 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Distributed Large-Scale Point Cloud Bundle Adjustment via Majorization-Minimization
Feb 26, 2025



Point cloud bundle adjustment is critical in large-scale point cloud mapping. However, it is both computationally and memory intensive, with its complexity growing cubically as the number of scan poses increases. This paper presents BALM3.0, an efficient and distributed large-scale point cloud bundle adjustment method. The proposed method employs the majorization-minimization algorithm to decouple the scan poses in the bundle adjustment process, thus performing the point cloud bundle adjustment on large-scale data with improved computational efficiency. The key difficulty of applying majorization-minimization on bundle adjustment is to identify the proper surrogate cost function. In this paper, the proposed surrogate cost function is based on the point-to-plane distance. The primary advantages of decoupling the scan poses via a majorization-minimization algorithm stem from two key aspects. First, the decoupling of scan poses reduces the optimization time complexity from cubic to linear, significantly enhancing the computational efficiency of the bundle adjustment process in large-scale environments. Second, it lays the theoretical foundation for distributed bundle adjustment. By distributing both data and computation across multiple devices, this approach helps overcome the limitations posed by large memory and computational requirements, which may be difficult for a single device to handle. The proposed method is extensively evaluated in both simulated and real-world environments. The results demonstrate that the proposed method achieves the same optimal residual with comparable accuracy while offering up to 704 times faster optimization speed and reducing memory usage to 1/8. Furthermore, this paper also presented and implemented a distributed bundle adjustment framework and successfully optimized large-scale data (21,436 poses with 70 GB point clouds) with four consumer-level laptops.
Voxel-SLAM: A Complete, Accurate, and Versatile LiDAR-Inertial SLAM System
Oct 11, 2024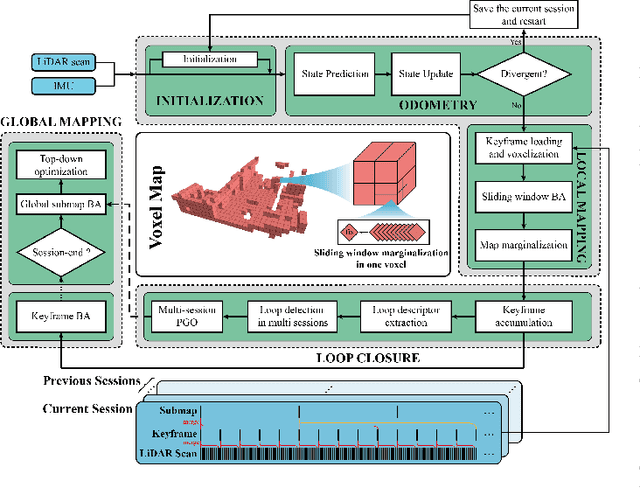
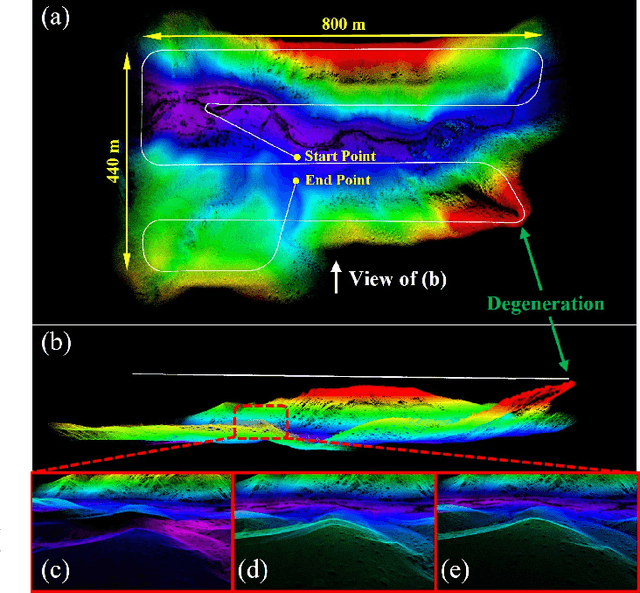
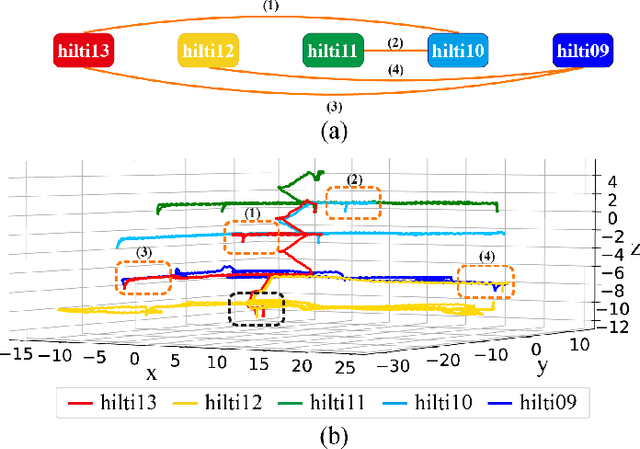

