 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchFlow: Leveraging a Flow-Based Model with Patch Features
Feb 05, 2026Die casting plays a crucial role across various industries due to its ability to craft intricate shapes with high precision and smooth surfaces. However, surface defects remain a major issue that impedes die casting quality control. Recently, computer vision techniques have been explored to automate and improve defect detection. In this work, we combine local neighbor-aware patch features with a normalizing flow model and bridge the gap between the generic pretrained feature extractor and industrial product images by introducing an adapter module to increase the efficiency and accuracy of automated anomaly detection. Compared to state-of-the-art methods, our approach reduces the error rate by 20\% on the MVTec AD dataset, achieving an image-level AUROC of 99.28\%. Our approach has also enhanced performance on the VisA dataset , achieving an image-level AUROC of 96.48\%. Compared to the state-of-the-art models, this represents a 28.2\% reduction in error. Additionally, experiments on a proprietary die casting dataset yield an accuracy of 95.77\% for anomaly detection, without requiring any anomalous samples for training. Our method illustrates the potential of leveraging computer vision and deep learning techniques to advance inspection capabilities for the die casting industry
CORP: Closed-Form One-shot Representation-Preserving Structured Pruning for Vision Transformers
Feb 05, 2026Vision Transformers achieve strong accuracy but incur high compute and memory cost. Structured pruning can reduce inference cost, but most methods rely on retraining or multi-stage optimization. These requirements limit post-training deployment. We propose \textbf{CORP}, a closed-form one-shot structured pruning framework for Vision Transformers. CORP removes entire MLP hidden dimensions and attention substructures without labels, gradients, or fine-tuning. It operates under strict post-training constraints using only a small unlabeled calibration set. CORP formulates structured pruning as a representation recovery problem. It models removed activations and attention logits as affine functions of retained components and derives closed-form ridge regression solutions that fold compensation into model weights. This minimizes expected representation error under the calibration distribution. Experiments on ImageNet with DeiT models show strong redundancy in MLP and attention representations. Without compensation, one-shot structured pruning causes severe accuracy degradation. With CORP, models preserve accuracy under aggressive sparsity. On DeiT-Huge, CORP retains 82.8\% Top-1 accuracy after pruning 50\% of both MLP and attention structures. CORP completes pruning in under 20 minutes on a single GPU and delivers substantial real-world efficiency gains.
Multimodal Remote Sensing Scene Classification Using VLMs and Dual-Cross Attention Networks
Dec 03, 2024
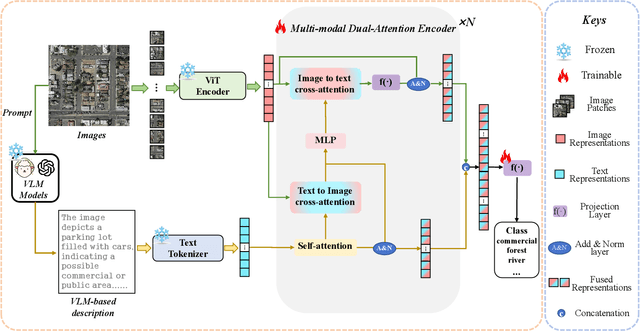
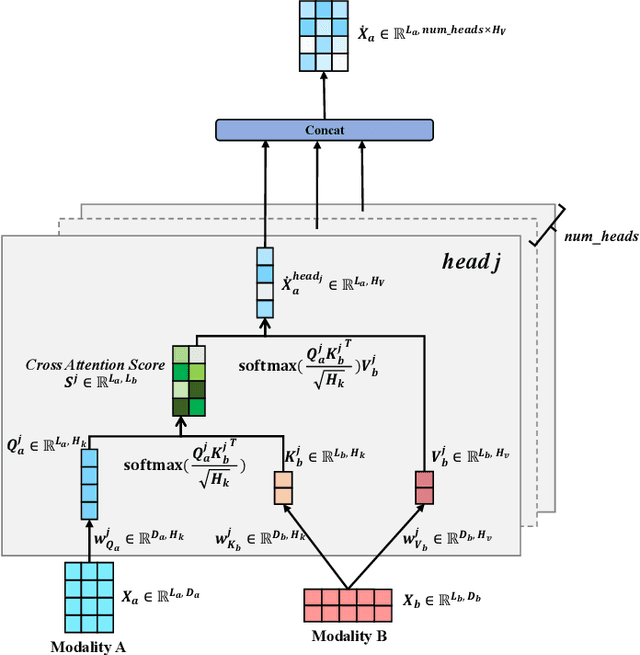
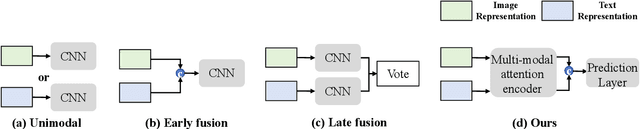
