 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
Scalable Training of Mixture-of-Experts Models with Megatron Core
Mar 10, 2026Scaling Mixture-of-Experts (MoE) training introduces systems challenges absent in dense models. Because each token activates only a subset of experts, this sparsity allows total parameters to grow much faster than per-token computation, creating coupled constraints across memory, communication, and computation. Optimizing one dimension often shifts pressure to another, demanding co-design across the full system stack. We address these challenges for MoE training through integrated optimizations spanning memory (fine-grained recomputation, offloading, etc.), communication (optimized dispatchers, overlapping, etc.), and computation (Grouped GEMM, fusions, CUDA Graphs, etc.). The framework also provides Parallel Folding for flexible multi-dimensional parallelism, low-precision training support for FP8 and NVFP4, and efficient long-context training. On NVIDIA GB300 and GB200, it achieves 1,233/1,048 TFLOPS/GPU for DeepSeek-V3-685B and 974/919 TFLOPS/GPU for Qwen3-235B. As a performant, scalable, and production-ready open-source solution, it has been used across academia and industry for training MoE models ranging from billions to trillions of parameters on clusters scaling up to thousands of GPUs. This report explains how these techniques work, their trade-offs, and their interactions at the systems level, providing practical guidance for scaling MoE models with Megatron Core.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
MoE Parallel Folding: Heterogeneous Parallelism Mappings for Efficient Large-Scale MoE Model Training with Megatron Core
Apr 21, 2025



Mixture of Experts (MoE) models enhance neural network scalability by dynamically selecting relevant experts per input token, enabling larger model sizes while maintaining manageable computation costs. However, efficient training of large-scale MoE models across thousands of GPUs presents significant challenges due to limitations in existing parallelism strategies. We introduce an end-to-end training framework for large-scale MoE models that utilizes five-dimensional hybrid parallelism: Tensor Parallelism, Expert Parallelism, Context Parallelism, Data Parallelism, and Pipeline Parallelism. Central to our approach is MoE Parallel Folding, a novel strategy that decouples the parallelization of attention and MoE layers in Transformer models, allowing each layer type to adopt optimal parallel configurations. Additionally, we develop a flexible token-level dispatcher that supports both token-dropping and token-dropless MoE training across all five dimensions of parallelism. This dispatcher accommodates dynamic tensor shapes and coordinates different parallelism schemes for Attention and MoE layers, facilitating complex parallelism implementations. Our experiments demonstrate significant improvements in training efficiency and scalability. We achieve up to 49.3% Model Flops Utilization (MFU) for the Mixtral 8x22B model and 39.0% MFU for the Qwen2-57B-A14B model on H100 GPUs, outperforming existing methods. The framework scales efficiently up to 1,024 GPUs and maintains high performance with sequence lengths up to 128K tokens, validating its effectiveness for large-scale MoE model training. The code is available in Megatron-Core.
Llama 3 Meets MoE: Efficient Upcycling
Dec 13, 2024



Scaling large language models (LLMs) significantly improves performance but comes with prohibitive computational costs. Mixture-of-Experts (MoE) models offer an efficient alternative, increasing capacity without a proportional rise in compute requirements. However, training MoE models from scratch poses challenges like overfitting and routing instability. We present an efficient training recipe leveraging pre-trained dense checkpoints, training an 8-Expert Top-2 MoE model from Llama 3-8B with less than $1\%$ of typical pre-training compute. Our approach enhances downstream performance on academic benchmarks, achieving a $\textbf{2%}$ improvement in 0-shot accuracy on MMLU, while reaching a Model FLOPs Utilization (MFU) of $\textbf{46.8%}$ during training using our framework. We also integrate online upcycling in NeMo for seamless use of pre-trained weights, enabling cost-effective development of high-capacity MoE models.
Upcycling Large Language Models into Mixture of Experts
Oct 10, 2024



Upcycling pre-trained dense language models into sparse mixture-of-experts (MoE) models is an efficient approach to increase the model capacity of already trained models. However, optimal techniques for upcycling at scale remain unclear. In this work, we conduct an extensive study of upcycling methods and hyperparameters for billion-parameter scale language models. We propose a novel "virtual group" initialization scheme and weight scaling approach to enable upcycling into fine-grained MoE architectures. Through ablations, we find that upcycling outperforms continued dense model training. In addition, we show that softmax-then-topK expert routing improves over topK-then-softmax approach and higher granularity MoEs can help improve accuracy. Finally, we upcycled Nemotron-4 15B on 1T tokens and compared it to a continuously trained version of the same model on the same 1T tokens: the continuous trained model achieved 65.3% MMLU, whereas the upcycled model achieved 67.6%. Our results offer insights and best practices to effectively leverage upcycling for building MoE language models.
Gradient Sparification for Asynchronous Distributed Training
Oct 24, 2019
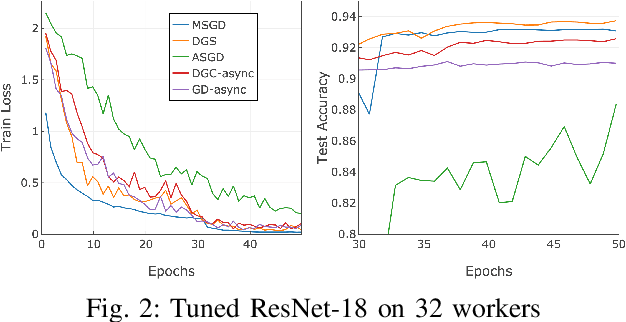


Modern large scale machine learning applications require stochastic optimization algorithms to be implemented on distributed computational architectures. A key bottleneck is the communication overhead for exchanging information, such as stochastic gradients, among different nodes. Recently, gradient sparsification techniques have been proposed to reduce communications cost and thus alleviate the network overhead. However, most of gradient sparsification techniques consider only synchronous parallelism and cannot be applied in asynchronous scenarios, such as asynchronous distributed training for federated learning at mobile devices. In this paper, we present a dual-way gradient sparsification approach (DGS) that is suitable for asynchronous distributed training. We let workers download model difference, instead of the global model, from the server, and the model difference information is also sparsified so that the information exchanged overhead is reduced by sparsifying the dual-way communication between the server and workers. To preserve accuracy under dual-way sparsification, we design a sparsification aware momentum (SAMomentum) to turn sparsification into adaptive batch size between each parameter. We conduct experiments at a cluster of 32 workers, and the results show that, with the same compression ratio but much lower communication cost, our approach can achieve better scalability and generalization ability.