 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSapling-NeRF: Geo-Localised Sapling Reconstruction in Forests for Ecological Monitoring
Feb 26, 2026Saplings are key indicators of forest regeneration and overall forest health. However, their fine-scale architectural traits are difficult to capture with existing 3D sensing methods, which make quantitative evaluation difficult. Terrestrial Laser Scanners (TLS), Mobile Laser Scanners (MLS), or traditional photogrammetry approaches poorly reconstruct thin branches, dense foliage, and lack the scale consistency needed for long-term monitoring. Implicit 3D reconstruction methods such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) are promising alternatives, but cannot recover the true scale of a scene and lack any means to be accurately geo-localised. In this paper, we present a pipeline which fuses NeRF, LiDAR SLAM, and GNSS to enable repeatable, geo-localised ecological monitoring of saplings. Our system proposes a three-level representation: (i) coarse Earth-frame localisation using GNSS, (ii) LiDAR-based SLAM for centimetre-accurate localisation and reconstruction, and (iii) NeRF-derived object-centric dense reconstruction of individual saplings. This approach enables repeatable quantitative evaluation and long-term monitoring of sapling traits. Our experiments in forest plots in Wytham Woods (Oxford, UK) and Evo (Finland) show that stem height, branching patterns, and leaf-to-wood ratios can be captured with increased accuracy as compared to TLS. We demonstrate that accurate stem skeletons and leaf distributions can be measured for saplings with heights between 0.5m and 2m in situ, giving ecologists access to richer structural and quantitative data for analysing forest dynamics.
Seeing in the Dark: Benchmarking Egocentric 3D Vision with the Oxford Day-and-Night Dataset
Jun 04, 2025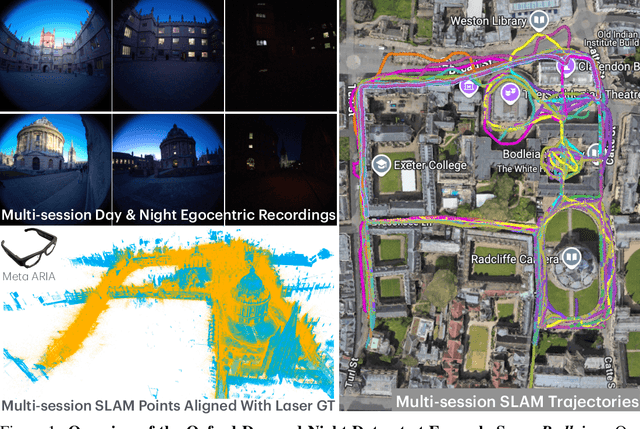


We introduce Oxford Day-and-Night, a large-scale, egocentric dataset for novel view synthesis (NVS) and visual relocalisation under challenging lighting conditions. Existing datasets often lack crucial combinations of features such as ground-truth 3D geometry, wide-ranging lighting variation, and full 6DoF motion. Oxford Day-and-Night addresses these gaps by leveraging Meta ARIA glasses to capture egocentric video and applying multi-session SLAM to estimate camera poses, reconstruct 3D point clouds, and align sequences captured under varying lighting conditions, including both day and night. The dataset spans over 30 $\mathrm{km}$ of recorded trajectories and covers an area of 40,000 $\mathrm{m}^2$, offering a rich foundation for egocentric 3D vision research. It supports two core benchmarks, NVS and relocalisation, providing a unique platform for evaluating models in realistic and diverse environments.
SiLVR: Scalable Lidar-Visual Radiance Field Reconstruction with Uncertainty Quantification
Feb 04, 2025