Remote sensing scene classification (RSSC) is a critical task with diverse applications in land use and resource management. While unimodal image-based approaches show promise, they often struggle with limitations such as high intra-class variance and inter-class similarity. Incorporating textual information can enhance classification by providing additional context and semantic understanding, but manual text annotation is labor-intensive and costly. In this work, we propose a novel RSSC framework that integrates text descriptions generated by large vision-language models (VLMs) as an auxiliary modality without incurring expensive manual annotation costs. To fully leverage the latent complementarities between visual and textual data, we propose a dual cross-attention-based network to fuse these modalities into a unified representation. Extensive experiments with both quantitative and qualitative evaluation across five RSSC datasets demonstrate that our framework consistently outperforms baseline models. We also verify the effectiveness of VLM-generated text descriptions compared to human-annotated descriptions. Additionally, we design a zero-shot classification scenario to show that the learned multimodal representation can be effectively utilized for unseen class classification. This research opens new opportunities for leveraging textual information in RSSC tasks and provides a promising multimodal fusion structure, offering insights and inspiration for future studies. Code is available at: https://github.com/CJR7/MultiAtt-RSSC
Unsupervised Machine Learning for Detecting and Locating Human-Made Objects in 3D Point Cloud
Oct 25, 2024A 3D point cloud is an unstructured, sparse, and irregular dataset, typically collected by airborne LiDAR systems over a geological region. Laser pulses emitted from these systems reflect off objects both on and above the ground, resulting in a dataset containing the longitude, latitude, and elevation of each point, as well as information about the corresponding laser pulse strengths. A widely studied research problem, addressed in many previous works, is ground filtering, which involves partitioning the points into ground and non-ground subsets. This research introduces a novel task: detecting and identifying human-made objects amidst natural tree structures. This task is performed on the subset of non-ground points derived from the ground filtering stage. Marked Point Fields (MPFs) are used as models well-suited to these tasks. The proposed methodology consists of three stages: ground filtering, local information extraction (LIE), and clustering. In the ground filtering stage, a statistical method called One-Sided Regression (OSR) is introduced, addressing the limitations of prior ground filtering methods on uneven terrains. In the LIE stage, unsupervised learning methods are lacking. To mitigate this, a kernel-based method for the Hessian matrix of the MPF is developed. In the clustering stage, the Gaussian Mixture Model (GMM) is applied to the results of the LIE stage to partition the non-ground points into trees and human-made objects. The underlying assumption is that LiDAR points from trees exhibit a three-dimensional distribution, while those from human-made objects follow a two-dimensional distribution. The Hessian matrix of the MPF effectively captures this distinction. Experimental results demonstrate that the proposed ground filtering method outperforms previous techniques, and the LIE method successfully distinguishes between points representing trees and human-made objects.
