 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive View Selector: Fast and Accurate Active View Selection with Cross Reference Image Quality Assessment
Jun 24, 2025We tackle active view selection in novel view synthesis and 3D reconstruction. Existing methods like FisheRF and ActiveNeRF select the next best view by minimizing uncertainty or maximizing information gain in 3D, but they require specialized designs for different 3D representations and involve complex modelling in 3D space. Instead, we reframe this as a 2D image quality assessment (IQA) task, selecting views where current renderings have the lowest quality. Since ground-truth images for candidate views are unavailable, full-reference metrics like PSNR and SSIM are inapplicable, while no-reference metrics, such as MUSIQ and MANIQA, lack the essential multi-view context. Inspired by a recent cross-referencing quality framework CrossScore, we train a model to predict SSIM within a multi-view setup and use it to guide view selection. Our cross-reference IQA framework achieves substantial quantitative and qualitative improvements across standard benchmarks, while being agnostic to 3D representations, and runs 14-33 times faster than previous methods.
Jamais Vu: Exposing the Generalization Gap in Supervised Semantic Correspondence
Jun 09, 2025Semantic correspondence (SC) aims to establish semantically meaningful matches across different instances of an object category. We illustrate how recent supervised SC methods remain limited in their ability to generalize beyond sparsely annotated training keypoints, effectively acting as keypoint detectors. To address this, we propose a novel approach for learning dense correspondences by lifting 2D keypoints into a canonical 3D space using monocular depth estimation. Our method constructs a continuous canonical manifold that captures object geometry without requiring explicit 3D supervision or camera annotations. Additionally, we introduce SPair-U, an extension of SPair-71k with novel keypoint annotations, to better assess generalization. Experiments not only demonstrate that our model significantly outperforms supervised baselines on unseen keypoints, highlighting its effectiveness in learning robust correspondences, but that unsupervised baselines outperform supervised counterparts when generalized across different datasets.
GSLoc: Efficient Camera Pose Refinement via 3D Gaussian Splatting
Aug 20, 2024



We leverage 3D Gaussian Splatting (3DGS) as a scene representation and propose a novel test-time camera pose refinement framework, GSLoc. This framework enhances the localization accuracy of state-of-the-art absolute pose regression and scene coordinate regression methods. The 3DGS model renders high-quality synthetic images and depth maps to facilitate the establishment of 2D-3D correspondences. GSLoc obviates the need for training feature extractors or descriptors by operating directly on RGB images, utilizing the 3D vision foundation model, MASt3R, for precise 2D matching. To improve the robustness of our model in challenging outdoor environments, we incorporate an exposure-adaptive module within the 3DGS framework. Consequently, GSLoc enables efficient pose refinement given a single RGB query and a coarse initial pose estimation. Our proposed approach surpasses leading NeRF-based optimization methods in both accuracy and runtime across indoor and outdoor visual localization benchmarks, achieving state-of-the-art accuracy on two indoor datasets.
3D-Aware Instance Segmentation and Tracking in Egocentric Videos
Aug 19, 2024



Egocentric videos present unique challenges for 3D scene understanding due to rapid camera motion, frequent object occlusions, and limited object visibility. This paper introduces a novel approach to instance segmentation and tracking in first-person video that leverages 3D awareness to overcome these obstacles. Our method integrates scene geometry, 3D object centroid tracking, and instance segmentation to create a robust framework for analyzing dynamic egocentric scenes. By incorporating spatial and temporal cues, we achieve superior performance compared to state-of-the-art 2D approaches. Extensive evaluations on the challenging EPIC Fields dataset demonstrate significant improvements across a range of tracking and segmentation consistency metrics. Specifically, our method outperforms the next best performing approach by $7$ points in Association Accuracy (AssA) and $4.5$ points in IDF1 score, while reducing the number of ID switches by $73\%$ to $80\%$ across various object categories. Leveraging our tracked instance segmentations, we showcase downstream applications in 3D object reconstruction and amodal video object segmentation in these egocentric settings.