In this work, we present Voxel-SLAM: a complete, accurate, and versatile LiDAR-inertial SLAM system that fully utilizes short-term, mid-term, long-term, and multi-map data associations to achieve real-time estimation and high precision mapping. The system consists of five modules: initialization, odometry, local mapping, loop closure, and global mapping, all employing the same map representation, an adaptive voxel map. The initialization provides an accurate initial state estimation and a consistent local map for subsequent modules, enabling the system to start with a highly dynamic initial state. The odometry, exploiting the short-term data association, rapidly estimates current states and detects potential system divergence. The local mapping, exploiting the mid-term data association, employs a local LiDAR-inertial bundle adjustment (BA) to refine the states (and the local map) within a sliding window of recent LiDAR scans. The loop closure detects previously visited places in the current and all previous sessions. The global mapping refines the global map with an efficient hierarchical global BA. The loop closure and global mapping both exploit long-term and multi-map data associations. We conducted a comprehensive benchmark comparison with other state-of-the-art methods across 30 sequences from three representative scenes, including narrow indoor environments using hand-held equipment, large-scale wilderness environments with aerial robots, and urban environments on vehicle platforms. Other experiments demonstrate the robustness and efficiency of the initialization, the capacity to work in multiple sessions, and relocalization in degenerated environments.
LVBA: LiDAR-Visual Bundle Adjustment for RGB Point Cloud Mapping
Sep 17, 2024



Point cloud maps with accurate color are crucial in robotics and mapping applications. Existing approaches for producing RGB-colorized maps are primarily based on real-time localization using filter-based estimation or sliding window optimization, which may lack accuracy and global consistency. In this work, we introduce a novel global LiDAR-Visual bundle adjustment (BA) named LVBA to improve the quality of RGB point cloud mapping beyond existing baselines. LVBA first optimizes LiDAR poses via a global LiDAR BA, followed by a photometric visual BA incorporating planar features from the LiDAR point cloud for camera pose optimization. Additionally, to address the challenge of map point occlusions in constructing optimization problems, we implement a novel LiDAR-assisted global visibility algorithm in LVBA. To evaluate the effectiveness of LVBA, we conducted extensive experiments by comparing its mapping quality against existing state-of-the-art baselines (i.e., R$^3$LIVE and FAST-LIVO). Our results prove that LVBA can proficiently reconstruct high-fidelity, accurate RGB point cloud maps, outperforming its counterparts.
