 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
MoE Parallel Folding: Heterogeneous Parallelism Mappings for Efficient Large-Scale MoE Model Training with Megatron Core
Apr 21, 2025



Mixture of Experts (MoE) models enhance neural network scalability by dynamically selecting relevant experts per input token, enabling larger model sizes while maintaining manageable computation costs. However, efficient training of large-scale MoE models across thousands of GPUs presents significant challenges due to limitations in existing parallelism strategies. We introduce an end-to-end training framework for large-scale MoE models that utilizes five-dimensional hybrid parallelism: Tensor Parallelism, Expert Parallelism, Context Parallelism, Data Parallelism, and Pipeline Parallelism. Central to our approach is MoE Parallel Folding, a novel strategy that decouples the parallelization of attention and MoE layers in Transformer models, allowing each layer type to adopt optimal parallel configurations. Additionally, we develop a flexible token-level dispatcher that supports both token-dropping and token-dropless MoE training across all five dimensions of parallelism. This dispatcher accommodates dynamic tensor shapes and coordinates different parallelism schemes for Attention and MoE layers, facilitating complex parallelism implementations. Our experiments demonstrate significant improvements in training efficiency and scalability. We achieve up to 49.3% Model Flops Utilization (MFU) for the Mixtral 8x22B model and 39.0% MFU for the Qwen2-57B-A14B model on H100 GPUs, outperforming existing methods. The framework scales efficiently up to 1,024 GPUs and maintains high performance with sequence lengths up to 128K tokens, validating its effectiveness for large-scale MoE model training. The code is available in Megatron-Core.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
ScaleFold: Reducing AlphaFold Initial Training Time to 10 Hours
Apr 17, 2024



AlphaFold2 has been hailed as a breakthrough in protein folding. It can rapidly predict protein structures with lab-grade accuracy. However, its implementation does not include the necessary training code. OpenFold is the first trainable public reimplementation of AlphaFold. AlphaFold training procedure is prohibitively time-consuming, and gets diminishing benefits from scaling to more compute resources. In this work, we conducted a comprehensive analysis on the AlphaFold training procedure based on Openfold, identified that inefficient communications and overhead-dominated computations were the key factors that prevented the AlphaFold training from effective scaling. We introduced ScaleFold, a systematic training method that incorporated optimizations specifically for these factors. ScaleFold successfully scaled the AlphaFold training to 2080 NVIDIA H100 GPUs with high resource utilization. In the MLPerf HPC v3.0 benchmark, ScaleFold finished the OpenFold benchmark in 7.51 minutes, shown over $6\times$ speedup than the baseline. For training the AlphaFold model from scratch, ScaleFold completed the pretraining in 10 hours, a significant improvement over the seven days required by the original AlphaFold pretraining baseline.
Reducing Activation Recomputation in Large Transformer Models
May 10, 2022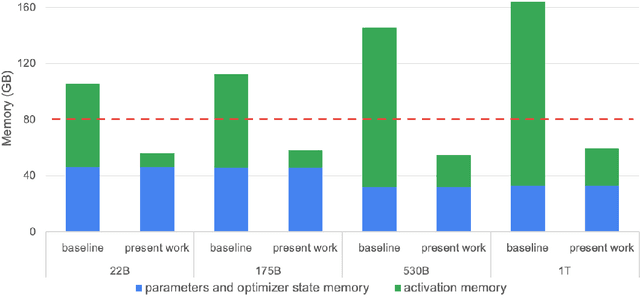