Hyper-STTN: Social Group-aware Spatial-Temporal Transformer Network for Human Trajectory Prediction with Hypergraph Reasoning
Jan 12, 2024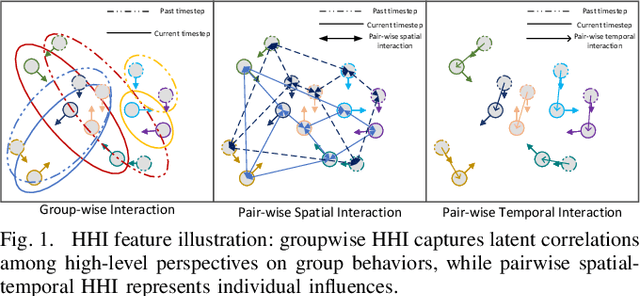
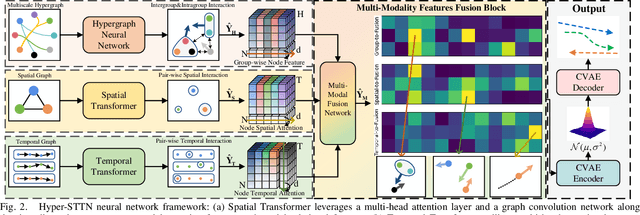
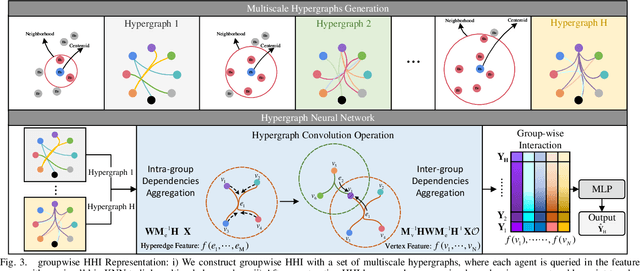
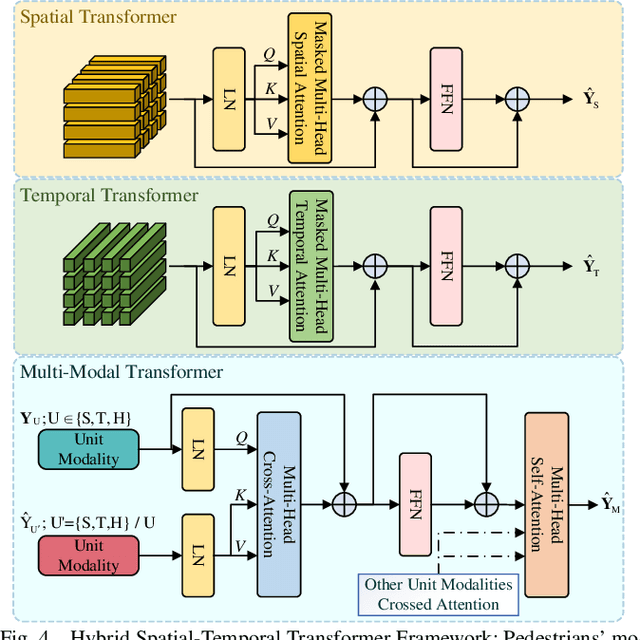
Predicting crowded intents and trajectories is crucial in varouls real-world applications, including service robots and autonomous vehicles. Understanding environmental dynamics is challenging, not only due to the complexities of modeling pair-wise spatial and temporal interactions but also the diverse influence of group-wise interactions. To decode the comprehensive pair-wise and group-wise interactions in crowded scenarios, we introduce Hyper-STTN, a Hypergraph-based Spatial-Temporal Transformer Network for crowd trajectory prediction. In Hyper-STTN, crowded group-wise correlations are constructed using a set of multi-scale hypergraphs with varying group sizes, captured through random-walk robability-based hypergraph spectral convolution. Additionally, a spatial-temporal transformer is adapted to capture pedestrians' pair-wise latent interactions in spatial-temporal dimensions. These heterogeneous group-wise and pair-wise are then fused and aligned though a multimodal transformer network. Hyper-STTN outperformes other state-of-the-art baselines and ablation models on 5 real-world pedestrian motion datasets.
