 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrder Acquisition Under Competitive Pressure: A Rapidly Adaptive Reinforcement Learning Approach for Ride-Hailing Subsidy Strategies
Jul 03, 2025The proliferation of ride-hailing aggregator platforms presents significant growth opportunities for ride-service providers by increasing order volume and gross merchandise value (GMV). On most ride-hailing aggregator platforms, service providers that offer lower fares are ranked higher in listings and, consequently, are more likely to be selected by passengers. This competitive ranking mechanism creates a strong incentive for service providers to adopt coupon strategies that lower prices to secure a greater number of orders, as order volume directly influences their long-term viability and sustainability. Thus, designing an effective coupon strategy that can dynamically adapt to market fluctuations while optimizing order acquisition under budget constraints is a critical research challenge. However, existing studies in this area remain scarce. To bridge this gap, we propose FCA-RL, a novel reinforcement learning-based subsidy strategy framework designed to rapidly adapt to competitors' pricing adjustments. Our approach integrates two key techniques: Fast Competition Adaptation (FCA), which enables swift responses to dynamic price changes, and Reinforced Lagrangian Adjustment (RLA), which ensures adherence to budget constraints while optimizing coupon decisions on new price landscape. Furthermore, we introduce RideGym, the first dedicated simulation environment tailored for ride-hailing aggregators, facilitating comprehensive evaluation and benchmarking of different pricing strategies without compromising real-world operational efficiency. Experimental results demonstrate that our proposed method consistently outperforms baseline approaches across diverse market conditions, highlighting its effectiveness in subsidy optimization for ride-hailing service providers.
Multimodal Remote Sensing Scene Classification Using VLMs and Dual-Cross Attention Networks
Dec 03, 2024
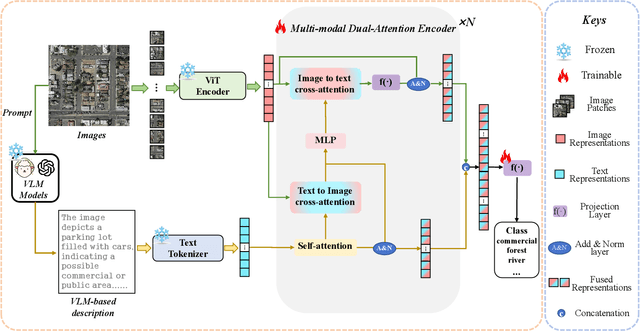
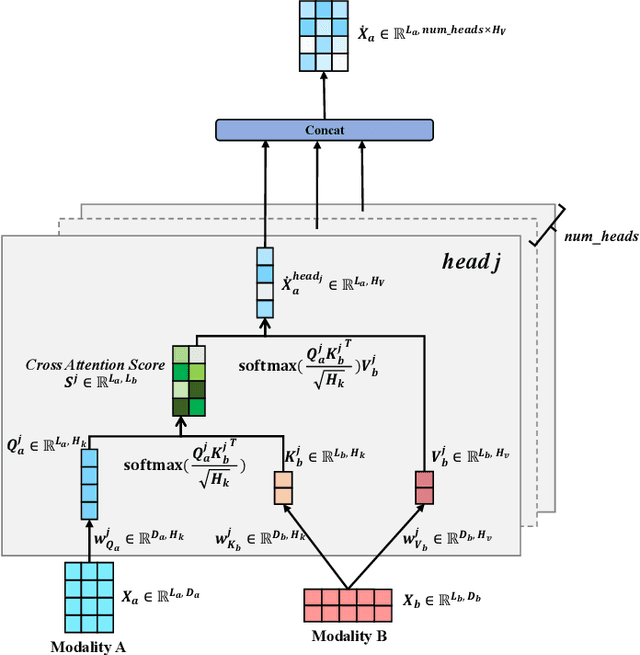
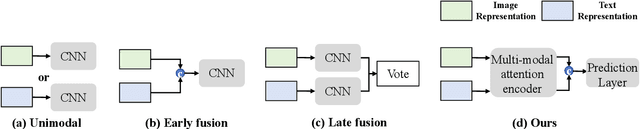
Remote sensing scene classification (RSSC) is a critical task with diverse applications in land use and resource management. While unimodal image-based approaches show promise, they often struggle with limitations such as high intra-class variance and inter-class similarity. Incorporating textual information can enhance classification by providing additional context and semantic understanding, but manual text annotation is labor-intensive and costly. In this work, we propose a novel RSSC framework that integrates text descriptions generated by large vision-language models (VLMs) as an auxiliary modality without incurring expensive manual annotation costs. To fully leverage the latent complementarities between visual and textual data, we propose a dual cross-attention-based network to fuse these modalities into a unified representation. Extensive experiments with both quantitative and qualitative evaluation across five RSSC datasets demonstrate that our framework consistently outperforms baseline models. We also verify the effectiveness of VLM-generated text descriptions compared to human-annotated descriptions. Additionally, we design a zero-shot classification scenario to show that the learned multimodal representation can be effectively utilized for unseen class classification. This research opens new opportunities for leveraging textual information in RSSC tasks and provides a promising multimodal fusion structure, offering insights and inspiration for future studies. Code is available at: https://github.com/CJR7/MultiAtt-RSSC