 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadiance Field Learners As UAV First-Person Viewers
Aug 10, 2024
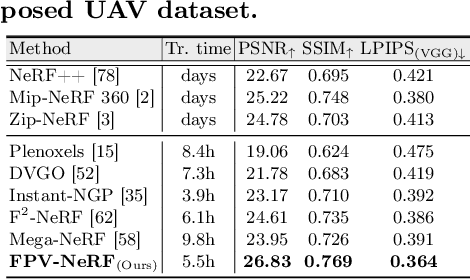
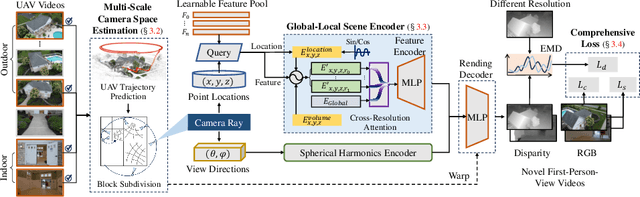
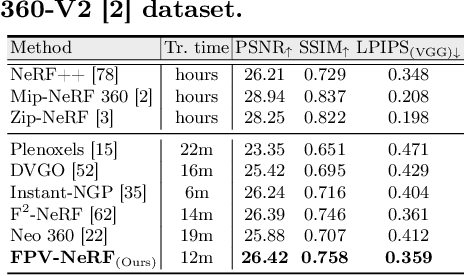
First-Person-View (FPV) holds immense potential for revolutionizing the trajectory of Unmanned Aerial Vehicles (UAVs), offering an exhilarating avenue for navigating complex building structures. Yet, traditional Neural Radiance Field (NeRF) methods face challenges such as sampling single points per iteration and requiring an extensive array of views for supervision. UAV videos exacerbate these issues with limited viewpoints and significant spatial scale variations, resulting in inadequate detail rendering across diverse scales. In response, we introduce FPV-NeRF, addressing these challenges through three key facets: (1) Temporal consistency. Leveraging spatio-temporal continuity ensures seamless coherence between frames; (2) Global structure. Incorporating various global features during point sampling preserves space integrity; (3) Local granularity. Employing a comprehensive framework and multi-resolution supervision for multi-scale scene feature representation tackles the intricacies of UAV video spatial scales. Additionally, due to the scarcity of publicly available FPV videos, we introduce an innovative view synthesis method using NeRF to generate FPV perspectives from UAV footage, enhancing spatial perception for drones. Our novel dataset spans diverse trajectories, from outdoor to indoor environments, in the UAV domain, differing significantly from traditional NeRF scenarios. Through extensive experiments encompassing both interior and exterior building structures, FPV-NeRF demonstrates a superior understanding of the UAV flying space, outperforming state-of-the-art methods in our curated UAV dataset. Explore our project page for further insights: https://fpv-nerf.github.io/.
* Accepted to ECCV 2024
Solve the Puzzle of Instance Segmentation in Videos: A Weakly Supervised Framework with Spatio-Temporal Collaboration
Dec 15, 2022



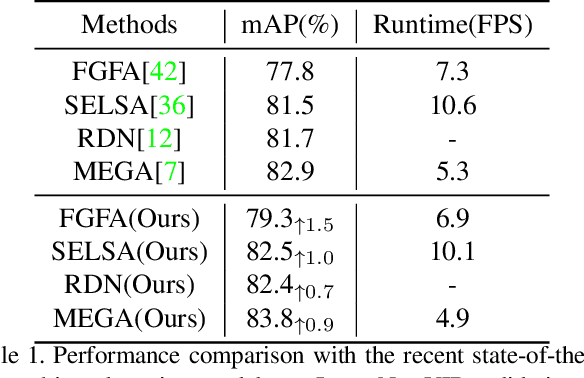
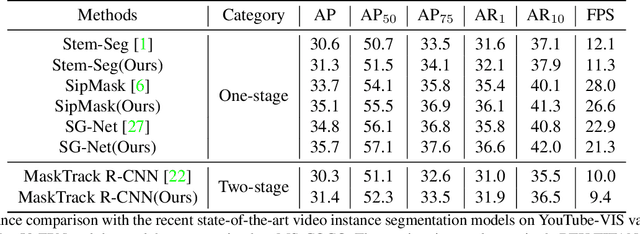
Instance segmentation in videos, which aims to segment and track multiple objects in video frames, has garnered a flurry of research attention in recent years. In this paper, we present a novel weakly supervised framework with \textbf{S}patio-\textbf{T}emporal \textbf{C}ollaboration for instance \textbf{Seg}mentation in videos, namely \textbf{STC-Seg}. Concretely, STC-Seg demonstrates four contributions. First, we leverage the complementary representations from unsupervised depth estimation and optical flow to produce effective pseudo-labels for training deep networks and predicting high-quality instance masks. Second, to enhance the mask generation, we devise a puzzle loss, which enables end-to-end training using box-level annotations. Third, our tracking module jointly utilizes bounding-box diagonal points with spatio-temporal discrepancy to model movements, which largely improves the robustness to different object appearances. Finally, our framework is flexible and enables image-level instance segmentation methods to operate the video-level task. We conduct an extensive set of experiments on the KITTI MOTS and YT-VIS datasets. Experimental results demonstrate that our method achieves strong performance and even outperforms fully supervised TrackR-CNN and MaskTrack R-CNN. We believe that STC-Seg can be a valuable addition to the community, as it reflects the tip of an iceberg about the innovative opportunities in the weakly supervised paradigm for instance segmentation in videos.
