 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColon-Bench: An Agentic Workflow for Scalable Dense Lesion Annotation in Full-Procedure Colonoscopy Videos
Mar 26, 2026Early screening via colonoscopy is critical for colon cancer prevention, yet developing robust AI systems for this domain is hindered by the lack of densely annotated, long-sequence video datasets. Existing datasets predominantly focus on single-class polyp detection and lack the rich spatial, temporal, and linguistic annotations required to evaluate modern Multimodal Large Language Models (MLLMs). To address this critical gap, we introduce Colon-Bench, generated via a novel multi-stage agentic workflow. Our pipeline seamlessly integrates temporal proposals, bounding-box tracking, AI-driven visual confirmation, and human-in-the-loop review to scalably annotate full-procedure videos. The resulting verified benchmark is unprecedented in scope, encompassing 528 videos, 14 distinct lesion categories (including polyps, ulcers, and bleeding), over 300,000 bounding boxes, 213,000 segmentation masks, and 133,000 words of clinical descriptions. We utilize Colon-Bench to rigorously evaluate state-of-the-art MLLMs across lesion classification, Open-Vocabulary Video Object Segmentation (OV-VOS), and video Visual Question Answering (VQA). The MLLM results demonstrate surprisingly high localization performance in medical domains compared to SAM-3. Finally, we analyze common VQA errors from MLLMs to introduce a novel "colon-skill" prompting strategy, improving zero-shot MLLM performance by up to 9.7% across most MLLMs. The dataset and the code are available at https://abdullahamdi.com/colon-bench .
Triangle Splatting for Real-Time Radiance Field Rendering
May 25, 2025



The field of computer graphics was revolutionized by models such as Neural Radiance Fields and 3D Gaussian Splatting, displacing triangles as the dominant representation for photogrammetry. In this paper, we argue for a triangle comeback. We develop a differentiable renderer that directly optimizes triangles via end-to-end gradients. We achieve this by rendering each triangle as differentiable splats, combining the efficiency of triangles with the adaptive density of representations based on independent primitives. Compared to popular 2D and 3D Gaussian Splatting methods, our approach achieves higher visual fidelity, faster convergence, and increased rendering throughput. On the Mip-NeRF360 dataset, our method outperforms concurrent non-volumetric primitives in visual fidelity and achieves higher perceptual quality than the state-of-the-art Zip-NeRF on indoor scenes. Triangles are simple, compatible with standard graphics stacks and GPU hardware, and highly efficient: for the \textit{Garden} scene, we achieve over 2,400 FPS at 1280x720 resolution using an off-the-shelf mesh renderer. These results highlight the efficiency and effectiveness of triangle-based representations for high-quality novel view synthesis. Triangles bring us closer to mesh-based optimization by combining classical computer graphics with modern differentiable rendering frameworks. The project page is https://trianglesplatting.github.io/
