 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative Foundation Model for Chest Radiography
Sep 04, 2025The scarcity of well-annotated diverse medical images is a major hurdle for developing reliable AI models in healthcare. Substantial technical advances have been made in generative foundation models for natural images. Here we develop `ChexGen', a generative vision-language foundation model that introduces a unified framework for text-, mask-, and bounding box-guided synthesis of chest radiographs. Built upon the latent diffusion transformer architecture, ChexGen was pretrained on the largest curated chest X-ray dataset to date, consisting of 960,000 radiograph-report pairs. ChexGen achieves accurate synthesis of radiographs through expert evaluations and quantitative metrics. We demonstrate the utility of ChexGen for training data augmentation and supervised pretraining, which led to performance improvements across disease classification, detection, and segmentation tasks using a small fraction of training data. Further, our model enables the creation of diverse patient cohorts that enhance model fairness by detecting and mitigating demographic biases. Our study supports the transformative role of generative foundation models in building more accurate, data-efficient, and equitable medical AI systems.
Radiance Field Learners As UAV First-Person Viewers
Aug 10, 2024
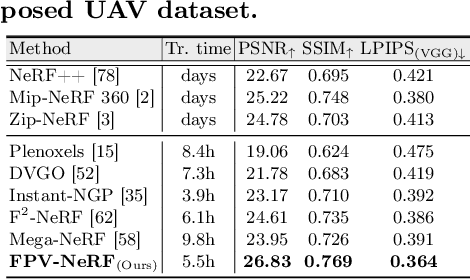
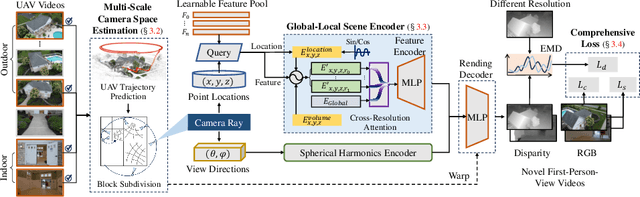
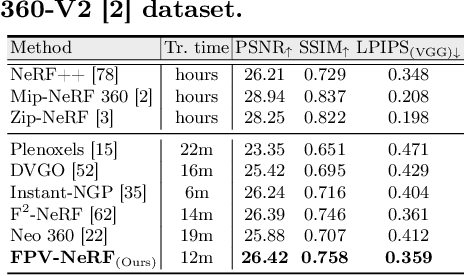
First-Person-View (FPV) holds immense potential for revolutionizing the trajectory of Unmanned Aerial Vehicles (UAVs), offering an exhilarating avenue for navigating complex building structures. Yet, traditional Neural Radiance Field (NeRF) methods face challenges such as sampling single points per iteration and requiring an extensive array of views for supervision. UAV videos exacerbate these issues with limited viewpoints and significant spatial scale variations, resulting in inadequate detail rendering across diverse scales. In response, we introduce FPV-NeRF, addressing these challenges through three key facets: (1) Temporal consistency. Leveraging spatio-temporal continuity ensures seamless coherence between frames; (2) Global structure. Incorporating various global features during point sampling preserves space integrity; (3) Local granularity. Employing a comprehensive framework and multi-resolution supervision for multi-scale scene feature representation tackles the intricacies of UAV video spatial scales. Additionally, due to the scarcity of publicly available FPV videos, we introduce an innovative view synthesis method using NeRF to generate FPV perspectives from UAV footage, enhancing spatial perception for drones. Our novel dataset spans diverse trajectories, from outdoor to indoor environments, in the UAV domain, differing significantly from traditional NeRF scenarios. Through extensive experiments encompassing both interior and exterior building structures, FPV-NeRF demonstrates a superior understanding of the UAV flying space, outperforming state-of-the-art methods in our curated UAV dataset. Explore our project page for further insights: https://fpv-nerf.github.io/.