GL-RG: Global-Local Representation Granularity for Video Captioning
May 22, 2022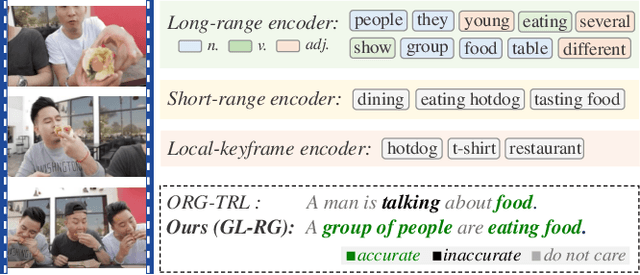
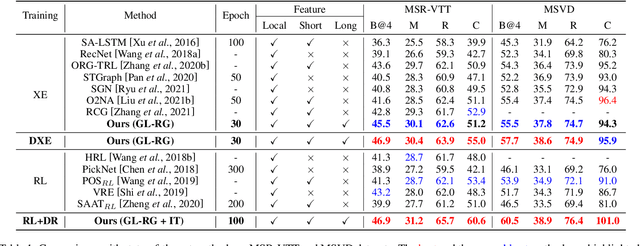
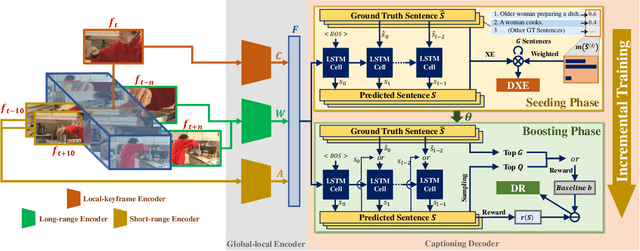
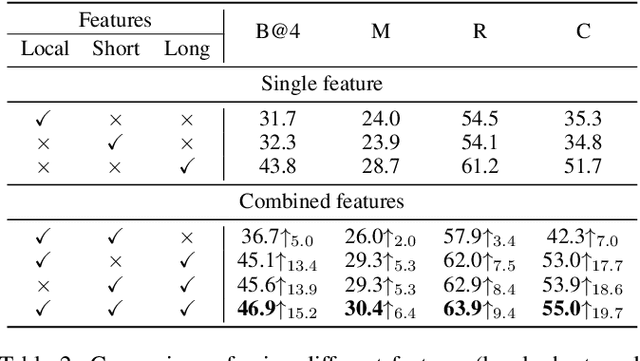
Video captioning is a challenging task as it needs to accurately transform visual understanding into natural language description. To date, state-of-the-art methods inadequately model global-local representation across video frames for caption generation, leaving plenty of room for improvement. In this work, we approach the video captioning task from a new perspective and propose a GL-RG framework for video captioning, namely a \textbf{G}lobal-\textbf{L}ocal \textbf{R}epresentation \textbf{G}ranularity. Our GL-RG demonstrates three advantages over the prior efforts: 1) we explicitly exploit extensive visual representations from different video ranges to improve linguistic expression; 2) we devise a novel global-local encoder to produce rich semantic vocabulary to obtain a descriptive granularity of video contents across frames; 3) we develop an incremental training strategy which organizes model learning in an incremental fashion to incur an optimal captioning behavior. Experimental results on the challenging MSR-VTT and MSVD datasets show that our DL-RG outperforms recent state-of-the-art methods by a significant margin. Code is available at \url{https://github.com/ylqi/GL-RG}.