UKBOB: One Billion MRI Labeled Masks for Generalizable 3D Medical Image Segmentation
Apr 09, 2025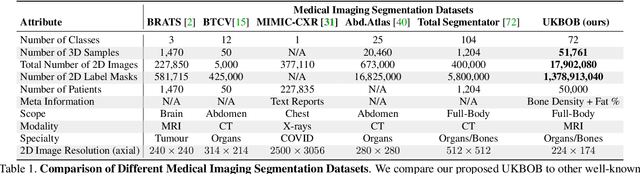
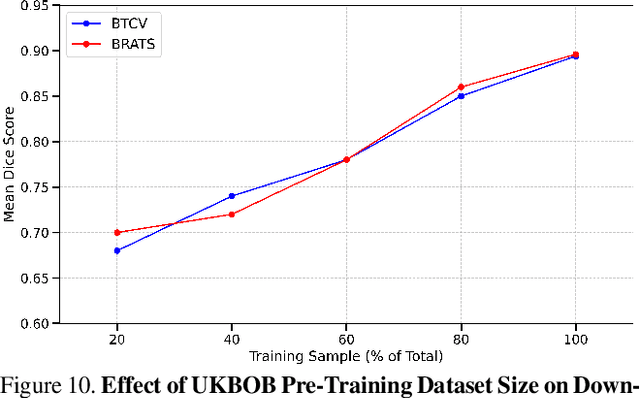
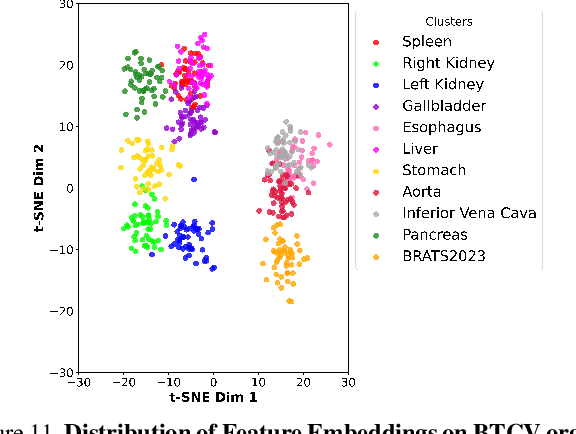
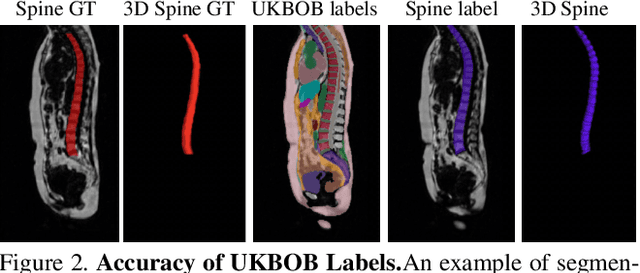
In medical imaging, the primary challenge is collecting large-scale labeled data due to privacy concerns, logistics, and high labeling costs. In this work, we present the UK Biobank Organs and Bones (UKBOB), the largest labeled dataset of body organs, comprising 51,761 MRI 3D samples (equivalent to 17.9 million 2D images) and more than 1.37 billion 2D segmentation masks of 72 organs, all based on the UK Biobank MRI dataset. We utilize automatic labeling, introduce an automated label cleaning pipeline with organ-specific filters, and manually annotate a subset of 300 MRIs with 11 abdominal classes to validate the quality (referred to as UKBOB-manual). This approach allows for scaling up the dataset collection while maintaining confidence in the labels. We further confirm the validity of the labels by demonstrating zero-shot generalization of trained models on the filtered UKBOB to other small labeled datasets from similar domains (e.g., abdominal MRI). To further mitigate the effect of noisy labels, we propose a novel method called Entropy Test-time Adaptation (ETTA) to refine the segmentation output. We use UKBOB to train a foundation model, Swin-BOB, for 3D medical image segmentation based on the Swin-UNetr architecture, achieving state-of-the-art results in several benchmarks in 3D medical imaging, including the BRATS brain MRI tumor challenge (with a 0.4% improvement) and the BTCV abdominal CT scan benchmark (with a 1.3% improvement). The pre-trained models and the code are available at https://emmanuelleb985.github.io/ukbob , and the filtered labels will be made available with the UK Biobank.
ZeroKey: Point-Level Reasoning and Zero-Shot 3D Keypoint Detection from Large Language Models
Dec 09, 2024



We propose a novel zero-shot approach for keypoint detection on 3D shapes. Point-level reasoning on visual data is challenging as it requires precise localization capability, posing problems even for powerful models like DINO or CLIP. Traditional methods for 3D keypoint detection rely heavily on annotated 3D datasets and extensive supervised training, limiting their scalability and applicability to new categories or domains. In contrast, our method utilizes the rich knowledge embedded within Multi-Modal Large Language Models (MLLMs). Specifically, we demonstrate, for the first time, that pixel-level annotations used to train recent MLLMs can be exploited for both extracting and naming salient keypoints on 3D models without any ground truth labels or supervision. Experimental evaluations demonstrate that our approach achieves competitive performance on standard benchmarks compared to supervised methods, despite not requiring any 3D keypoint annotations during training. Our results highlight the potential of integrating language models for localized 3D shape understanding. This work opens new avenues for cross-modal learning and underscores the effectiveness of MLLMs in contributing to 3D computer vision challenges.