* Accepted to ECCV 2024
Frequency-Controlled Diffusion Model for Versatile Text-Guided Image-to-Image Translation
Jul 03, 2024



Recently, large-scale text-to-image (T2I) diffusion models have emerged as a powerful tool for image-to-image translation (I2I), allowing open-domain image translation via user-provided text prompts. This paper proposes frequency-controlled diffusion model (FCDiffusion), an end-to-end diffusion-based framework that contributes a novel solution to text-guided I2I from a frequency-domain perspective. At the heart of our framework is a feature-space frequency-domain filtering module based on Discrete Cosine Transform, which filters the latent features of the source image in the DCT domain, yielding filtered image features bearing different DCT spectral bands as different control signals to the pre-trained Latent Diffusion Model. We reveal that control signals of different DCT spectral bands bridge the source image and the T2I generated image in different correlations (e.g., style, structure, layout, contour, etc.), and thus enable versatile I2I applications emphasizing different I2I correlations, including style-guided content creation, image semantic manipulation, image scene translation, and image style translation. Different from related approaches, FCDiffusion establishes a unified text-guided I2I framework suitable for diverse image translation tasks simply by switching among different frequency control branches at inference time. The effectiveness and superiority of our method for text-guided I2I are demonstrated with extensive experiments both qualitatively and quantitatively. The code is publicly available at: https://github.com/XiangGao1102/FCDiffusion.
* Proceedings of the 38th AAAI Conference on Artificial Intelligence (AAAI 2024)
Federated contrastive learning models for prostate cancer diagnosis and Gleason grading
Feb 17, 2023
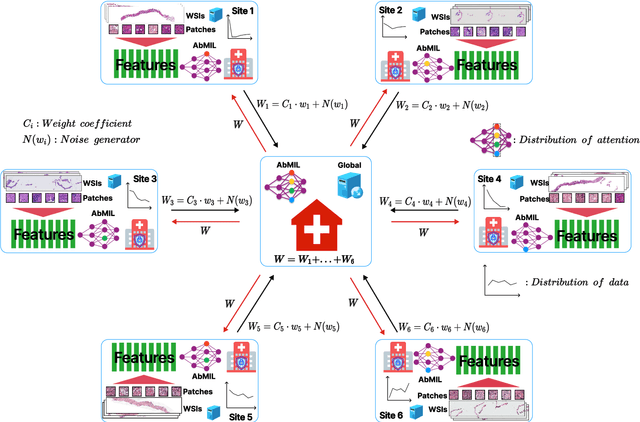
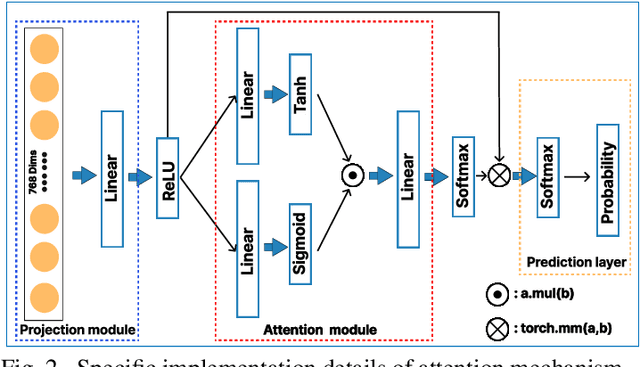
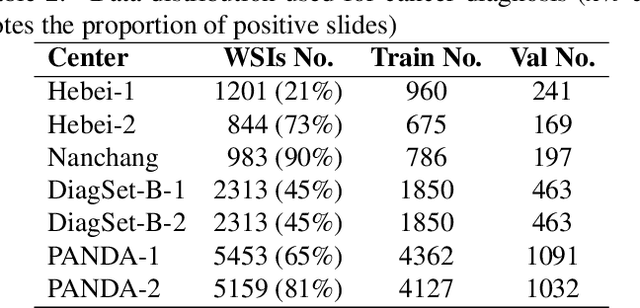
The application effect of artificial intelligence (AI) in the field of medical imaging is remarkable. Robust AI model training requires large datasets, but data collection faces communication, ethics, and privacy protection constraints. Fortunately, federated learning can solve the above problems by coordinating multiple clients to train the model without sharing the original data. In this study, we design a federated contrastive learning framework (FCL) for large-scale pathology images and the heterogeneity challenges. It enhances the model's generalization ability by maximizing the attention consistency between the local client and server models. To alleviate the privacy leakage problem when transferring parameters and verify the robustness of FCL, we use differential privacy to further protect the model by adding noise. We evaluate the effectiveness of FCL on the cancer diagnosis task and Gleason grading task on 19,635 prostate cancer WSIs from multiple clients. In the diagnosis task, the average AUC of 7 clients is 95% when the categories are relatively balanced, and our FCL achieves 97%. In the Gleason grading task, the average Kappa of 6 clients is 0.74, and the Kappa of FCL reaches 0.84. Furthermore, we also validate the robustness of the model on external datasets(one public dataset and two private datasets). In addition, to better explain the classification effect of the model, we show whether the model focuses on the lesion area by drawing a heatmap. Finally, FCL brings a robust, accurate, low-cost AI training model to biomedical research, effectively protecting medical data privacy.
