 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2Loc++: Generalizing 3D Point Cloud Localization from Natural Language
Nov 19, 2025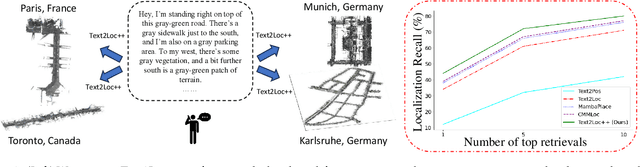
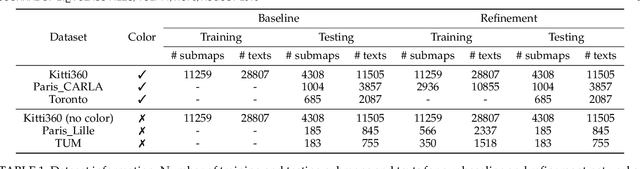


We tackle the problem of localizing 3D point cloud submaps using complex and diverse natural language descriptions, and present Text2Loc++, a novel neural network designed for effective cross-modal alignment between language and point clouds in a coarse-to-fine localization pipeline. To support benchmarking, we introduce a new city-scale dataset covering both color and non-color point clouds from diverse urban scenes, and organize location descriptions into three levels of linguistic complexity. In the global place recognition stage, Text2Loc++ combines a pretrained language model with a Hierarchical Transformer with Max pooling (HTM) for sentence-level semantics, and employs an attention-based point cloud encoder for spatial understanding. We further propose Masked Instance Training (MIT) to filter out non-aligned objects and improve multimodal robustness. To enhance the embedding space, we introduce Modality-aware Hierarchical Contrastive Learning (MHCL), incorporating cross-modal, submap-, text-, and instance-level losses. In the fine localization stage, we completely remove explicit text-instance matching and design a lightweight yet powerful framework based on Prototype-based Map Cloning (PMC) and a Cascaded Cross-Attention Transformer (CCAT). Extensive experiments on the KITTI360Pose dataset show that Text2Loc++ outperforms existing methods by up to 15%. In addition, the proposed model exhibits robust generalization when evaluated on the new dataset, effectively handling complex linguistic expressions and a wide variety of urban environments. The code and dataset will be made publicly available.
CRAM: Large-scale Video Continual Learning with Bootstrapped Compression
Aug 07, 2025Continual learning (CL) promises to allow neural networks to learn from continuous streams of inputs, instead of IID (independent and identically distributed) sampling, which requires random access to a full dataset. This would allow for much smaller storage requirements and self-sufficiency of deployed systems that cope with natural distribution shifts, similarly to biological learning. We focus on video CL employing a rehearsal-based approach, which reinforces past samples from a memory buffer. We posit that part of the reason why practical video CL is challenging is the high memory requirements of video, further exacerbated by long-videos and continual streams, which are at odds with the common rehearsal-buffer size constraints. To address this, we propose to use compressed vision, i.e. store video codes (embeddings) instead of raw inputs, and train a video classifier by IID sampling from this rolling buffer. Training a video compressor online (so not depending on any pre-trained networks) means that it is also subject to catastrophic forgetting. We propose a scheme to deal with this forgetting by refreshing video codes, which requires careful decompression with a previous version of the network and recompression with a new one. We name our method Continually Refreshed Amodal Memory (CRAM). We expand current video CL benchmarks to large-scale settings, namely EpicKitchens-100 and Kinetics-700, storing thousands of relatively long videos in under 2 GB, and demonstrate empirically that our video CL method outperforms prior art with a significantly reduced memory footprint.
