantic_backprop
Automatic Album Sequencing
Nov 12, 2024

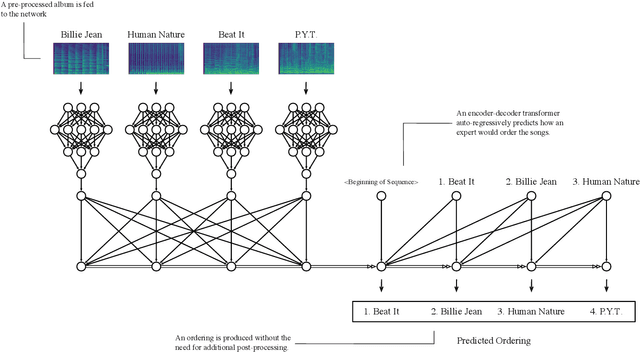
Album sequencing is a critical part of the album production process. Recently, a data-driven approach was proposed that sequences general collections of independent media by extracting the narrative essence of the items in the collections. While this approach implies an album sequencing technique, it is not widely accessible to a less technical audience, requiring advanced knowledge of machine learning techniques to use. To address this, we introduce a new user-friendly web-based tool that allows a less technical audience to upload music tracks, execute this technique in one click, and subsequently presents the result in a clean visualization to the user. To both increase the number of templates available to the user and address shortcomings of previous work, we also introduce a new direct transformer-based album sequencing method. We find that our more direct method outperforms a random baseline but does not reach the same performance as the narrative essence approach. Both methods are included in our web-based user interface, and this -- alongside a full copy of our implementation -- is publicly available at https://github.com/dylanashley/automatic-album-sequencing
Scaling Value Iteration Networks to 5000 Layers for Extreme Long-Term Planning
Jun 12, 2024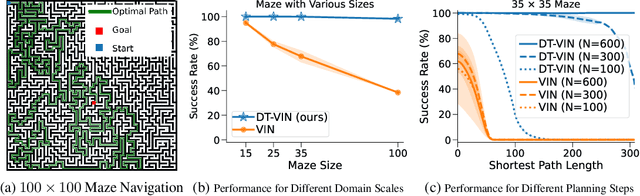

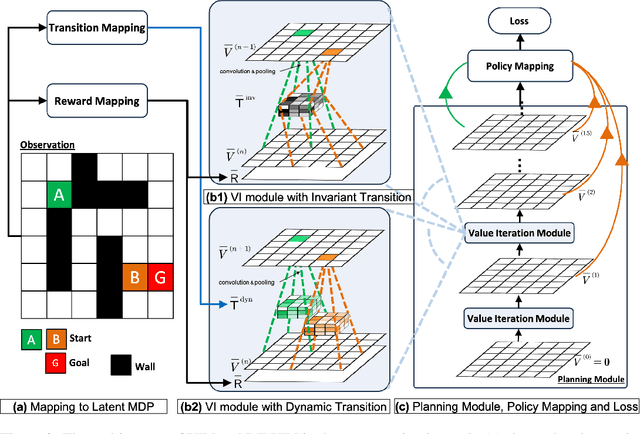

The Value Iteration Network (VIN) is an end-to-end differentiable architecture that performs value iteration on a latent MDP for planning in reinforcement learning (RL). However, VINs struggle to scale to long-term and large-scale planning tasks, such as navigating a $100\times 100$ maze -- a task which typically requires thousands of planning steps to solve. We observe that this deficiency is due to two issues: the representation capacity of the latent MDP and the planning module's depth. We address these by augmenting the latent MDP with a dynamic transition kernel, dramatically improving its representational capacity, and, to mitigate the vanishing gradient problem, introducing an "adaptive highway loss" that constructs skip connections to improve gradient flow. We evaluate our method on both 2D maze navigation environments and the ViZDoom 3D navigation benchmark. We find that our new method, named Dynamic Transition VIN (DT-VIN), easily scales to 5000 layers and casually solves challenging versions of the above tasks. Altogether, we believe that DT-VIN represents a concrete step forward in performing long-term large-scale planning in RL environments.
Towards a Robust Soft Baby Robot With Rich Interaction Ability for Advanced Machine Learning Algorithms
Apr 11, 2024Artificial intelligence has made great strides in many areas lately, yet it has had comparatively little success in general-use robotics. We believe one of the reasons for this is the disconnect between traditional robotic design and the properties needed for open-ended, creativity-based AI systems. To that end, we, taking selective inspiration from nature, build a robust, partially soft robotic limb with a large action space, rich sensory data stream from multiple cameras, and the ability to connect with others to enhance the action space and data stream. As a proof of concept, we train two contemporary machine learning algorithms to perform a simple target-finding task. Altogether, we believe that this design serves as a first step to building a robot tailor-made for achieving artificial general intelligence.
Mindstorms in Natural Language-Based Societies of Mind
May 26, 2023



