 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Training of Mixture-of-Experts Models with Megatron Core
Mar 10, 2026Scaling Mixture-of-Experts (MoE) training introduces systems challenges absent in dense models. Because each token activates only a subset of experts, this sparsity allows total parameters to grow much faster than per-token computation, creating coupled constraints across memory, communication, and computation. Optimizing one dimension often shifts pressure to another, demanding co-design across the full system stack. We address these challenges for MoE training through integrated optimizations spanning memory (fine-grained recomputation, offloading, etc.), communication (optimized dispatchers, overlapping, etc.), and computation (Grouped GEMM, fusions, CUDA Graphs, etc.). The framework also provides Parallel Folding for flexible multi-dimensional parallelism, low-precision training support for FP8 and NVFP4, and efficient long-context training. On NVIDIA GB300 and GB200, it achieves 1,233/1,048 TFLOPS/GPU for DeepSeek-V3-685B and 974/919 TFLOPS/GPU for Qwen3-235B. As a performant, scalable, and production-ready open-source solution, it has been used across academia and industry for training MoE models ranging from billions to trillions of parameters on clusters scaling up to thousands of GPUs. This report explains how these techniques work, their trade-offs, and their interactions at the systems level, providing practical guidance for scaling MoE models with Megatron Core.
MoE Parallel Folding: Heterogeneous Parallelism Mappings for Efficient Large-Scale MoE Model Training with Megatron Core
Apr 21, 2025



Mixture of Experts (MoE) models enhance neural network scalability by dynamically selecting relevant experts per input token, enabling larger model sizes while maintaining manageable computation costs. However, efficient training of large-scale MoE models across thousands of GPUs presents significant challenges due to limitations in existing parallelism strategies. We introduce an end-to-end training framework for large-scale MoE models that utilizes five-dimensional hybrid parallelism: Tensor Parallelism, Expert Parallelism, Context Parallelism, Data Parallelism, and Pipeline Parallelism. Central to our approach is MoE Parallel Folding, a novel strategy that decouples the parallelization of attention and MoE layers in Transformer models, allowing each layer type to adopt optimal parallel configurations. Additionally, we develop a flexible token-level dispatcher that supports both token-dropping and token-dropless MoE training across all five dimensions of parallelism. This dispatcher accommodates dynamic tensor shapes and coordinates different parallelism schemes for Attention and MoE layers, facilitating complex parallelism implementations. Our experiments demonstrate significant improvements in training efficiency and scalability. We achieve up to 49.3% Model Flops Utilization (MFU) for the Mixtral 8x22B model and 39.0% MFU for the Qwen2-57B-A14B model on H100 GPUs, outperforming existing methods. The framework scales efficiently up to 1,024 GPUs and maintains high performance with sequence lengths up to 128K tokens, validating its effectiveness for large-scale MoE model training. The code is available in Megatron-Core.