3D Convex Splatting: Radiance Field Rendering with 3D Smooth Convexes
Nov 26, 2024


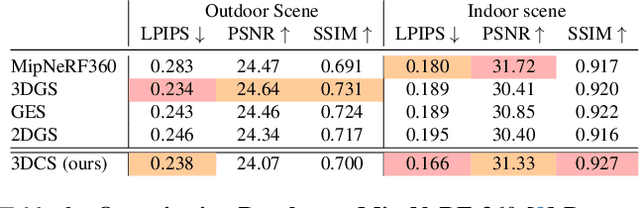
Recent advances in radiance field reconstruction, such as 3D Gaussian Splatting (3DGS), have achieved high-quality novel view synthesis and fast rendering by representing scenes with compositions of Gaussian primitives. However, 3D Gaussians present several limitations for scene reconstruction. Accurately capturing hard edges is challenging without significantly increasing the number of Gaussians, creating a large memory footprint. Moreover, they struggle to represent flat surfaces, as they are diffused in space. Without hand-crafted regularizers, they tend to disperse irregularly around the actual surface. To circumvent these issues, we introduce a novel method, named 3D Convex Splatting (3DCS), which leverages 3D smooth convexes as primitives for modeling geometrically-meaningful radiance fields from multi-view images. Smooth convex shapes offer greater flexibility than Gaussians, allowing for a better representation of 3D scenes with hard edges and dense volumes using fewer primitives. Powered by our efficient CUDA-based rasterizer, 3DCS achieves superior performance over 3DGS on benchmarks such as Mip-NeRF360, Tanks and Temples, and Deep Blending. Specifically, our method attains an improvement of up to 0.81 in PSNR and 0.026 in LPIPS compared to 3DGS while maintaining high rendering speeds and reducing the number of required primitives. Our results highlight the potential of 3D Convex Splatting to become the new standard for high-quality scene reconstruction and novel view synthesis. Project page: convexsplatting.github.io.
GST: Precise 3D Human Body from a Single Image with Gaussian Splatting Transformers
Sep 06, 2024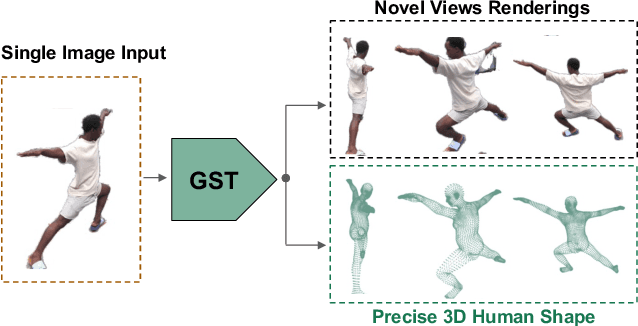
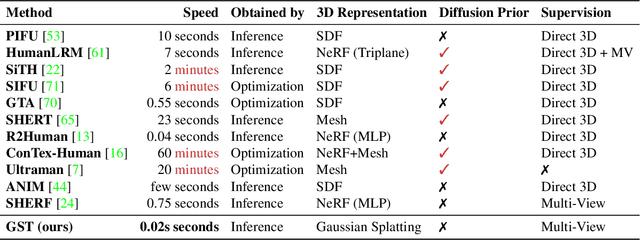
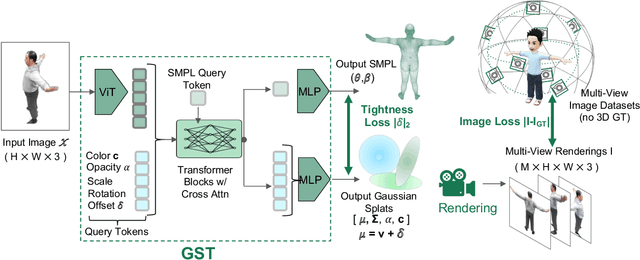
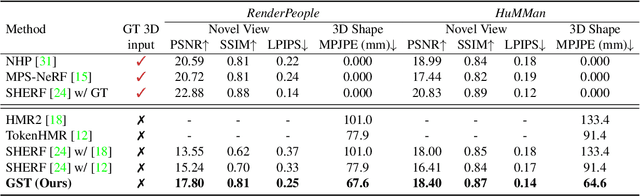
Reconstructing realistic 3D human models from monocular images has significant applications in creative industries, human-computer interfaces, and healthcare. We base our work on 3D Gaussian Splatting (3DGS), a scene representation composed of a mixture of Gaussians. Predicting such mixtures for a human from a single input image is challenging, as it is a non-uniform density (with a many-to-one relationship with input pixels) with strict physical constraints. At the same time, it needs to be flexible to accommodate a variety of clothes and poses. Our key observation is that the vertices of standardized human meshes (such as SMPL) can provide an adequate density and approximate initial position for Gaussians. We can then train a transformer model to jointly predict comparatively small adjustments to these positions, as well as the other Gaussians' attributes and the SMPL parameters. We show empirically that this combination (using only multi-view supervision) can achieve fast inference of 3D human models from a single image without test-time optimization, expensive diffusion models, or 3D points supervision. We also show that it can improve 3D pose estimation by better fitting human models that account for clothes and other variations. The code is available on the project website https://abdullahamdi.com/gst/ .