TF-Blender: Temporal Feature Blender for Video Object Detection
Aug 12, 2021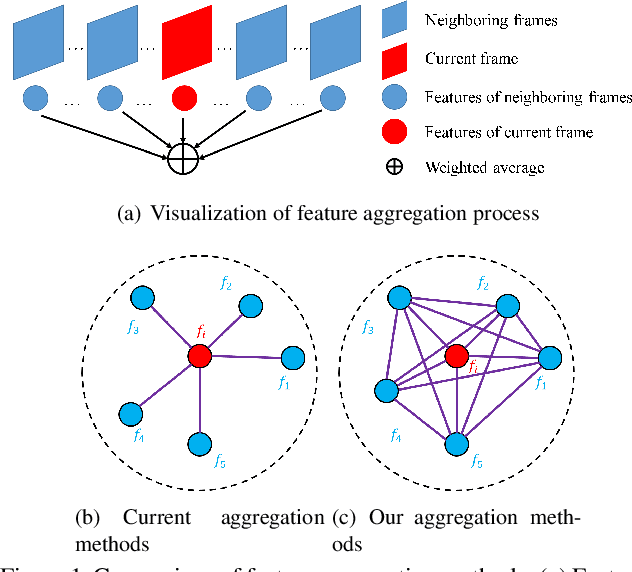
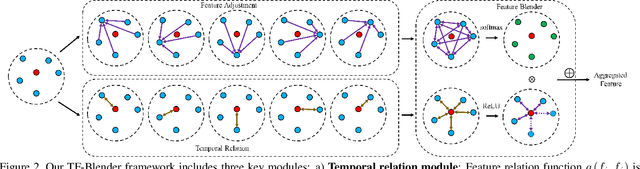
Video objection detection is a challenging task because isolated video frames may encounter appearance deterioration, which introduces great confusion for detection. One of the popular solutions is to exploit the temporal information and enhance per-frame representation through aggregating features from neighboring frames. Despite achieving improvements in detection, existing methods focus on the selection of higher-level video frames for aggregation rather than modeling lower-level temporal relations to increase the feature representation. To address this limitation, we propose a novel solution named TF-Blender,which includes three modules: 1) Temporal relation mod-els the relations between the current frame and its neighboring frames to preserve spatial information. 2). Feature adjustment enriches the representation of every neigh-boring feature map; 3) Feature blender combines outputs from the first two modules and produces stronger features for the later detection tasks. For its simplicity, TF-Blender can be effortlessly plugged into any detection network to improve detection behavior. Extensive evaluations on ImageNet VID and YouTube-VIS benchmarks indicate the performance guarantees of using TF-Blender on recent state-of-the-art methods.
Hierarchical Attention Fusion for Geo-Localization
Feb 18, 2021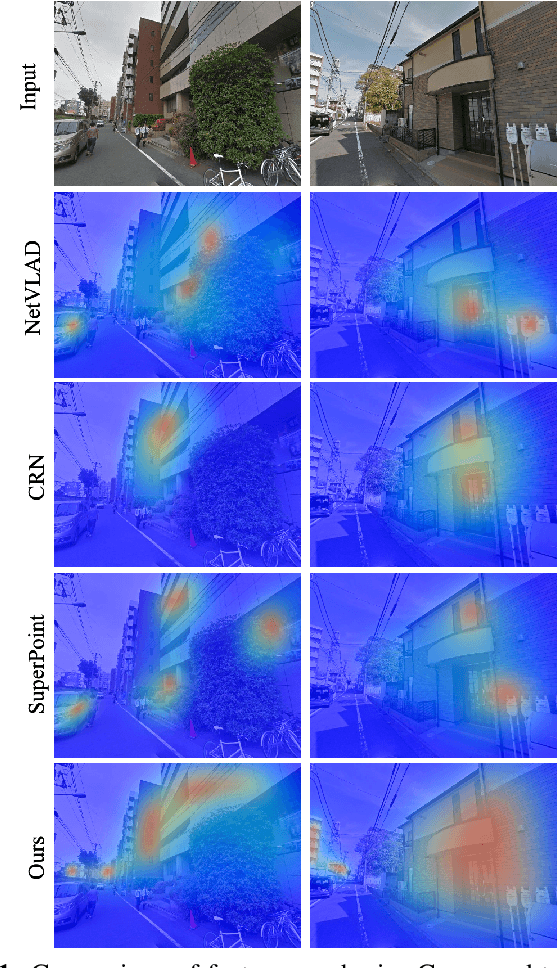
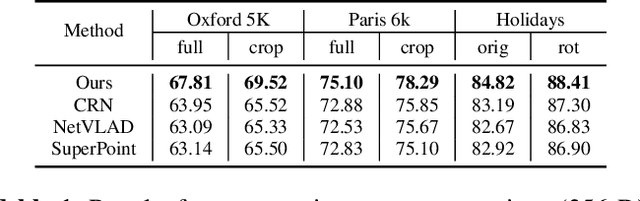
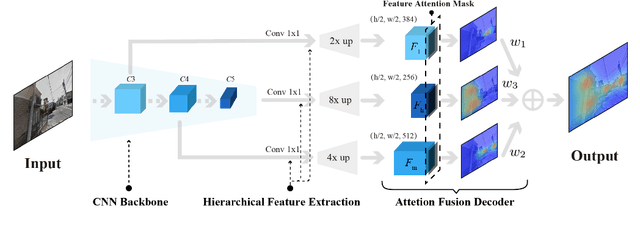

Geo-localization is a critical task in computer vision. In this work, we cast the geo-localization as a 2D image retrieval task. Current state-of-the-art methods for 2D geo-localization are not robust to locate a scene with drastic scale variations because they only exploit features from one semantic level for image representations. To