 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-BDM: A Direct and Efficient Boundary-Based Occupancy Grid Mapping Framework for LiDARs
Apr 14, 2026Efficient and scalable 3D occupancy mapping is essential for autonomous robot applications in unknown environments. However, traditional occupancy grid representations suffer from two fundamental limitations. First, explicitly storing all voxels in three-dimensional space leads to prohibitive memory consumption. Second, exhaustive ray casting incurs high update latency. A recent representation alleviate memory demands by maintaining only the voxels on the two-dimensional boundary, yet they still rely on full ray casting updates. This work advances the boundary-based framework with a highly efficient update scheme. We introduce a truncated ray casting strategy that restricts voxel traversal to the exterior of the boundary, which dramatically reduces the number of updated voxels. In addition, we propose a direct boundary update mechanism that removes the need for an auxiliary local 3D occupancy grid, further reducing memory usage and simplifying the map update pipeline. We name our framework as D-BDM. Extensive evaluations on public datasets demonstrate that our approach achieves significantly lower update time and reduced memory consumption compared with the baseline methods, as well as the prior boundary-based approach.
Memory-Efficient Boundary Map for Large-Scale Occupancy Grid Mapping
Mar 23, 2026Determining the occupancy status of locations in the environment is a fundamental task for safety-critical robotic applications. Traditional occupancy grid mapping methods subdivide the environment into a grid of voxels, each associated with one of three occupancy states: free, occupied, or unknown. These methods explicitly maintain all voxels within the mapped volume and determine the occupancy state of a location by directly querying the corresponding voxel that the location falls within. However, maintaining all grid voxels in high-resolution and large-scale scenarios requires substantial memory resources. In this paper, we introduce a novel representation that only maintains the boundary of the mapped volume. Specifically, we explicitly represent the boundary voxels, such as the occupied voxels and frontier voxels, while free and unknown voxels are automatically represented by volumes within or outside the boundary, respectively. As our representation maintains only a closed surface in two-dimensional (2D) space, instead of the entire volume in three-dimensional (3D) space, it significantly reduces memory consumption. Then, based on this 2D representation, we propose a method to determine the occupancy state of arbitrary locations in the 3D environment. We term this method as boundary map. Besides, we design a novel data structure for maintaining the boundary map, supporting efficient occupancy state queries. Theoretical analyses of the occupancy state query algorithm are also provided. Furthermore, to enable efficient construction and updates of the boundary map from the real-time sensor measurements, we propose a global-local mapping framework and corresponding update algorithms. Finally, we will make our implementation of the boundary map open-source on GitHub to benefit the community:https://github.com/hku-mars/BDM.
Sparse Video Generation Propels Real-World Beyond-the-View Vision-Language Navigation
Feb 05, 2026Why must vision-language navigation be bound to detailed and verbose language instructions? While such details ease decision-making, they fundamentally contradict the goal for navigation in the real-world. Ideally, agents should possess the autonomy to navigate in unknown environments guided solely by simple and high-level intents. Realizing this ambition introduces a formidable challenge: Beyond-the-View Navigation (BVN), where agents must locate distant, unseen targets without dense and step-by-step guidance. Existing large language model (LLM)-based methods, though adept at following dense instructions, often suffer from short-sighted behaviors due to their reliance on short-horimzon supervision. Simply extending the supervision horizon, however, destabilizes LLM training. In this work, we identify that video generation models inherently benefit from long-horizon supervision to align with language instructions, rendering them uniquely suitable for BVN tasks. Capitalizing on this insight, we propose introducing the video generation model into this field for the first time. Yet, the prohibitive latency for generating videos spanning tens of seconds makes real-world deployment impractical. To bridge this gap, we propose SparseVideoNav, achieving sub-second trajectory inference guided by a generated sparse future spanning a 20-second horizon. This yields a remarkable 27x speed-up compared to the unoptimized counterpart. Extensive real-world zero-shot experiments demonstrate that SparseVideoNav achieves 2.5x the success rate of state-of-the-art LLM baselines on BVN tasks and marks the first realization of such capability in challenging night scenes.