Memorizing All for Implicit Discourse Relation Recognition
Aug 29, 2019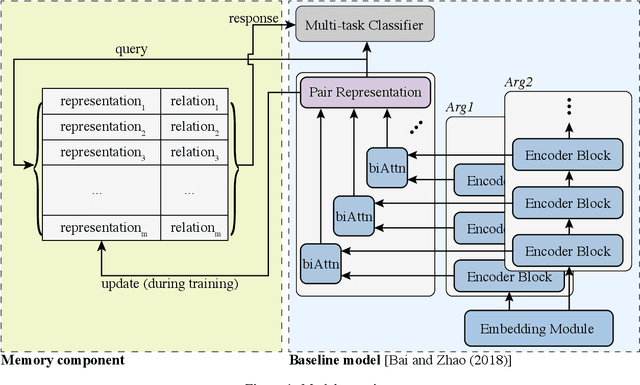

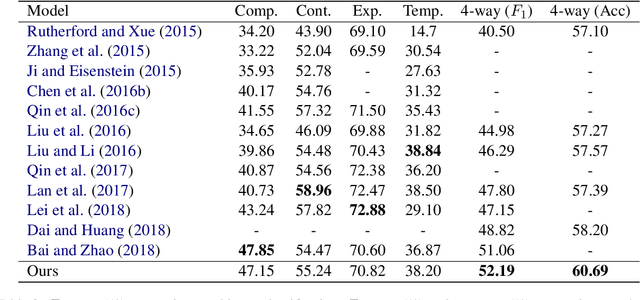
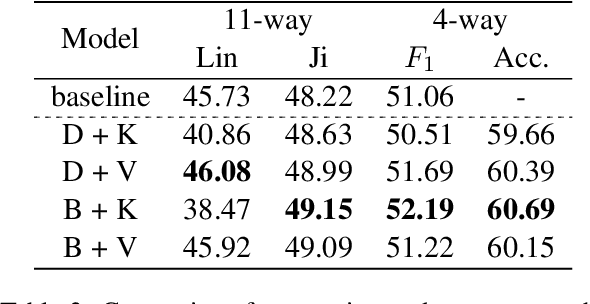
Implicit discourse relation recognition is a challenging task due to the absence of the necessary informative clue from explicit connectives. The prediction of relations requires a deep understanding of the semantic meanings of sentence pairs. As implicit discourse relation recognizer has to carefully tackle the semantic similarity of the given sentence pairs and the severe data sparsity issue exists in the meantime, it is supposed to be beneficial from mastering the entire training data. Thus in this paper, we propose a novel memory mechanism to tackle the challenges for further performance improvement. The memory mechanism is adequately memorizing information by pairing representations and discourse relations of all training instances, which right fills the slot of the data-hungry issue in the current implicit discourse relation recognizer. Our experiments show that our full model with memorizing the entire training set reaches new state-of-the-art against strong baselines, which especially for the first time exceeds the milestone of 60% accuracy in the 4-way task.