Affective Workload Allocation for Multi-human Multi-robot Teams
Mar 18, 2023



The interaction and collaboration between humans and multiple robots represent a novel field of research known as human multi-robot systems. Adequately designed systems within this field allow teams composed of both humans and robots to work together effectively on tasks such as monitoring, exploration, and search and rescue operations. This paper presents a deep reinforcement learning-based affective workload allocation controller specifically for multi-human multi-robot teams. The proposed controller can dynamically reallocate workloads based on the performance of the operators during collaborative missions with multi-robot systems. The operators' performances are evaluated through the scores of a self-reported questionnaire (i.e., subjective measurement) and the results of a deep learning-based cognitive workload prediction algorithm that uses physiological and behavioral data (i.e., objective measurement). To evaluate the effectiveness of the proposed controller, we use a multi-human multi-robot CCTV monitoring task as an example and carry out comprehensive real-world experiments with 32 human subjects for both quantitative measurement and qualitative analysis. Our results demonstrate the performance and effectiveness of the proposed controller and highlight the importance of incorporating both subjective and objective measurements of the operators' cognitive workload as well as seeking consent for workload transitions, to enhance the performance of multi-human multi-robot teams.
Husformer: A Multi-Modal Transformer for Multi-Modal Human State Recognition
Sep 30, 2022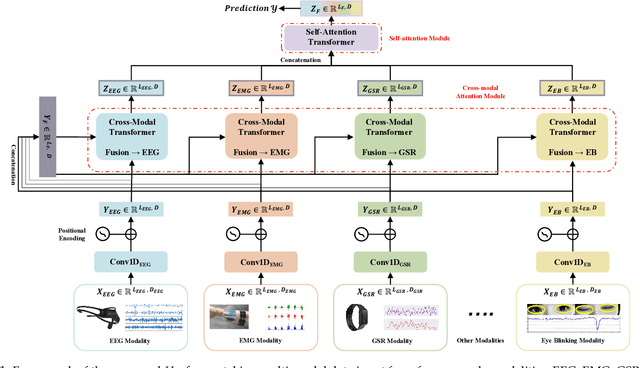
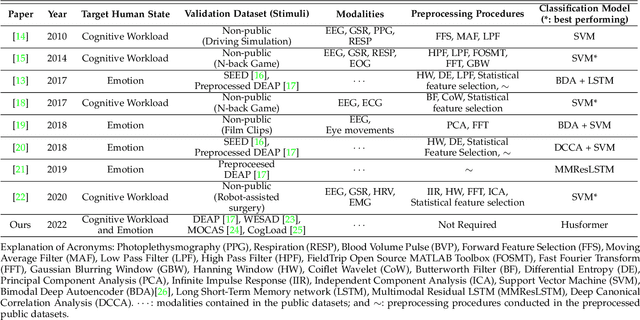
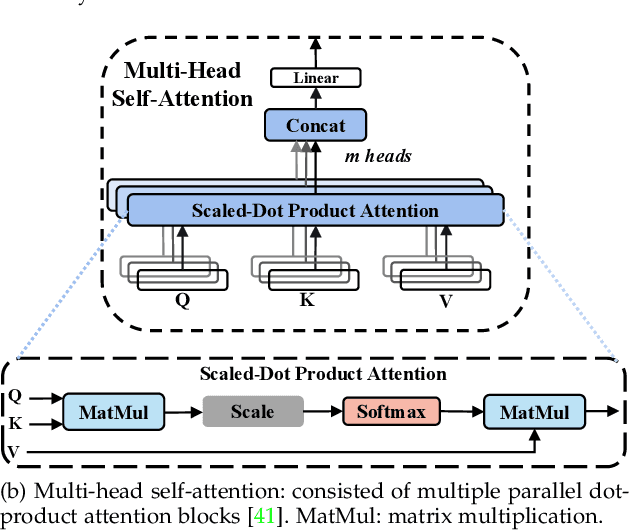
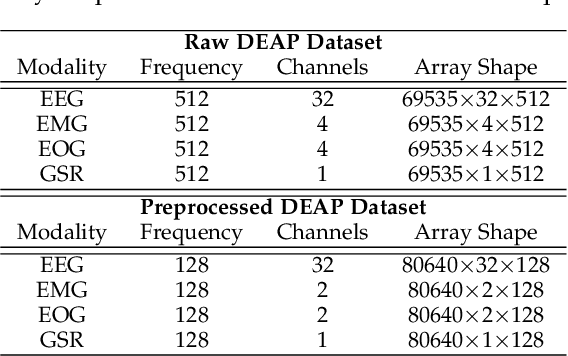
Human state recognition is a critical topic with pervasive and important applications in human-machine systems.Multi-modal fusion, the combination of metrics from multiple data sources, has been shown as a sound method for improving the recognition performance. However, while promising results have been reported by recent multi-modal-based models, they generally fail to leverage the sophisticated fusion strategies that would model sufficient cross-modal interactions when producing the fusion representation; instead, current methods rely on lengthy and inconsistent data preprocessing and feature crafting. To address this