Both Minsky's "society of mind" and Schmidhuber's "learning to think" inspire diverse societies of large multimodal neural networks (NNs) that solve problems by interviewing each other in a "mindstorm." Recent implementations of NN-based societies of minds consist of large language models (LLMs) and other NN-based experts communicating through a natural language interface. In doing so, they overcome the limitations of single LLMs, improving multimodal zero-shot reasoning. In these natural language-based societies of mind (NLSOMs), new agents -- all communicating through the same universal symbolic language -- are easily added in a modular fashion. To demonstrate the power of NLSOMs, we assemble and experiment with several of them (having up to 129 members), leveraging mindstorms in them to solve some practical AI tasks: visual question answering, image captioning, text-to-image synthesis, 3D generation, egocentric retrieval, embodied AI, and general language-based task solving. We view this as a starting point towards much larger NLSOMs with billions of agents-some of which may be humans. And with this emergence of great societies of heterogeneous minds, many new research questions have suddenly become paramount to the future of artificial intelligence. What should be the social structure of an NLSOM? What would be the (dis)advantages of having a monarchical rather than a democratic structure? How can principles of NN economies be used to maximize the total reward of a reinforcement learning NLSOM? In this work, we identify, discuss, and try to answer some of these questions.
On Narrative Information and the Distillation of Stories
Nov 22, 2022



The act of telling stories is a fundamental part of what it means to be human. This work introduces the concept of narrative information, which we define to be the overlap in information space between a story and the items that compose the story. Using contrastive learning methods, we show how modern artificial neural networks can be leveraged to distill stories and extract a representation of the narrative information. We then demonstrate how evolutionary algorithms can leverage this to extract a set of narrative templates and how these templates -- in tandem with a novel curve-fitting algorithm we introduce -- can reorder music albums to automatically induce stories in them. In the process of doing so, we give strong statistical evidence that these narrative information templates are present in existing albums. While we experiment only with music albums here, the premises of our work extend to any form of (largely) independent media.
Upside-Down Reinforcement Learning Can Diverge in Stochastic Environments With Episodic Resets
May 13, 2022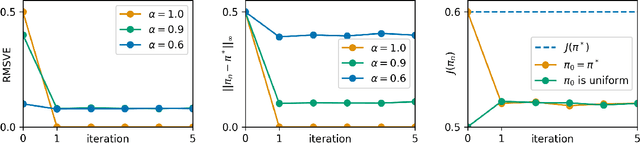
Upside-Down Reinforcement Learning (UDRL) is an approach for solving RL problems that does not require value functions and uses only supervised learning, where the targets for given inputs in a dataset do not change over time. Ghosh et al. proved that Goal-Conditional Supervised Learning (GCSL) -- which can be viewed as a simplified version of UDRL -- optimizes a lower bound on goal-reaching performance. This raises expectations that such algorithms may enjoy guaranteed convergence to the optimal policy in arbitrary environments, similar to certain well-known traditional RL algorithms. Here we show that for a specific episodic UDRL algorithm (eUDRL, including GCSL), this is not the case, and give the causes of this limitation. To do so, we first introduce a helpful rewrite of eUDRL as a recursive policy update. This formulation helps to disprove its convergence to the optimal policy for a wide class of stochastic environments. Finally, we provide a concrete example of a very simple environment where eUDRL diverges. Since the primary aim of this paper is to present a negative result, and the best counterexamples are the simplest ones, we restrict all discussions to finite (discrete) environments, ignoring issues of function approximation and limited sample size.
All You Need Is Supervised Learning: From Imitation Learning to Meta-RL With Upside Down RL
Feb 24, 2022
Upside down reinforcement learning (UDRL) flips the conventional use of the return in the objective function in RL upside down, by taking returns as input and predicting actions. UDRL is based purely on supervised learning, and bypasses some prominent issues in RL: bootstrapping, off-policy corrections, and discount factors. While previous work with UDRL demonstrated it in a traditional online RL setting, here we show that this single algorithm can also work in the imitation learning and offline RL settings, be extended to the goal-conditioned RL setting, and even the meta-RL setting. With a general agent architecture, a single UDRL agent can learn across all paradigms.