TrackNeRF: Bundle Adjusting NeRF from Sparse and Noisy Views via Feature Tracks
Aug 20, 2024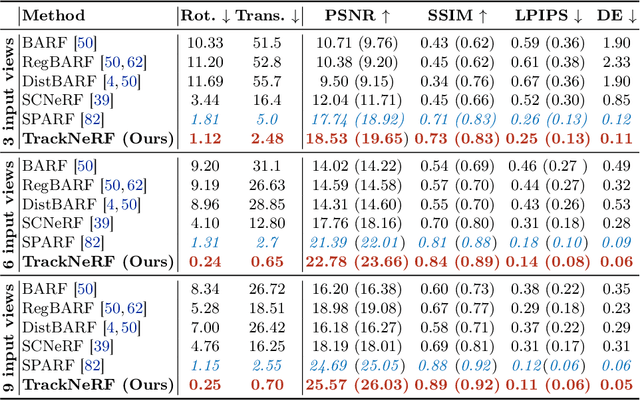
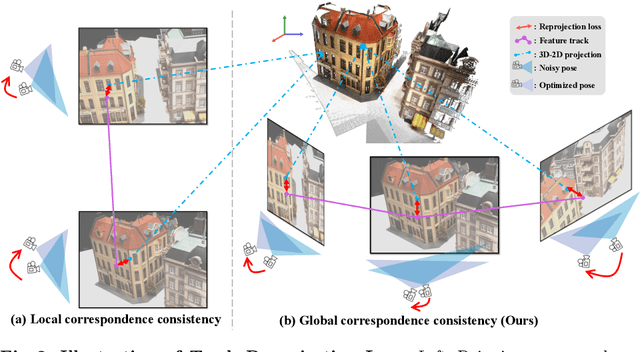
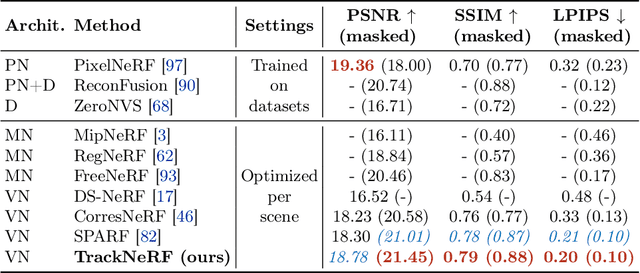

Neural radiance fields (NeRFs) generally require many images with accurate poses for accurate novel view synthesis, which does not reflect realistic setups where views can be sparse and poses can be noisy. Previous solutions for learning NeRFs with sparse views and noisy poses only consider local geometry consistency with pairs of views. Closely following \textit{bundle adjustment} in Structure-from-Motion (SfM), we introduce TrackNeRF for more globally consistent geometry reconstruction and more accurate pose optimization. TrackNeRF introduces \textit{feature tracks}, \ie connected pixel trajectories across \textit{all} visible views that correspond to the \textit{same} 3D points. By enforcing reprojection consistency among feature tracks, TrackNeRF encourages holistic 3D consistency explicitly. Through extensive experiments, TrackNeRF sets a new benchmark in noisy and sparse view reconstruction. In particular, TrackNeRF shows significant improvements over the state-of-the-art BARF and SPARF by $\sim8$ and $\sim1$ in terms of PSNR on DTU under various sparse and noisy view setups. The code is available at \href{https://tracknerf.github.io/}.