ScaleFold: Reducing AlphaFold Initial Training Time to 10 Hours
Apr 17, 2024



AlphaFold2 has been hailed as a breakthrough in protein folding. It can rapidly predict protein structures with lab-grade accuracy. However, its implementation does not include the necessary training code. OpenFold is the first trainable public reimplementation of AlphaFold. AlphaFold training procedure is prohibitively time-consuming, and gets diminishing benefits from scaling to more compute resources. In this work, we conducted a comprehensive analysis on the AlphaFold training procedure based on Openfold, identified that inefficient communications and overhead-dominated computations were the key factors that prevented the AlphaFold training from effective scaling. We introduced ScaleFold, a systematic training method that incorporated optimizations specifically for these factors. ScaleFold successfully scaled the AlphaFold training to 2080 NVIDIA H100 GPUs with high resource utilization. In the MLPerf HPC v3.0 benchmark, ScaleFold finished the OpenFold benchmark in 7.51 minutes, shown over $6\times$ speedup than the baseline. For training the AlphaFold model from scratch, ScaleFold completed the pretraining in 10 hours, a significant improvement over the seven days required by the original AlphaFold pretraining baseline.
Joint Intrinsic and Extrinsic LiDAR-Camera Calibration in Targetless Environments Using Plane-Constrained Bundle Adjustment
Aug 24, 2023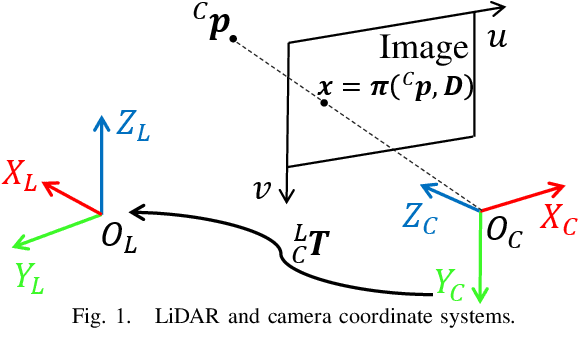
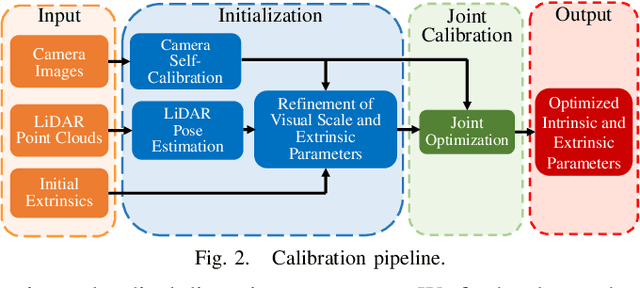
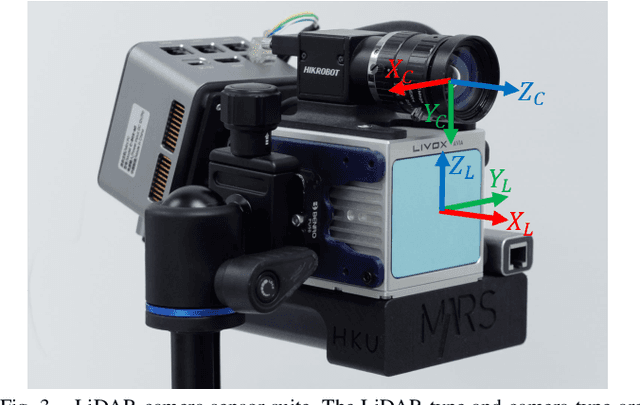

This paper introduces a novel targetless method for joint intrinsic and extrinsic calibration of LiDAR-camera systems using plane-constrained bundle adjustment (BA). Our method leverages LiDAR point cloud measurements from planes in the scene, alongside visual points derived from those planes. The core novelty of our method lies in the integration of visual BA with the registration between visual points and LiDAR point cloud planes, which is formulated as a unified optimization problem. This formulation achieves concurrent intrinsic and extrinsic calibration, while also imparting depth constraints to the visual points to enhance the accuracy of intrinsic calibration. Experiments are conducted on both public data sequences and self-collected dataset. The results showcase that our approach not only surpasses other state-of-the-art (SOTA) methods but also maintains remarkable calibration accuracy even within challenging environments. For the benefits of the robotics community, we have open sourced our codes.