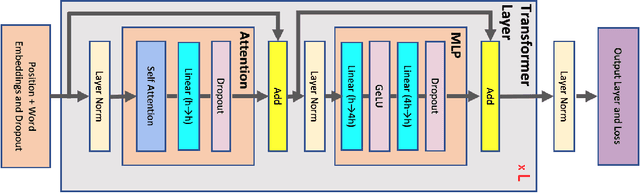
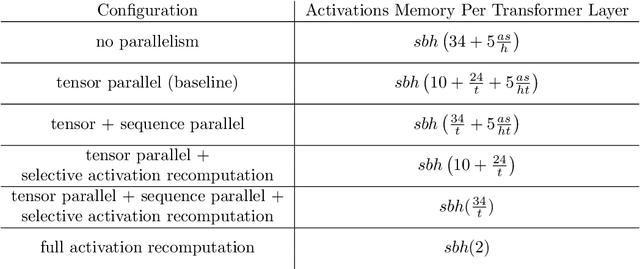
Training large transformer models is one of the most important computational challenges of modern AI. In this paper, we show how to significantly accelerate training of large transformer models by reducing activation recomputation. Activation recomputation is commonly used to work around memory capacity constraints. Rather than storing activations for backpropagation, they are traditionally recomputed, which saves memory but adds redundant compute. In this work, we show most of this redundant compute is unnecessary because we can reduce memory consumption sufficiently without it. We present two novel yet very simple techniques: sequence parallelism and selective activation recomputation. In conjunction with tensor parallelism, these techniques almost eliminate the need to recompute activations. We evaluate our approach on language models up to one trillion parameters in scale and show that our method reduces activation memory by 5x, while reducing execution time overhead from activation recomputation by over 90%. For example, when training a 530B parameter GPT-3 style model on 2240 NVIDIA A100 GPUs, we achieve a Model Flops Utilization of 54.2%, which is 29% faster than the 42.1% we achieve using recomputation. Our implementation will be available in both Megatron-LM and NeMo-Megatron.
Sparse Persistent RNNs: Squeezing Large Recurrent Networks On-Chip
Apr 26, 2018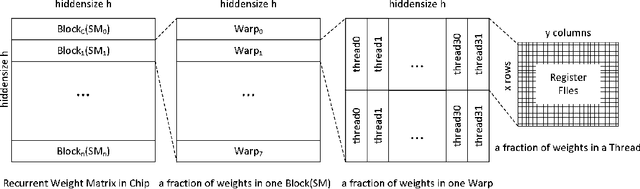
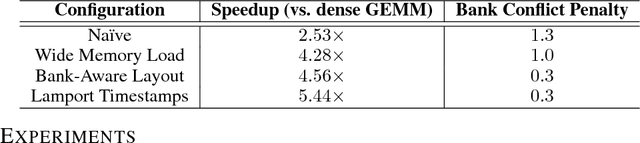
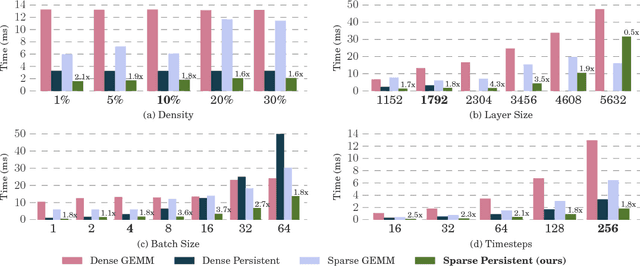
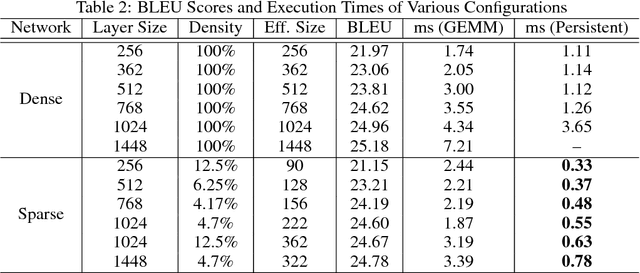
Recurrent Neural Networks (RNNs) are powerful tools for solving sequence-based problems, but their efficacy and execution time are dependent on the size of the network. Following recent work in simplifying these networks with model pruning and a novel mapping of work onto GPUs, we design an efficient implementation for sparse RNNs. We investigate several optimizations and tradeoffs: Lamport timestamps, wide memory loads, and a bank-aware weight layout. With these optimizations, we achieve speedups of over 6x over the next best algorithm for a hidden layer of size 2304, batch size of 4, and a density of 30%. Further, our technique allows for models of over 5x the size to fit on a GPU for a speedup of 2x, enabling larger networks to help advance the state-of-the-art. We perform case studies on NMT and speech recognition tasks in the appendix, accelerating their recurrent layers by up to 3x.