Unsupervised Neural Machine Translation with Indirect Supervision
Apr 07, 2020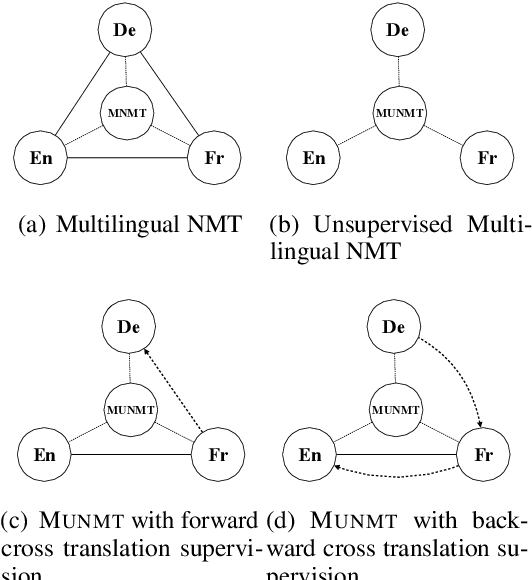

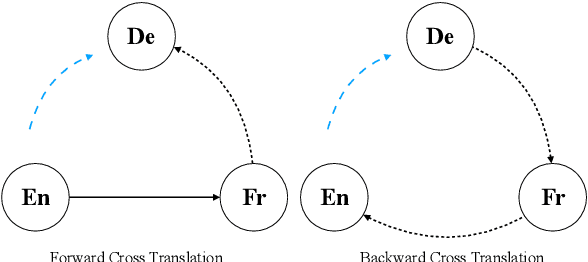
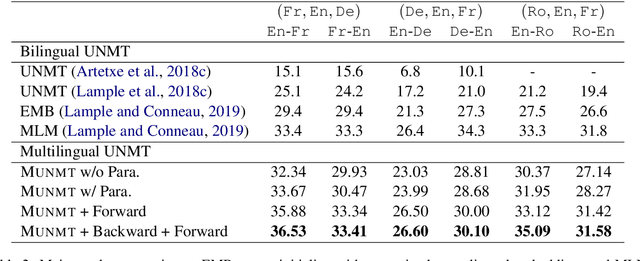
Neural machine translation~(NMT) is ineffective for zero-resource languages. Recent works exploring the possibility of unsupervised neural machine translation (UNMT) with only monolingual data can achieve promising results. However, there are still big gaps between UNMT and NMT with parallel supervision. In this work, we introduce a multilingual unsupervised NMT (\method) framework to leverage weakly supervised signals from high-resource language pairs to zero-resource translation directions. More specifically, for unsupervised language pairs \texttt{En-De}, we can make full use of the information from parallel dataset \texttt{En-Fr} to jointly train the unsupervised translation directions all in one model. \method is based on multilingual models which require no changes to the standard unsupervised NMT. Empirical results demonstrate that \method significantly improves the translation quality by more than 3 BLEU score on six benchmark unsupervised translation directions.
Memorizing All for Implicit Discourse Relation Recognition
Aug 29, 2019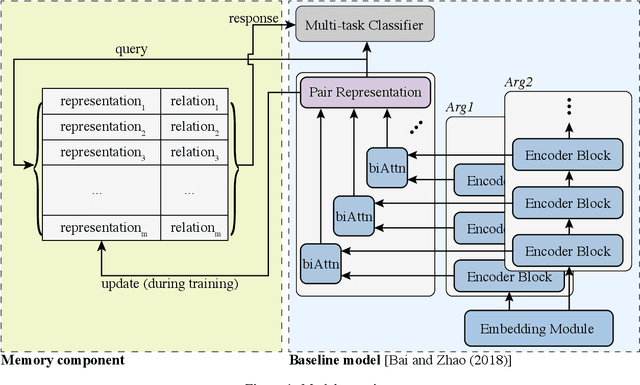

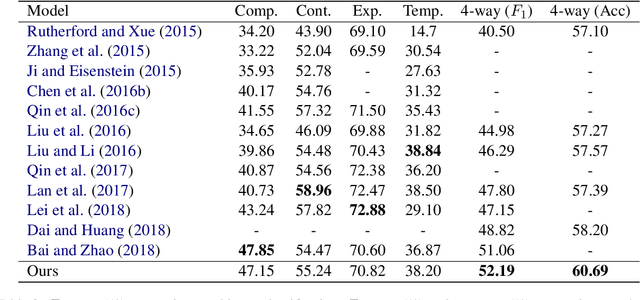
Implicit discourse relation recognition is a challenging task due to the absence of the necessary informative clue from explicit connectives. The prediction of relations requires a deep understanding of the semantic meanings of sentence pairs. As implicit discourse relation recognizer has to carefully tackle the semantic similarity of the given sentence pairs and the severe data sparsity issue exists in the meantime, it is supposed to be beneficial from mastering the entire training data. Thus in this paper, we propose a novel memory mechanism to tackle the challenges for further performance improvement. The memory mechanism is adequately memorizing information by pairing representations and discourse relations of all training instances, which right fills the slot of the data-hungry issue in the current implicit discourse relation recognizer. Our experiments show that our full model with memorizing the entire training set reaches new state-of-the-art against strong baselines, which especially for the first time exceeds the milestone of 60% accuracy in the 4-way task.