We present a neural radiance field (NeRF) based large-scale reconstruction system that fuses lidar and vision data to generate high-quality reconstructions that are geometrically accurate and capture photorealistic texture. Our system adopts the state-of-the-art NeRF representation to additionally incorporate lidar. Adding lidar data adds strong geometric constraints on the depth and surface normals, which is particularly useful when modelling uniform texture surfaces which contain ambiguous visual reconstruction cues. Furthermore, we estimate the epistemic uncertainty of the reconstruction as the spatial variance of each point location in the radiance field given the sensor observations from camera and lidar. This enables the identification of areas that are reliably reconstructed by each sensor modality, allowing the map to be filtered according to the estimated uncertainty. Our system can also exploit the trajectory produced by a real-time pose-graph lidar SLAM system during online mapping to bootstrap a (post-processed) Structure-from-Motion (SfM) reconstruction procedure reducing SfM training time by up to 70%. It also helps to properly constrain the overall metric scale which is essential for the lidar depth loss. The globally-consistent trajectory can then be divided into submaps using Spectral Clustering to group sets of co-visible images together. This submapping approach is more suitable for visual reconstruction than distance-based partitioning. Each submap is filtered according to point-wise uncertainty estimates and merged to obtain the final large-scale 3D reconstruction. We demonstrate the reconstruction system using a multi-camera, lidar sensor suite in experiments involving both robot-mounted and handheld scanning. Our test datasets cover a total area of more than 20,000 square metres, including multiple university buildings and an aerial survey of a multi-storey.
The Oxford Spires Dataset: Benchmarking Large-Scale LiDAR-Visual Localisation, Reconstruction and Radiance Field Methods
Nov 15, 2024
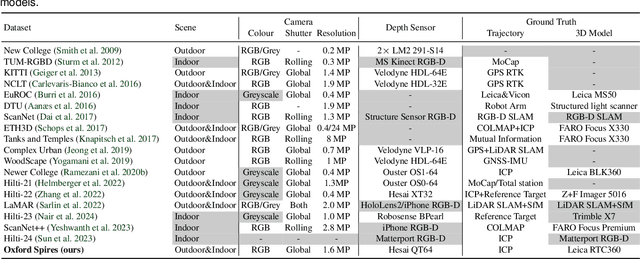
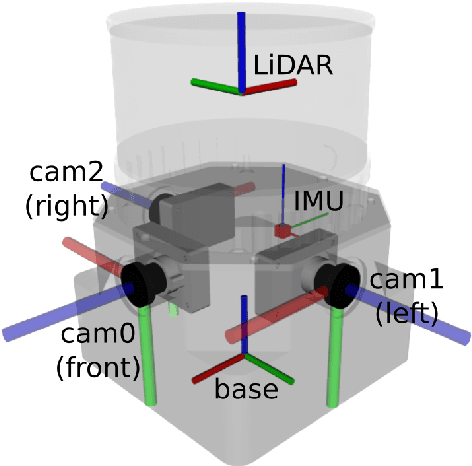
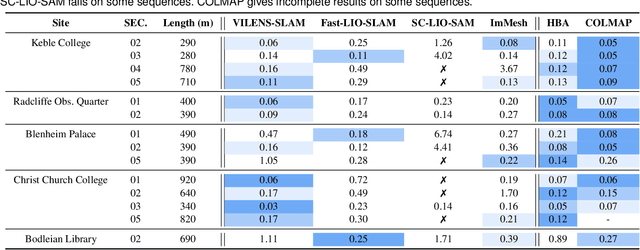
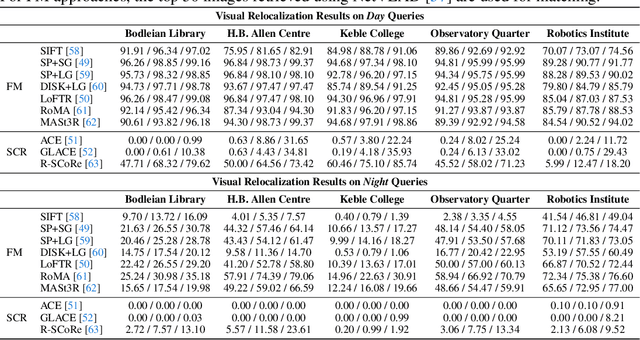
This paper introduces a large-scale multi-modal dataset captured in and around well-known landmarks in Oxford using a custom-built multi-sensor perception unit as well as a millimetre-accurate map from a Terrestrial LiDAR Scanner (TLS). The perception unit includes three synchronised global shutter colour cameras, an automotive 3D LiDAR scanner, and an inertial sensor - all precisely calibrated. We also establish benchmarks for tasks involving localisation, reconstruction, and novel-view synthesis, which enable the evaluation of Simultaneous Localisation and Mapping (SLAM) methods, Structure-from-Motion (SfM) and Multi-view Stereo (MVS) methods as well as radiance field methods such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting. To evaluate 3D reconstruction the TLS 3D models are used as ground truth. Localisation ground truth is computed by registering the mobile LiDAR scans to the TLS 3D models. Radiance field methods are evaluated not only with poses sampled from the input trajectory, but also from viewpoints that are from trajectories which are distant from the training poses. Our evaluation demonstrates a key limitation of state-of-the-art radiance field methods: we show that they tend to overfit to the training poses/images and do not generalise well to out-of-sequence poses. They also underperform in 3D reconstruction compared to MVS systems using the same visual inputs. Our dataset and benchmarks are intended to facilitate better integration of radiance field methods and SLAM systems. The raw and processed data, along with software for parsing and evaluation, can be accessed at https://dynamic.robots.ox.ac.uk/datasets/oxford-spires/.
Visual Localization in 3D Maps: Comparing Point Cloud, Mesh, and NeRF Representations
Aug 21, 2024