address this limitation, we introduce a hierarchical attention fusion network using multi-scale features for geo-localization. We extract the hierarchical feature maps from a convolutional neural network (CNN) and organically fuse the extracted features for image representations. Our training is self-supervised using adaptive weights to control the attention of feature emphasis from each hierarchical level. Evaluation results on the image retrieval and the large-scale geo-localization benchmarks indicate that our method outperforms the existing state-of-the-art methods. Code is available here: \url{https://github.com/YanLiqi/HAF}.
DenserNet: Weakly Supervised Visual Localization Using Multi-scale Feature Aggregation
Dec 31, 2020

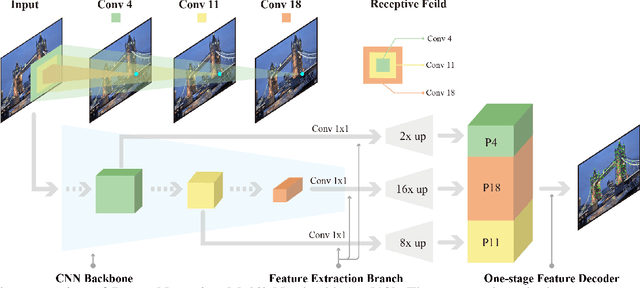
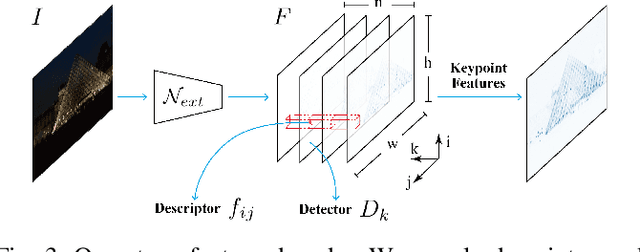
In this work, we introduce a Denser Feature Network (DenserNet) for visual localization. Our work provides three principal contributions. First, we develop a convolutional neural network (CNN) architecture which aggregates feature maps at different semantic levels for image representations. Using denser feature maps, our method can produce more keypoint features and increase image retrieval accuracy. Second, our model is trained end-to-end without pixel-level annotation other than positive and negative GPS-tagged image pairs. We use a weakly supervised triplet ranking loss to learn discriminative features and encourage keypoint feature repeatability for image representation. Finally, our method is computationally efficient as our architecture has shared features and parameters during computation. Our method can perform accurate large-scale localization under challenging conditions while remaining the computational constraint. Extensive experiment results indicate that our method sets a new state-of-the-art on four challenging large-scale localization benchmarks and three image retrieval benchmarks.