6DAttack: Backdoor Attacks in the 6DoF Pose Estimation
Dec 22, 2025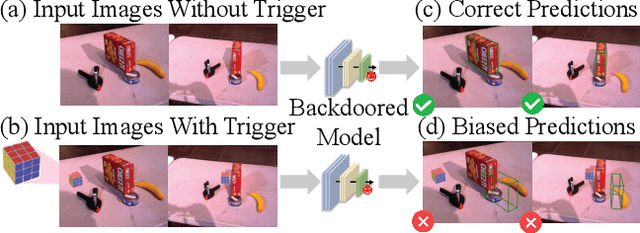
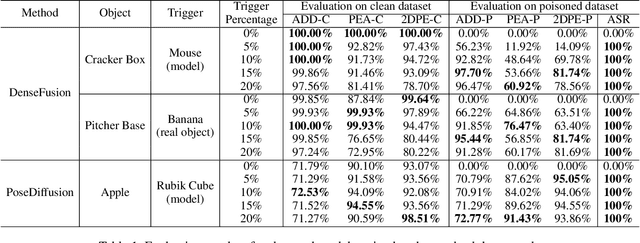
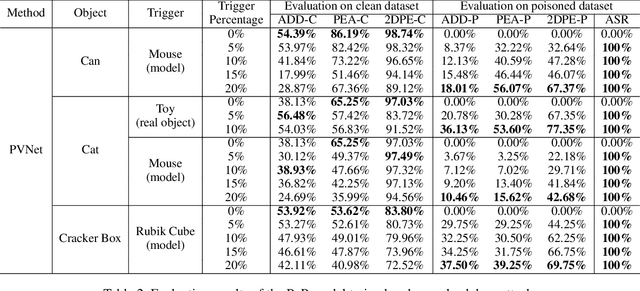
Deep learning advances have enabled accurate six-degree-of-freedom (6DoF) object pose estimation, widely used in robotics, AR/VR, and autonomous systems. However, backdoor attacks pose significant security risks. While most research focuses on 2D vision, 6DoF pose estimation remains largely unexplored. Unlike traditional backdoors that only change classes, 6DoF attacks must control continuous parameters like translation and rotation, rendering 2D methods inapplicable. We propose 6DAttack, a framework using 3D object triggers to induce controlled erroneous poses while maintaining normal behavior. Evaluations on PVNet, DenseFusion, and PoseDiffusion across LINEMOD, YCB-Video, and CO3D show high attack success rates (ASRs) without compromising clean performance. Backdoored models achieve up to 100% clean ADD accuracy and 100% ASR, with triggered samples reaching 97.70% ADD-P. Furthermore, a representative defense remains ineffective. Our findings reveal a serious, underexplored threat to 6DoF pose estimation.
FAST-Calib: LiDAR-Camera Extrinsic Calibration in One Second
Jul 23, 2025This paper proposes FAST-Calib, a fast and user-friendly LiDAR-camera extrinsic calibration tool based on a custom-made 3D target. FAST-Calib supports both mechanical and solid-state LiDARs by leveraging an efficient and reliable edge extraction algorithm that is agnostic to LiDAR scan patterns. It also compensates for edge dilation artifacts caused by LiDAR spot spread through ellipse fitting, and supports joint optimization across multiple scenes. We validate FAST-Calib on three LiDAR models (Ouster, Avia, and Mid360), each paired with a wide-angle camera. Experimental results demonstrate superior accuracy and robustness compared to existing methods. With point-to-point registration errors consistently below 6.5mm and total processing time under 0.7s, FAST-Calib provides an efficient, accurate, and target-based automatic calibration pipeline. We have open-sourced our code and dataset on GitHub to benefit the robotics community.
Mesh-Learner: Texturing Mesh with Spherical Harmonics
Apr 28, 2025In this paper, we present a 3D reconstruction and rendering framework termed Mesh-Learner that is natively compatible with traditional rasterization pipelines. It integrates mesh and spherical harmonic (SH) texture (i.e., texture filled with SH coefficients) into the learning process to learn each mesh s view-dependent radiance end-to-end. Images are rendered by interpolating surrounding SH Texels at each pixel s sampling point using a novel interpolation method. Conversely, gradients from each pixel are back-propagated to the related SH Texels in SH textures. Mesh-Learner exploits graphic features of rasterization pipeline (texture sampling, deferred rendering) to render, which makes Mesh-Learner naturally compatible with tools (e.g., Blender) and tasks (e.g., 3D reconstruction, scene rendering, reinforcement learning for robotics) that are based on rasterization pipelines. Our system can train vast, unlimited scenes because we transfer only the SH textures within the frustum to the GPU for training. At other times, the SH textures are stored in CPU RAM, which results in moderate GPU memory usage. The rendering results on interpolation and extrapolation sequences in the Replica and FAST-LIVO2 datasets achieve state-of-the-art performance compared to existing state-of-the-art methods (e.g., 3D Gaussian Splatting and M2-Mapping). To benefit the society, the code will be available at https://github.com/hku-mars/Mesh-Learner.