Reproducibility Study of CDUL: CLIP-Driven Unsupervised Learning for Multi-Label Image Classification
May 19, 2024



This report is a reproducibility study of the paper "CDUL: CLIP-Driven Unsupervised Learning for Multi-Label Image Classification" (Abdelfattah et al, ICCV 2023). Our report makes the following contributions: (1) We provide a reproducible, well commented and open-sourced code implementation for the entire method specified in the original paper. (2) We try to verify the effectiveness of the novel aggregation strategy which uses the CLIP model to initialize the pseudo labels for the subsequent unsupervised multi-label image classification task. (3) We try to verify the effectiveness of the gradient-alignment training method specified in the original paper, which is used to update the network parameters and pseudo labels. The code can be found at https://github.com/cs-mshah/CDUL
When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models
May 16, 2024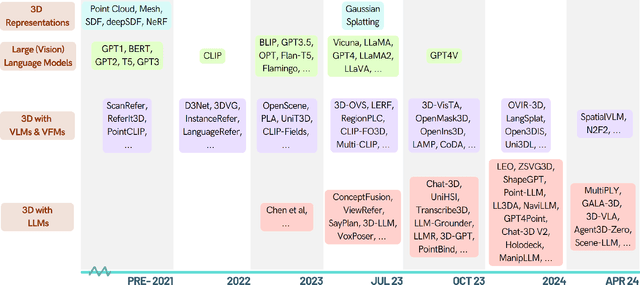
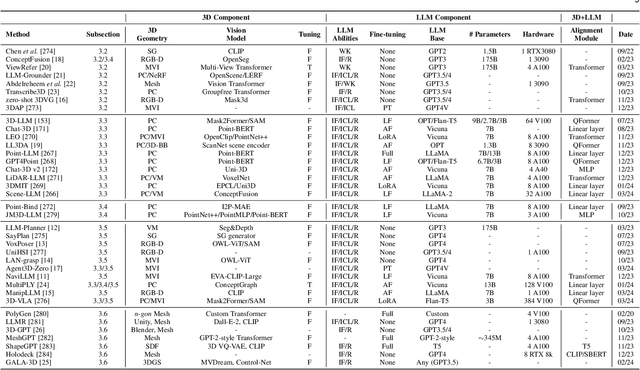
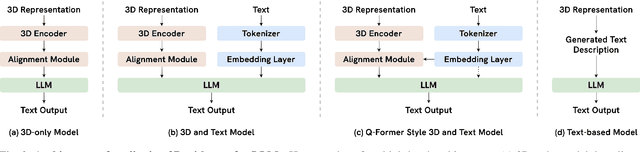
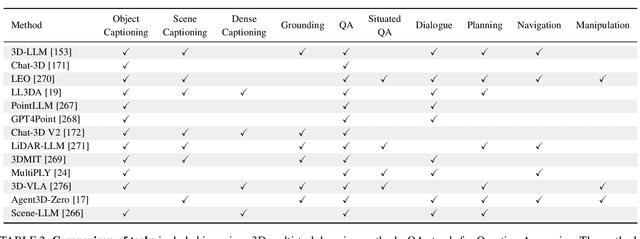
As large language models (LLMs) evolve, their integration with 3D spatial data (3D-LLMs) has seen rapid progress, offering unprecedented capabilities for understanding and interacting with physical spaces. This survey provides a comprehensive overview of the methodologies enabling LLMs to process, understand, and generate 3D data. Highlighting the unique advantages of LLMs, such as in-context learning, step-by-step reasoning, open-vocabulary capabilities, and extensive world knowledge, we underscore their potential to significantly advance spatial comprehension and interaction within embodied Artificial Intelligence (AI) systems. Our investigation spans various 3D data representations, from point clouds to Neural Radiance Fields (NeRFs). It examines their integration with LLMs for tasks such as 3D scene understanding, captioning, question-answering, and dialogue, as well as LLM-based agents for spatial reasoning, planning, and navigation. The paper also includes a brief review of other methods that integrate 3D and language. The meta-analysis presented in this paper reveals significant progress yet underscores the necessity for novel approaches to harness the full potential of 3D-LLMs. Hence, with this paper, we aim to chart a course for future research that explores and expands the capabilities of 3D-LLMs in understanding and interacting with the complex 3D world. To support this survey, we have established a project page where papers related to our topic are organized and listed: https://github.com/ActiveVisionLab/Awesome-LLM-3D.