GST: Precise 3D Human Body from a Single Image with Gaussian Splatting Transformers
Sep 06, 2024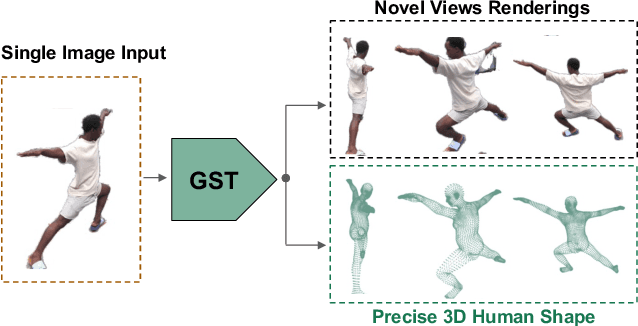
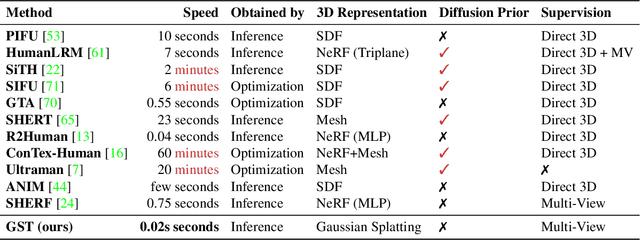
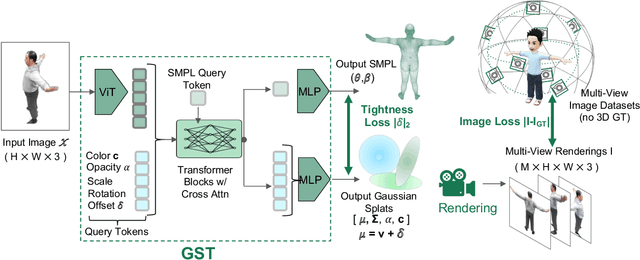
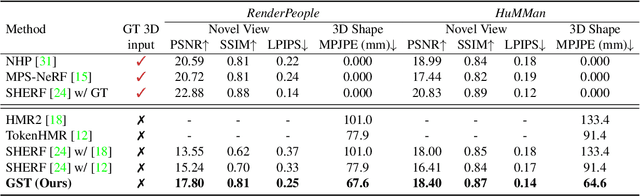
Reconstructing realistic 3D human models from monocular images has significant applications in creative industries, human-computer interfaces, and healthcare. We base our work on 3D Gaussian Splatting (3DGS), a scene representation composed of a mixture of Gaussians. Predicting such mixtures for a human from a single input image is challenging, as it is a non-uniform density (with a many-to-one relationship with input pixels) with strict physical constraints. At the same time, it needs to be flexible to accommodate a variety of clothes and poses. Our key observation is that the vertices of standardized human meshes (such as SMPL) can provide an adequate density and approximate initial position for Gaussians. We can then train a transformer model to jointly predict comparatively small adjustments to these positions, as well as the other Gaussians' attributes and the SMPL parameters. We show empirically that this combination (using only multi-view supervision) can achieve fast inference of 3D human models from a single image without test-time optimization, expensive diffusion models, or 3D points supervision. We also show that it can improve 3D pose estimation by better fitting human models that account for clothes and other variations. The code is available on the project website https://abdullahamdi.com/gst/ .
Stale Diffusion: Hyper-realistic 5D Movie Generation Using Old-school Methods
Apr 01, 2024
Two years ago, Stable Diffusion achieved super-human performance at generating images with super-human numbers of fingers. Following the steady decline of its technical novelty, we propose Stale Diffusion, a method that solidifies and ossifies Stable Diffusion in a maximum-entropy state. Stable Diffusion works analogously to a barn (the Stable) from which an infinite set of horses have escaped (the Diffusion). As the horses have long left the barn, our proposal may be seen as antiquated and irrelevant. Nevertheless, we vigorously defend our claim of novelty by identifying as early adopters of the Slow Science Movement, which will produce extremely important pearls of wisdom in the future. Our speed of contributions can also be seen as a quasi-static implementation of the recent call to pause AI experiments, which we wholeheartedly support. As a result of a careful archaeological expedition to 18-months-old Git commit histories, we found that naturally-accumulating errors have produced a novel entropy-maximising Stale Diffusion method, that can produce sleep-inducing hyper-realistic 5D video that is as good as one's imagination.
A Light Touch Approach to Teaching Transformers Multi-view Geometry
Nov 28, 2022Transformers are powerful visual learners, in large part due to their conspicuous lack of manually-specified priors. This flexibility can be problematic in tasks that involve multiple-view geometry, due to the near-infinite possible variations in 3D shapes and viewpoints (requiring flexibility), and the precise nature of projective geometry (obeying rigid laws). To resolve this conundrum, we propose a "light touch" approach, guiding visual Transformers to learn multiple-view geometry but allowing them to break free when needed. We achieve this by using epipolar lines to guide the Transformer's cross-attention maps, penalizing attention values outside the epipolar lines and encouraging higher attention along these lines since they contain geometrically plausible matches. Unlike previous methods, our proposal does not require any camera pose information at test-time. We focus on pose-invariant object instance retrieval, where standard Transformer networks struggle, due to the large differences in viewpoint between query and retrieved images. Experimentally, our method outperforms state-of-the-art approaches at object retrieval, without needing pose information at test-time.