Deep Enhanced Representation for Implicit Discourse Relation Recognition
Jul 13, 2018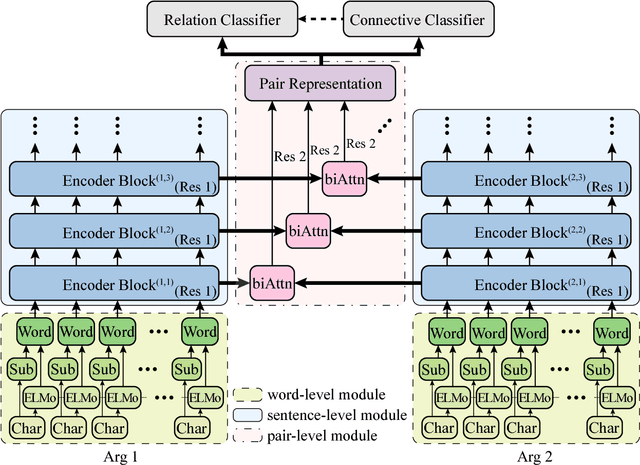
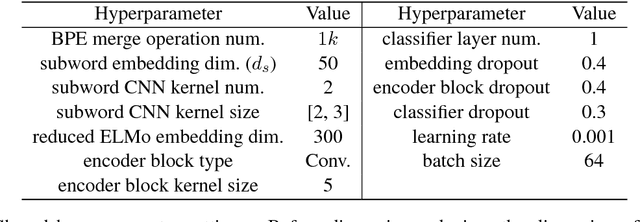
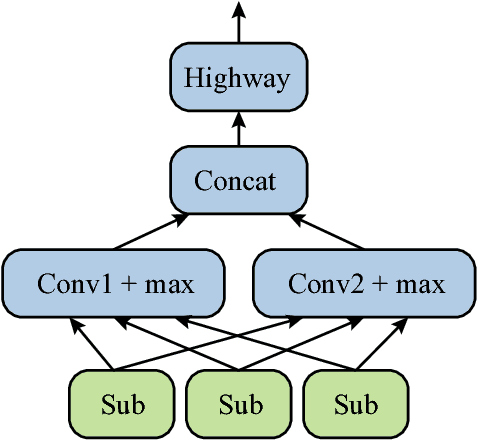

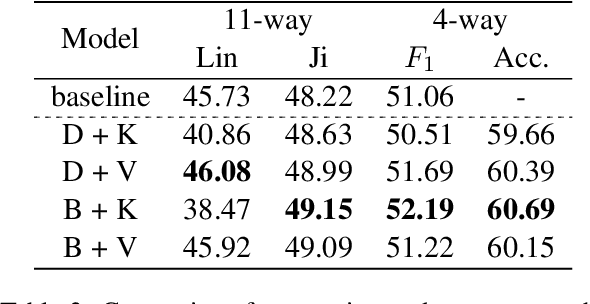
Implicit discourse relation recognition is a challenging task as the relation prediction without explicit connectives in discourse parsing needs understanding of text spans and cannot be easily derived from surface features from the input sentence pairs. Thus, properly representing the text is very crucial to this task. In this paper, we propose a model augmented with different grained text representations, including character, subword, word, sentence, and sentence pair levels. The proposed deeper model is evaluated on the benchmark treebank and achieves state-of-the-art accuracy with greater than 48% in 11-way and $F_1$ score greater than 50% in 4-way classifications for the first time according to our best knowledge.