Towards AI-Powered Video Assistant Referee System (VARS) for Association Football
Jul 18, 2024Over the past decade, the technology used by referees in football has improved substantially, enhancing the fairness and accuracy of decisions. This progress has culminated in the implementation of the Video Assistant Referee (VAR), an innovation that enables backstage referees to review incidents on the pitch from multiple points of view. However, the VAR is currently limited to professional leagues due to its expensive infrastructure and the lack of referees worldwide. In this paper, we present the semi-automated Video Assistant Referee System (VARS) that leverages the latest findings in multi-view video analysis. VARS sets a new state-of-the-art on the SoccerNet-MVFoul dataset, a multi-view video dataset of football fouls. Our VARS achieves a new state-of-the-art on the SoccerNet-MVFoul dataset by recognizing the type of foul in 50% of instances and the appropriate sanction in 46% of cases. Finally, we conducted a comparative study to investigate human performance in classifying fouls and their corresponding severity and compared these findings to our VARS. The results of our study highlight the potential of our VARS to reach human performance and support football refereeing across all levels of professional and amateur federations.
Hybrid Structure-from-Motion and Camera Relocalization for Enhanced Egocentric Localization
Jul 10, 2024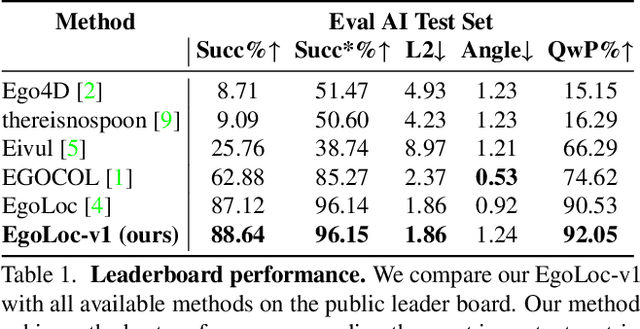
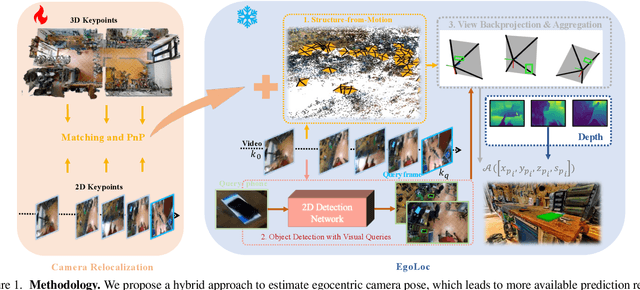
We built our pipeline EgoLoc-v1, mainly inspired by EgoLoc. We propose a model ensemble strategy to improve the camera pose estimation part of the VQ3D task, which has been proven to be essential in previous work. The core idea is not only to do SfM for egocentric videos but also to do 2D-3D matching between existing 3D scans and 2D video frames. In this way, we have a hybrid SfM and camera relocalization pipeline, which can provide us with more camera poses, leading to higher QwP and overall success rate. Our method achieves the best performance regarding the most important metric, the overall success rate. We surpass previous state-of-the-art, the competitive EgoLoc, by $1.5\%$. The code is available at \url{https://github.com/Wayne-Mai/egoloc_v1}.
X-Diffusion: Generating Detailed 3D MRI Volumes From a Single Image Using Cross-Sectional Diffusion Models
Apr 30, 2024



In this work, we present X-Diffusion, a cross-sectional diffusion model tailored for Magnetic Resonance Imaging (MRI) data. X-Diffusion is capable of generating the entire MRI volume from just a single MRI slice or optionally from few multiple slices, setting new benchmarks in the precision of synthesized MRIs from extremely sparse observations. The uniqueness lies in the novel view-conditional training and inference of X-Diffusion on MRI volumes, allowing for generalized MRI learning. Our evaluations span both brain tumour MRIs from the BRATS dataset and full-body MRIs from the UK Biobank dataset. Utilizing the paired pre-registered Dual-energy X-ray Absorptiometry (DXA) and MRI modalities in the UK Biobank dataset, X-Diffusion is able to generate detailed 3D MRI volume from a single full-body DXA. Remarkably, the resultant MRIs not only stand out in precision on unseen examples (surpassing state-of-the-art results by large margins) but also flawlessly retain essential features of the original MRI, including tumour profiles, spine curvature, brain volume, and beyond. Furthermore, the trained X-Diffusion model on the MRI datasets attains a generalization capacity out-of-domain (e.g. generating knee MRIs even though it is trained on brains). The code is available on the project website https://emmanuelleb985.github.io/XDiffusion/ .