Moving SLAM: Fully Unsupervised Deep Learning in Non-Rigid Scenes
Jun 01, 2021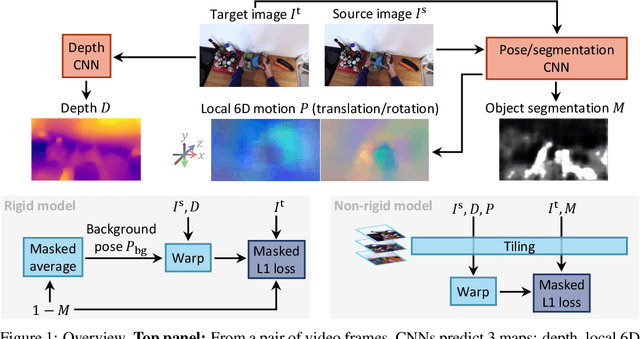
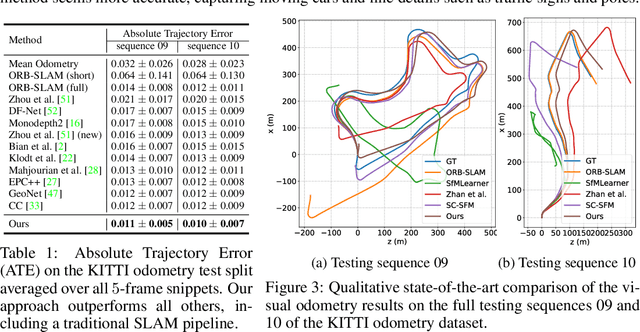
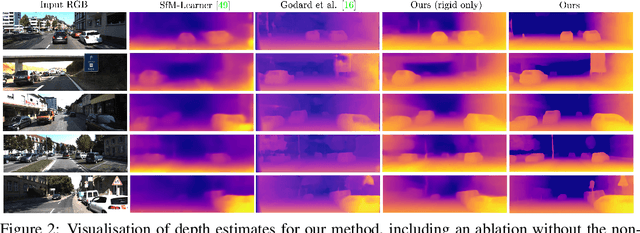
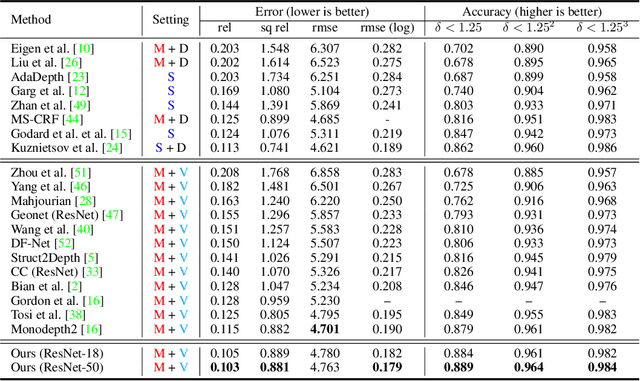
We propose a method to train deep networks to decompose videos into 3D geometry (camera and depth), moving objects, and their motions, with no supervision. We build on the idea of view synthesis, which uses classical camera geometry to re-render a source image from a different point-of-view, specified by a predicted relative pose and depth map. By minimizing the error between the synthetic image and the corresponding real image in a video, the deep network that predicts pose and depth can be trained completely unsupervised. However, the view synthesis equations rely on a strong assumption: that objects do not move. This rigid-world assumption limits the predictive power, and rules out learning about objects automatically. We propose a simple solution: minimize the error on small regions of the image instead. While the scene as a whole may be non-rigid, it is always possible to find small regions that are approximately rigid, such as inside a moving object. Our network can then predict different poses for each region, in a sliding window from a learned dense pose map. This represents a significantly richer model, including 6D object motions, with little additional complexity. We achieve very competitive performance on unsupervised odometry and depth prediction on KITTI. We also demonstrate new capabilities on EPIC-Kitchens, a challenging dataset of indoor videos, where there is no ground truth information for depth, odometry, object segmentation or motion. Yet all are recovered automatically by our method.