This paper introduces and assesses a cross-modal global visual localization system that can localize camera images within a color 3D map representation built using both visual and lidar sensing. We present three different state-of-the-art methods for creating the color 3D maps: point clouds, meshes, and neural radiance fields (NeRF). Our system constructs a database of synthetic RGB and depth image pairs from these representations. This database serves as the basis for global localization. We present an automatic approach that builds this database by synthesizing novel images of the scene and exploiting the 3D structure encoded in the different representations. Next, we present a global localization system that relies on the synthetic image database to accurately estimate the 6 DoF camera poses of monocular query images. Our localization approach relies on different learning-based global descriptors and feature detectors which enable robust image retrieval and matching despite the domain gap between (real) query camera images and the synthetic database images. We assess the system's performance through extensive real-world experiments in both indoor and outdoor settings, in order to evaluate the effectiveness of each map representation and the benefits against traditional structure-from-motion localization approaches. Our results show that all three map representations can achieve consistent localization success rates of 55% and higher across various environments. NeRF synthesized images show superior performance, localizing query images at an average success rate of 72%. Furthermore, we demonstrate that our synthesized database enables global localization even when the map creation data and the localization sequence are captured when travelling in opposite directions. Our system, operating in real-time on a mobile laptop equipped with a GPU, achieves a processing rate of 1Hz.
SiLVR: Scalable Lidar-Visual Reconstruction with Neural Radiance Fields for Robotic Inspection
Mar 11, 2024
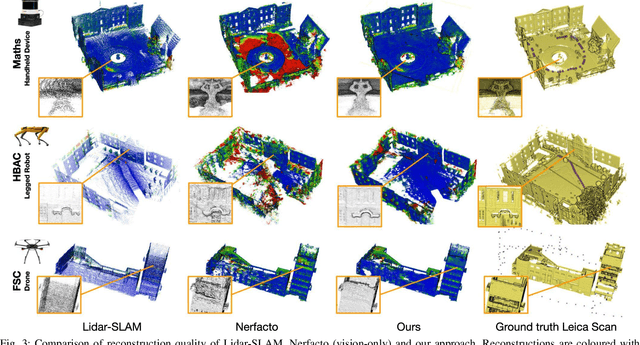


We present a neural-field-based large-scale reconstruction system that fuses lidar and vision data to generate high-quality reconstructions that are geometrically accurate and capture photo-realistic textures. This system adapts the state-of-the-art neural radiance field (NeRF) representation to also incorporate lidar data which adds strong geometric constraints on the depth and surface normals. We exploit the trajectory from a real-time lidar SLAM system to bootstrap a Structure-from-Motion (SfM) procedure to both significantly reduce the computation time and to provide metric scale which is crucial for lidar depth loss. We use submapping to scale the system to large-scale environments captured over long trajectories. We demonstrate the reconstruction system with data from a multi-camera, lidar sensor suite onboard a legged robot, hand-held while scanning building scenes for 600 metres, and onboard an aerial robot surveying a multi-storey mock disaster site-building. Website: https://ori-drs.github.io/projects/silvr/
Osprey: Multi-Session Autonomous Aerial Mapping with LiDAR-based SLAM and Next Best View Planning
Nov 06, 2023Aerial mapping systems are important for many surveying applications (e.g., industrial inspection or agricultural monitoring). Semi-autonomous mapping with GPS-guided aerial platforms that fly preplanned missions is already widely available but fully autonomous systems can significantly improve efficiency. Autonomously mapping complex 3D structures requires a system that performs online mapping and mission planning. This paper presents Osprey, an autonomous aerial mapping system with state-of-the-art multi-session mapping capabilities. It enables a non-expert operator to specify a bounded target area that the aerial platform can then map autonomously, over multiple flights if necessary. Field experiments with Osprey demonstrate that this system can achieve greater map coverage of large industrial sites than manual surveys with a pilot-flown aerial platform or a terrestrial laser scanner (TLS). Three sites, with a total ground coverage of $7085$ m$^2$ and a maximum height of $27$ m, were mapped in separate missions using $112$ minutes of autonomous flight time. True colour maps were created from images captured by Osprey using pointcloud and NeRF reconstruction methods. These maps provide useful data for structural inspection tasks.
3D Lidar Reconstruction with Probabilistic Depth Completion for Robotic Navigation
Jul 25, 2022
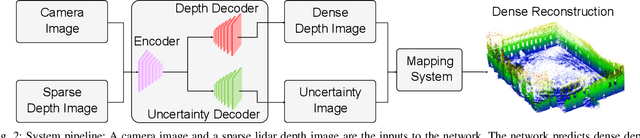


Safe motion planning in robotics requires planning into space which has been verified to be free of obstacles. However, obtaining such environment representations using lidars is challenging by virtue of the sparsity of their depth measurements. We present a learning-aided 3D lidar reconstruction framework that upsamples sparse lidar depth measurements with the aid of overlapping camera images so as to generate denser reconstructions with more definitively free space than can be achieved with the raw lidar measurements alone. We use a neural network with an encoder-decoder structure to predict dense depth images along with depth uncertainty estimates which are fused using a volumetric mapping system. We conduct experiments on real-world outdoor datasets captured using a handheld sensing device and a legged robot. Using input data from a 16-beam lidar mapping a building network, our experiments showed that the amount of estimated free space was increased by more than 40% with our approach. We also show that our approach trained on a synthetic dataset generalises well to real-world outdoor scenes without additional fine-tuning. Finally, we demonstrate how motion planning tasks can benefit from these denser reconstructions.