Multimodal Aggregation Approach for Memory Vision-Voice Indoor Navigation with Meta-Learning
Sep 01, 2020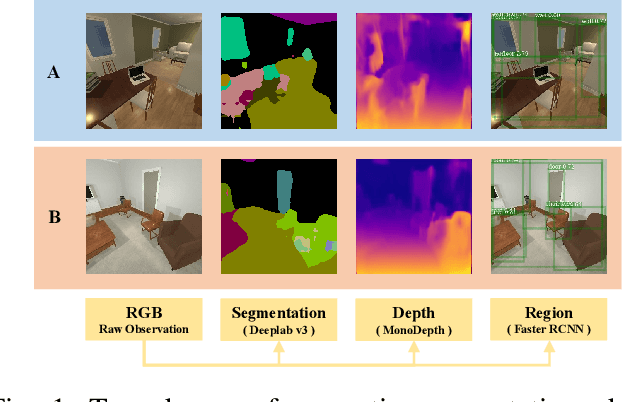
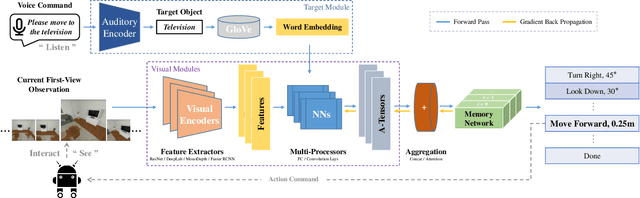
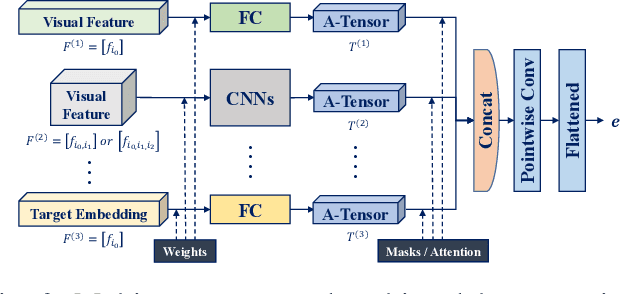
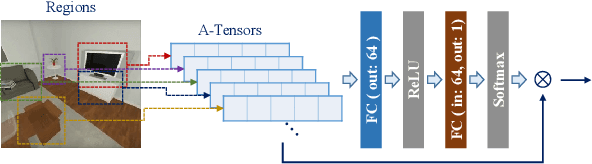
Vision and voice are two vital keys for agents' interaction and learning. In this paper, we present a novel indoor navigation model called Memory Vision-Voice Indoor Navigation (MVV-IN), which receives voice commands and analyzes multimodal information of visual observation in order to enhance robots' environment understanding. We make use of single RGB images taken by a first-view monocular camera. We also apply a self-attention mechanism to keep the agent focusing on key areas. Memory is important for the agent to avoid repeating certain tasks unnecessarily and in order for it to adapt adequately to new scenes, therefore, we make use of meta-learning. We have experimented with various functional features extracted from visual observation. Comparative experiments prove that our methods outperform state-of-the-art baselines.
Crowd Video Captioning
Nov 13, 2019
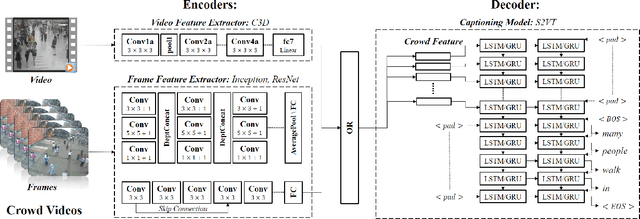

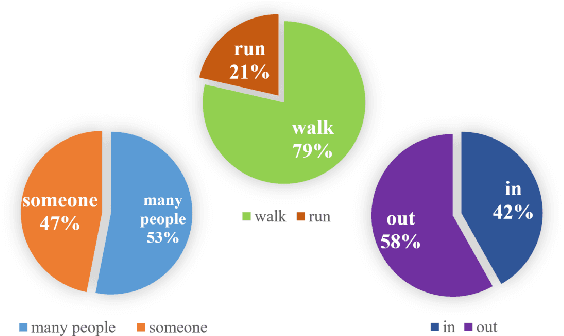
Describing a video automatically with natural language is a challenging task in the area of computer vision. In most cases, the on-site situation of great events is reported in news, but the situation of the off-site spectators in the entrance and exit is neglected which also arouses people's interest. Since the deployment of reporters in the entrance and exit costs lots of manpower, how to automatically describe the behavior of a crowd of off-site spectators is significant and remains a problem. To tackle this problem, we propose a new task called crowd video captioning (CVC) which aims to describe the crowd of spectators. We also provide baseline methods for this task and evaluate them on the dataset WorldExpo'10. Our experimental results show that captioning models have a fairly deep understanding of the crowd in video and perform satisfactorily in the CVC task.