Zoom Out and Observe: News Environment Perception for Fake News Detection
Mar 21, 2022
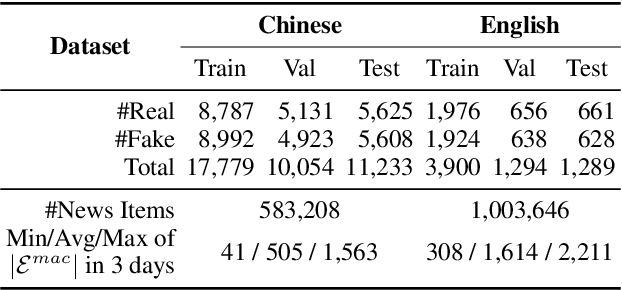
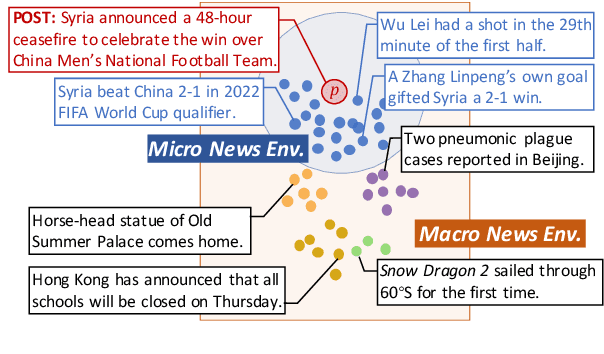
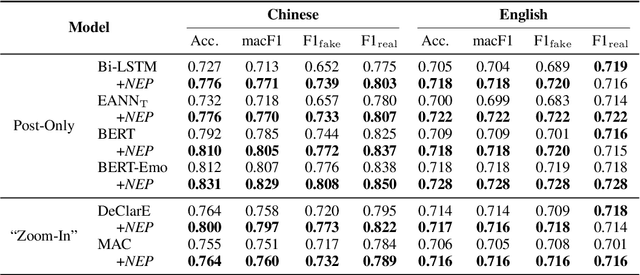
Fake news detection is crucial for preventing the dissemination of misinformation on social media. To differentiate fake news from real ones, existing methods observe the language patterns of the news post and "zoom in" to verify its content with knowledge sources or check its readers' replies. However, these methods neglect the information in the external news environment where a fake news post is created and disseminated. The news environment represents recent mainstream media opinion and public attention, which is an important inspiration of fake news fabrication because fake news is often designed to ride the wave of popular events and catch public attention with unexpected novel content for greater exposure and spread. To capture the environmental signals of news posts, we "zoom out" to observe the news environment and propose the News Environment Perception Framework (NEP). For each post, we construct its macro and micro news environment from recent mainstream news. Then we design a popularity-oriented and a novelty-oriented module to perceive useful signals and further assist final prediction. Experiments on our newly built datasets show that the NEP can efficiently improve the performance of basic fake news detectors.
Confidence Propagation Cluster: Unleash Full Potential of Object Detectors
Dec 10, 2021



It has been a long history that most object detection methods obtain objects by using the non-maximum suppression (NMS) and its improved versions like Soft-NMS to remove redundant bounding boxes. We challenge those NMS-based methods from three aspects: 1) The bounding box with highest confidence value may not be the true positive having the biggest overlap with the ground-truth box. 2) Not only suppression is required for redundant boxes, but also confidence enhancement is needed for those true positives. 3) Sorting candidate boxes by confidence values is not necessary so that full parallelism is achievable. In this paper, inspired by belief propagation (BP), we propose the Confidence Propagation Cluster (CP-Cluster) to replace NMS-based methods, which is fully parallelizable as well as better in accuracy. In CP-Cluster, we borrow the message passing mechanism from BP to penalize redundant boxes and enhance true positives simultaneously in an iterative way until convergence. We verified the effectiveness of CP-Cluster by applying it to various mainstream detectors such as FasterRCNN, SSD, FCOS, YOLOv3, YOLOv5, Centernet etc. Experiments on MS COCO show that our plug and play method, without retraining detectors, is able to steadily improve average mAP of all those state-of-the-art models with a clear margin from 0.2 to 1.9 respectively when compared with NMS-based methods. Source code is available at https://github.com/shenyi0220/CP-Cluster