N2F2: Hierarchical Scene Understanding with Nested Neural Feature Fields
Mar 16, 2024Understanding complex scenes at multiple levels of abstraction remains a formidable challenge in computer vision. To address this, we introduce Nested Neural Feature Fields (N2F2), a novel approach that employs hierarchical supervision to learn a single feature field, wherein different dimensions within the same high-dimensional feature encode scene properties at varying granularities. Our method allows for a flexible definition of hierarchies, tailored to either the physical dimensions or semantics or both, thereby enabling a comprehensive and nuanced understanding of scenes. We leverage a 2D class-agnostic segmentation model to provide semantically meaningful pixel groupings at arbitrary scales in the image space, and query the CLIP vision-encoder to obtain language-aligned embeddings for each of these segments. Our proposed hierarchical supervision method then assigns different nested dimensions of the feature field to distill the CLIP embeddings using deferred volumetric rendering at varying physical scales, creating a coarse-to-fine representation. Extensive experiments show that our approach outperforms the state-of-the-art feature field distillation methods on tasks such as open-vocabulary 3D segmentation and localization, demonstrating the effectiveness of the learned nested feature field.
SiLVR: Scalable Lidar-Visual Reconstruction with Neural Radiance Fields for Robotic Inspection
Mar 11, 2024
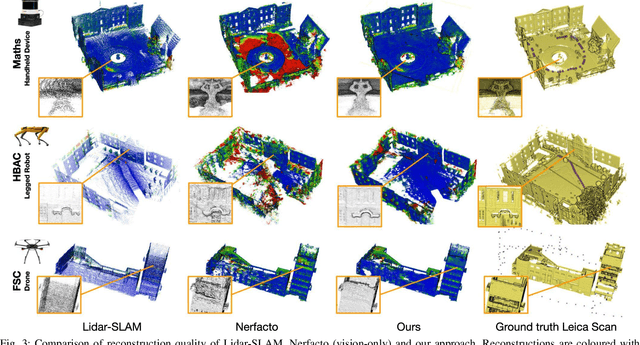


We present a neural-field-based large-scale reconstruction system that fuses lidar and vision data to generate high-quality reconstructions that are geometrically accurate and capture photo-realistic textures. This system adapts the state-of-the-art neural radiance field (NeRF) representation to also incorporate lidar data which adds strong geometric constraints on the depth and surface normals. We exploit the trajectory from a real-time lidar SLAM system to bootstrap a Structure-from-Motion (SfM) procedure to both significantly reduce the computation time and to provide metric scale which is crucial for lidar depth loss. We use submapping to scale the system to large-scale environments captured over long trajectories. We demonstrate the reconstruction system with data from a multi-camera, lidar sensor suite onboard a legged robot, hand-held while scanning building scenes for 600 metres, and onboard an aerial robot surveying a multi-storey mock disaster site-building. Website: https://ori-drs.github.io/projects/silvr/
Contrastive Lift: 3D Object Instance Segmentation by Slow-Fast Contrastive Fusion
Jun 07, 2023Instance segmentation in 3D is a challenging task due to the lack of large-scale annotated datasets. In this paper, we show that this task can be addressed effectively by leveraging instead 2D pre-trained models for instance segmentation. We propose a novel approach to lift 2D segments to 3D and fuse them by means of a neural field representation, which encourages multi-view consistency across frames. The core of our approach is a slow-fast clustering objective function, which is scalable and well-suited for scenes with a large number of objects. Unlike previous approaches, our method does not require an upper bound on the number of objects or object tracking across frames. To demonstrate the scalability of the slow-fast clustering, we create a new semi-realistic dataset called the Messy Rooms dataset, which features scenes with up to 500 objects per scene. Our approach outperforms the state-of-the-art on challenging scenes from the ScanNet, Hypersim, and Replica datasets, as well as on our newly created Messy Rooms dataset, demonstrating the effectiveness and scalability of our slow-fast clustering method.
Refinement for Absolute Pose Regression with Neural Feature Synthesis
Mar 17, 2023Absolute Pose Regression (APR) methods use deep neural networks to directly regress camera poses from RGB images. Despite their advantages in inference speed and simplicity, these methods still fall short of the accuracy achieved by geometry-based techniques. To address this issue, we propose a new model called the Neural Feature Synthesizer (NeFeS). Our approach encodes 3D geometric features during training and renders dense novel view features at test time to refine estimated camera poses from arbitrary APR methods. Unlike previous APR works that require additional unlabeled training data, our method leverages implicit geometric constraints during test time using a robust feature field. To enhance the robustness of our NeFeS network, we introduce a feature fusion module and a progressive training strategy. Our proposed method improves the state-of-the-art single-image APR accuracy by as much as 54.9% on indoor and outdoor benchmark datasets without additional time-consuming unlabeled data training.