 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrder Acquisition Under Competitive Pressure: A Rapidly Adaptive Reinforcement Learning Approach for Ride-Hailing Subsidy Strategies
Jul 03, 2025The proliferation of ride-hailing aggregator platforms presents significant growth opportunities for ride-service providers by increasing order volume and gross merchandise value (GMV). On most ride-hailing aggregator platforms, service providers that offer lower fares are ranked higher in listings and, consequently, are more likely to be selected by passengers. This competitive ranking mechanism creates a strong incentive for service providers to adopt coupon strategies that lower prices to secure a greater number of orders, as order volume directly influences their long-term viability and sustainability. Thus, designing an effective coupon strategy that can dynamically adapt to market fluctuations while optimizing order acquisition under budget constraints is a critical research challenge. However, existing studies in this area remain scarce. To bridge this gap, we propose FCA-RL, a novel reinforcement learning-based subsidy strategy framework designed to rapidly adapt to competitors' pricing adjustments. Our approach integrates two key techniques: Fast Competition Adaptation (FCA), which enables swift responses to dynamic price changes, and Reinforced Lagrangian Adjustment (RLA), which ensures adherence to budget constraints while optimizing coupon decisions on new price landscape. Furthermore, we introduce RideGym, the first dedicated simulation environment tailored for ride-hailing aggregators, facilitating comprehensive evaluation and benchmarking of different pricing strategies without compromising real-world operational efficiency. Experimental results demonstrate that our proposed method consistently outperforms baseline approaches across diverse market conditions, highlighting its effectiveness in subsidy optimization for ride-hailing service providers.
An End-to-End Reinforcement Learning Based Approach for Micro-View Order-Dispatching in Ride-Hailing
Aug 20, 2024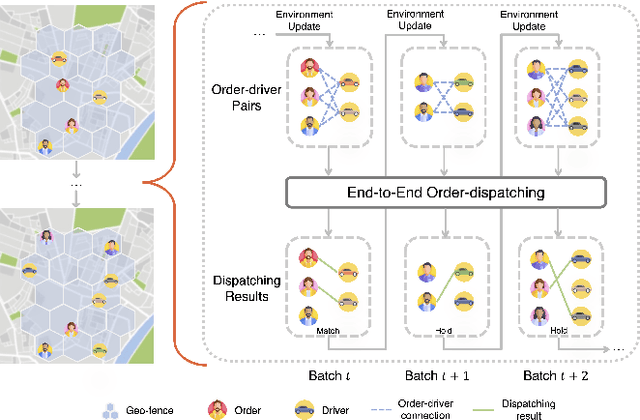

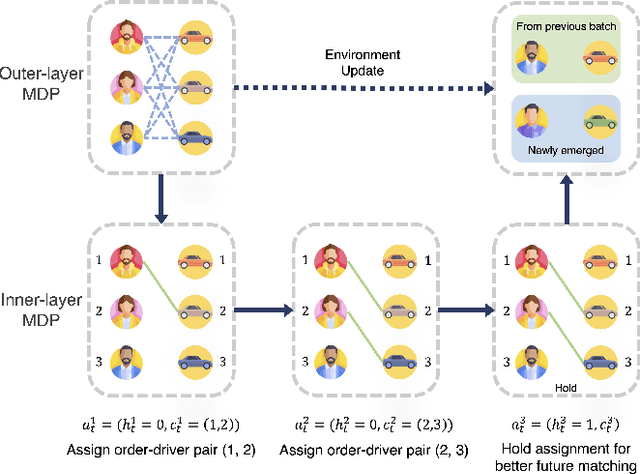

Assigning orders to drivers under localized spatiotemporal context (micro-view order-dispatching) is a major task in Didi, as it influences ride-hailing service experience. Existing industrial solutions mainly follow a two-stage pattern that incorporate heuristic or learning-based algorithms with naive combinatorial methods, tackling the uncertainty of both sides' behaviors, including emerging timings, spatial relationships, and travel duration, etc. In this paper, we propose a one-stage end-to-end reinforcement learning based order-dispatching approach that solves behavior prediction and combinatorial optimization uniformly in a sequential decision-making manner. Specifically, we employ a two-layer Markov Decision Process framework to model this problem, and present \underline{D}eep \underline{D}ouble \underline{S}calable \underline{N}etwork (D2SN), an encoder-decoder structure network to generate order-driver assignments directly and stop assignments accordingly. Besides, by leveraging contextual dynamics, our approach can adapt to the behavioral patterns for better performance. Extensive experiments on Didi's real-world benchmarks justify that the proposed approach significantly outperforms competitive baselines in optimizing matching efficiency and user experience tasks. In addition, we evaluate the deployment outline and discuss the gains and experiences obtained during the deployment tests from the view of large-scale engineering implementation.