limitation, we propose an end-to-end multi-modal transformer framework for multi-modal human state recognition called Husformer.Specifically, we propose to use cross-modal transformers, which inspire one modality to reinforce itself through directly attending to latent relevance revealed in other modalities, to fuse different modalities while ensuring sufficient awareness of the cross-modal interactions introduced. Subsequently, we utilize a self-attention transformer to further prioritize contextual information in the fusion representation. Using two such attention mechanisms enables effective and adaptive adjustments to noise and interruptions in multi-modal signals during the fusion process and in relation to high-level features. Extensive experiments on two human emotion corpora (DEAP and WESAD) and two cognitive workload datasets (MOCAS and CogLoad) demonstrate that in the recognition of human state, our Husformer outperforms both state-of-the-art multi-modal baselines and the use of a single modality by a large margin, especially when dealing with raw multi-modal signals. We also conducted an ablation study to show the benefits of each component in Husformer/
DenserNet: Weakly Supervised Visual Localization Using Multi-scale Feature Aggregation
Dec 31, 2020

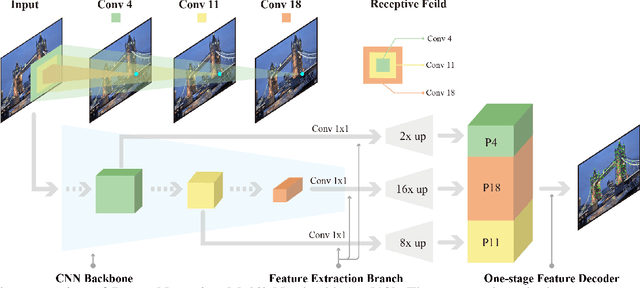
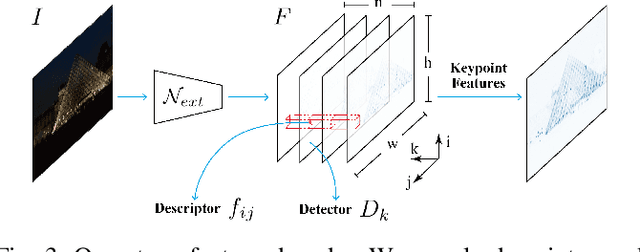
In this work, we introduce a Denser Feature Network (DenserNet) for visual localization. Our work provides three principal contributions. First, we develop a convolutional neural network (CNN) architecture which aggregates feature maps at different semantic levels for image representations. Using denser feature maps, our method can produce more keypoint features and increase image retrieval accuracy. Second, our model is trained end-to-end without pixel-level annotation other than positive and negative GPS-tagged image pairs. We use a weakly supervised triplet ranking loss to learn discriminative features and encourage keypoint feature repeatability for image representation. Finally, our method is computationally efficient as our architecture has shared features and parameters during computation. Our method can perform accurate large-scale localization under challenging conditions while remaining the computational constraint. Extensive experiment results indicate that our method sets a new state-of-the-art on four challenging large-scale localization benchmarks and three image retrieval benchmarks.