On the Origin of Species of Self-Supervised Learning
Mar 31, 2021

In the quiet backwaters of cs.CV, cs.LG and stat.ML, a cornucopia of new learning systems is emerging from a primordial soup of mathematics-learning systems with no need for external supervision. To date, little thought has been given to how these self-supervised learners have sprung into being or the principles that govern their continuing diversification. After a period of deliberate study and dispassionate judgement during which each author set their Zoom virtual background to a separate Galapagos island, we now entertain no doubt that each of these learning machines are lineal descendants of some older and generally extinct species. We make five contributions: (1) We gather and catalogue row-major arrays of machine learning specimens, each exhibiting heritable discriminative features; (2) We document a mutation mechanism by which almost imperceptible changes are introduced to the genotype of new systems, but their phenotype (birdsong in the form of tweets and vestigial plumage such as press releases) communicates dramatic changes; (3) We propose a unifying theory of self-supervised machine evolution and compare to other unifying theories on standard unifying theory benchmarks, where we establish a new (and unifying) state of the art; (4) We discuss the importance of digital biodiversity, in light of the endearingly optimistic Paris Agreement.
State-of-Art-Reviewing: A Radical Proposal to Improve Scientific Publication
Mar 31, 2020

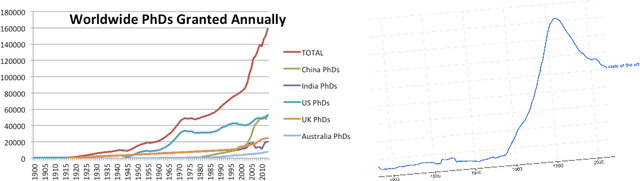

Peer review forms the backbone of modern scientific manuscript evaluation. But after two hundred and eighty-nine years of egalitarian service to the scientific community, does this protocol remain fit for purpose in 2020? In this work, we answer this question in the negative (strong reject, high confidence) and propose instead State-Of-the-Art Review (SOAR), a neoteric reviewing pipeline that serves as a 'plug-and-play' replacement for peer review. At the heart of our approach is an interpretation of the review process as a multi-objective, massively distributed and extremely-high-latency optimisation, which we scalarise and solve efficiently for PAC and CMT-optimal solutions. We make the following contributions: (1) We propose a highly scalable, fully automatic methodology for review, drawing inspiration from best-practices from premier computer vision and machine learning conferences; (2) We explore several instantiations of our approach and demonstrate that SOAR can be used to both review prints and pre-review pre-prints; (3) We wander listlessly in vain search of catharsis from our latest rounds of savage CVPR rejections.
Substitute Teacher Networks: Learning with Almost No Supervision
Apr 01, 2018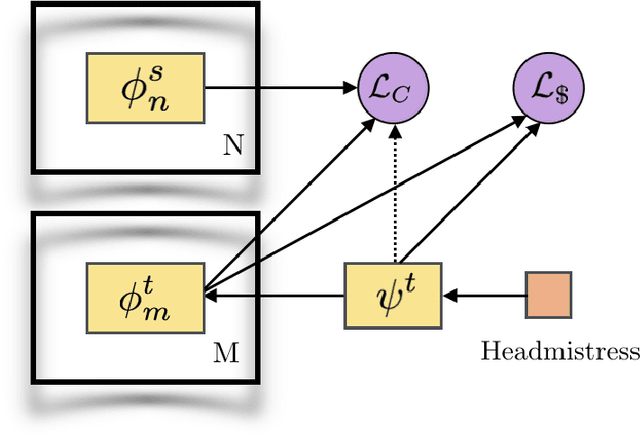


Learning through experience is time-consuming, inefficient and often bad for your cortisol levels. To address this problem, a number of recently proposed teacher-student methods have demonstrated the benefits of private tuition, in which a single model learns from an ensemble of more experienced tutors. Unfortunately, the cost of such supervision restricts good representations to a privileged minority. Unsupervised learning can be used to lower tuition fees, but runs the risk of producing networks that require extracurriculum learning to strengthen their CVs and create their own LinkedIn profiles. Inspired by the logo on a promotional stress ball at a local recruitment fair, we make the following three contributions. First, we propose a novel almost no supervision training algorithm that is effective, yet highly scalable in the number of student networks being supervised, ensuring that education remains affordable. Second, we demonstrate our approach on a typical use case: learning to bake, developing a method that tastily surpasses the current state of the art. Finally, we provide a rigorous quantitive analysis of our method, proving that we have access to a calculator. Our work calls into question the long-held dogma that life is the best teacher.