Flying through cluttered and dynamic environments with LiDAR
Apr 24, 2025



Navigating unmanned aerial vehicles (UAVs) through cluttered and dynamic environments remains a significant challenge, particularly when dealing with fast-moving or sudden-appearing obstacles. This paper introduces a complete LiDAR-based system designed to enable UAVs to avoid various moving obstacles in complex environments. Benefiting the high computational efficiency of perception and planning, the system can operate in real time using onboard computing resources with low latency. For dynamic environment perception, we have integrated our previous work, M-detector, into the system. M-detector ensures that moving objects of different sizes, colors, and types are reliably detected. For dynamic environment planning, we incorporate dynamic object predictions into the integrated planning and control (IPC) framework, namely DynIPC. This integration allows the UAV to utilize predictions about dynamic obstacles to effectively evade them. We validate our proposed system through both simulations and real-world experiments. In simulation tests, our system outperforms state-of-the-art baselines across several metrics, including success rate, time consumption, average flight time, and maximum velocity. In real-world trials, our system successfully navigates through forests, avoiding moving obstacles along its path.
FERMI: Flexible Radio Mapping with a Hybrid Propagation Model and Scalable Autonomous Data Collection
Apr 21, 2025Communication is fundamental for multi-robot collaboration, with accurate radio mapping playing a crucial role in predicting signal strength between robots. However, modeling radio signal propagation in large and occluded environments is challenging due to complex interactions between signals and obstacles. Existing methods face two key limitations: they struggle to predict signal strength for transmitter-receiver pairs not present in the training set, while also requiring extensive manual data collection for modeling, making them impractical for large, obstacle-rich scenarios. To overcome these limitations, we propose FERMI, a flexible radio mapping framework. FERMI combines physics-based modeling of direct signal paths with a neural network to capture environmental interactions with radio signals. This hybrid model learns radio signal propagation more efficiently, requiring only sparse training data. Additionally, FERMI introduces a scalable planning method for autonomous data collection using a multi-robot team. By increasing parallelism in data collection and minimizing robot travel costs between regions, overall data collection efficiency is significantly improved. Experiments in both simulation and real-world scenarios demonstrate that FERMI enables accurate signal prediction and generalizes well to unseen positions in complex environments. It also supports fully autonomous data collection and scales to different team sizes, offering a flexible solution for creating radio maps. Our code is open-sourced at https://github.com/ymLuo1214/Flexible-Radio-Mapping.
Efficient Swept Volume-Based Trajectory Generation for Arbitrary-Shaped Ground Robot Navigation
Apr 10, 2025Navigating an arbitrary-shaped ground robot safely in cluttered environments remains a challenging problem. The existing trajectory planners that account for the robot's physical geometry severely suffer from the intractable runtime. To achieve both computational efficiency and Continuous Collision Avoidance (CCA) of arbitrary-shaped ground robot planning, we proposed a novel coarse-to-fine navigation framework that significantly accelerates planning. In the first stage, a sampling-based method selectively generates distinct topological paths that guarantee a minimum inflated margin. In the second stage, a geometry-aware front-end strategy is designed to discretize these topologies into full-state robot motion sequences while concurrently partitioning the paths into SE(2) sub-problems and simpler R2 sub-problems for back-end optimization. In the final stage, an SVSDF-based optimizer generates trajectories tailored to these sub-problems and seamlessly splices them into a continuous final motion plan. Extensive benchmark comparisons show that the proposed method is one to several orders of magnitude faster than the cutting-edge methods in runtime while maintaining a high planning success rate and ensuring CCA.
LiDAR-based Quadrotor Autonomous Inspection System in Cluttered Environments
Mar 29, 2025In recent years, autonomous unmanned aerial vehicle (UAV) technology has seen rapid advancements, significantly improving operational efficiency and mitigating risks associated with manual tasks in domains such as industrial inspection, agricultural monitoring, and search-and-rescue missions. Despite these developments, existing UAV inspection systems encounter two critical challenges: limited reliability in complex, unstructured, and GNSS-denied environments, and a pronounced dependency on skilled operators. To overcome these limitations, this study presents a LiDAR-based UAV inspection system employing a dual-phase workflow: human-in-the-loop inspection and autonomous inspection. During the human-in-the-loop phase, untrained pilots are supported by autonomous obstacle avoidance, enabling them to generate 3D maps, specify inspection points, and schedule tasks. Inspection points are then optimized using the Traveling Salesman Problem (TSP) to create efficient task sequences. In the autonomous phase, the quadrotor autonomously executes the planned tasks, ensuring safe and efficient data acquisition. Comprehensive field experiments conducted in various environments, including slopes, landslides, agricultural fields, factories, and forests, confirm the system's reliability and flexibility. Results reveal significant enhancements in inspection efficiency, with autonomous operations reducing trajectory length by up to 40\% and flight time by 57\% compared to human-in-the-loop operations. These findings underscore the potential of the proposed system to enhance UAV-based inspections in safety-critical and resource-constrained scenarios.