Visual Localization for Autonomous Driving: Mapping the Accurate Location in the City Maze
Aug 13, 2020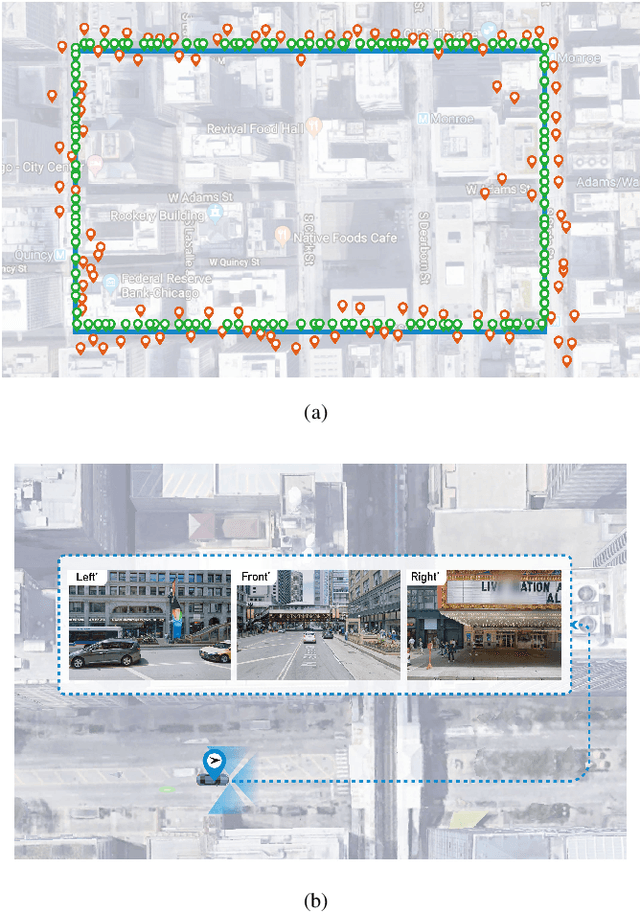
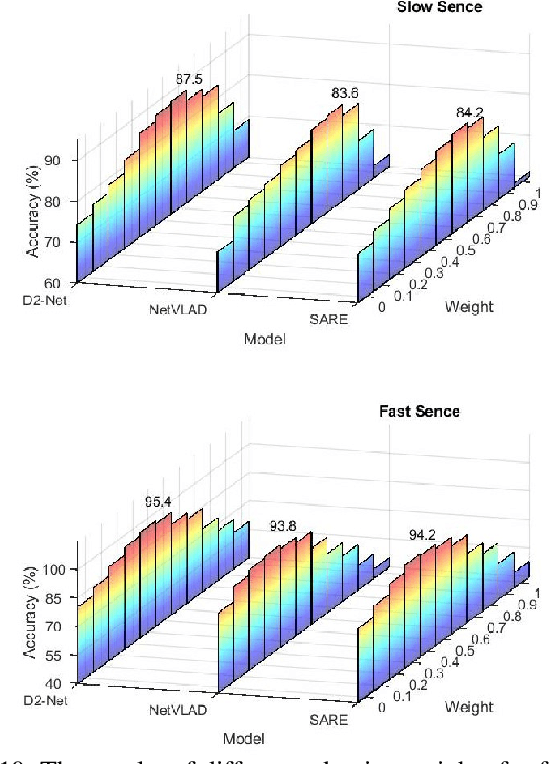
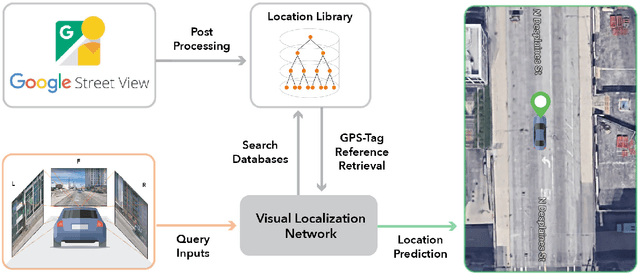
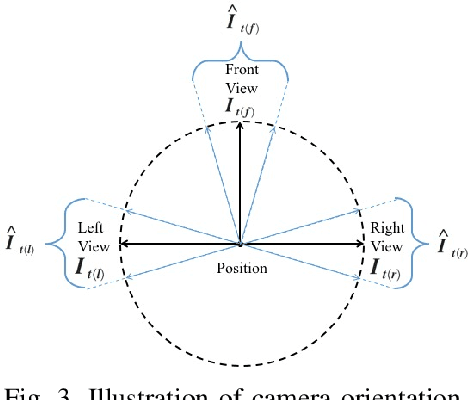
Accurate localization is a foundational capacity, required for autonomous vehicles to accomplish other tasks such as navigation or path planning. It is a common practice for vehicles to use GPS to acquire location information. However, the application of GPS can result in severe challenges when vehicles run within the inner city where different kinds of structures may shadow the GPS signal and lead to inaccurate location results. To address the localization challenges of urban settings, we propose a novel feature voting technique for visual localization. Different from the conventional front-view-based method, our approach employs views from three directions (front, left, and right) and thus significantly improves the robustness of location prediction. In our work, we craft the proposed feature voting method into three state-of-the-art visual localization networks and modify their architectures properly so that they can be applied for vehicular operation. Extensive field test results indicate that our approach can predict location robustly even in challenging inner-city settings. Our research sheds light on using the visual localization approach to help autonomous vehicles to find accurate location information in a city maze, within a desirable time constraint.
PENet: Object Detection using Points Estimation in Aerial Images
Jan 22, 2020
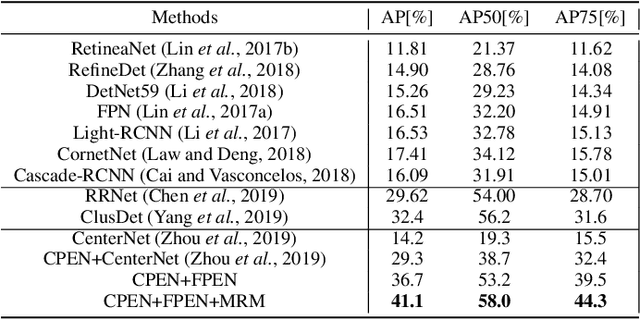

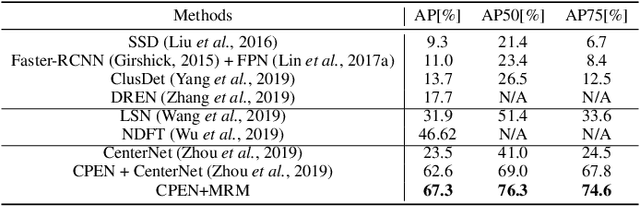
Aerial imagery has been increasingly adopted in mission-critical tasks, such as traffic surveillance, smart cities, and disaster assistance. However, identifying objects from aerial images faces the following challenges: 1) objects of interests are often too small and too dense relative to the images; 2) objects of interests are often in different relative sizes; and 3) the number of objects in each category is imbalanced. A novel network structure, Points Estimated Network (PENet), is proposed in this work to answer these challenges. PENet uses a Mask Resampling Module (MRM) to augment the imbalanced datasets, a coarse anchor-free detector (CPEN) to effectively predict the center points of the small object clusters, and a fine anchor-free detector FPEN to locate the precise positions of the small objects. An adaptive merge algorithm Non-maximum Merge (NMM) is implemented in CPEN to address the issue of detecting dense small objects, and a hierarchical loss is defined in FPEN to further improve the classification accuracy. Our extensive experiments on aerial datasets visDrone and UAVDT showed that PENet achieved higher precision results than existing state-of-the-art approaches. Our best model achieved 8.7% improvement on visDrone and 20.3% on UAVDT.