 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenseBench: A Benchmark for Remote Sensing Low-Level Visual Perception and Description in Large Vision-Language Models
May 11, 2026Low-level visual perception underpins reliable remote sensing (RS) image analysis, yet current image quality assessment (IQA) methods output uninterpretable scalar scores rather than characterizing physics-driven RS degradations, deviating markedly from the diagnostic needs of RS experts. While Vision-Language Models (VLMs) present a compelling alternative by delivering language-grounded IQA, their visual priors are heavily biased toward ground-level natural images. Consequently, whether VLMs can overcome this domain gap to perceive and articulate RS artifacts remains insufficiently studied. To bridge this gap, we propose \textbf{SenseBench}, the first dedicated diagnostic benchmark for RS low-level visual perception and description. Driven by a physics-based hierarchical taxonomy that unifies both non-reference and reference-based paradigms, SenseBench features over 10K meticulously curated instances across 6 major and 22 fine-grained RS degradation categories. Specifically, two complementary protocols are designed for evaluation: objective low-level visual \textit{perception} and subjective diagnostic \textit{description}. Comprehensive evaluation of 29 state-of-the-art VLMs reveals not only skewed domain priors and multi-distortion collapse, but also \textit{fluency illusion} and a \textit{perception-description inversion} effect. We hope SenseBench provides a robust evaluation testbed and high-quality diagnostic data to advance the development of VLMs in RS low-level perception. Code and datasets are available \href{https://github.com/Zhong-Chenchen/SenseBench}{\textcolor{blue}{here}}.
Co-Sight: Enhancing LLM-Based Agents via Conflict-Aware Meta-Verification and Trustworthy Reasoning with Structured Facts
Oct 24, 2025Long-horizon reasoning in LLM-based agents often fails not from generative weakness but from insufficient verification of intermediate reasoning. Co-Sight addresses this challenge by turning reasoning into a falsifiable and auditable process through two complementary mechanisms: Conflict-Aware Meta-Verification (CAMV) and Trustworthy Reasoning with Structured Facts (TRSF). CAMV reformulates verification as conflict identification and targeted falsification, allocating computation only to disagreement hotspots among expert agents rather than to full reasoning chains. This bounds verification cost to the number of inconsistencies and improves efficiency and reliability. TRSF continuously organizes, validates, and synchronizes evidence across agents through a structured facts module. By maintaining verified, traceable, and auditable knowledge, it ensures that all reasoning is grounded in consistent, source-verified information and supports transparent verification throughout the reasoning process. Together, TRSF and CAMV form a closed verification loop, where TRSF supplies structured facts and CAMV selectively falsifies or reinforces them, yielding transparent and trustworthy reasoning. Empirically, Co-Sight achieves state-of-the-art accuracy on GAIA (84.4%) and Humanity's Last Exam (35.5%), and strong results on Chinese-SimpleQA (93.8%). Ablation studies confirm that the synergy between structured factual grounding and conflict-aware verification drives these improvements. Co-Sight thus offers a scalable paradigm for reliable long-horizon reasoning in LLM-based agents. Code is available at https://github.com/ZTE-AICloud/Co-Sight/tree/cosight2.0_benchmarks.
An End-to-End Reinforcement Learning Based Approach for Micro-View Order-Dispatching in Ride-Hailing
Aug 20, 2024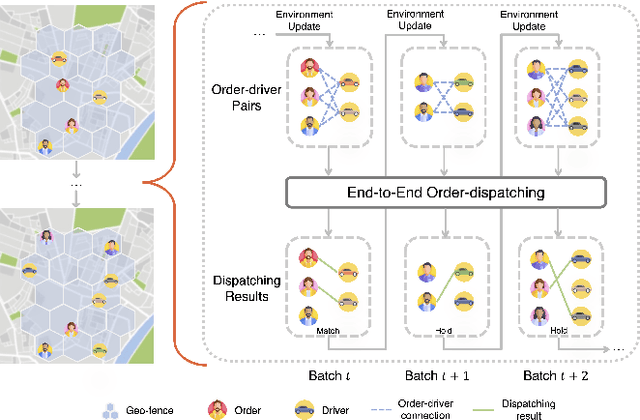

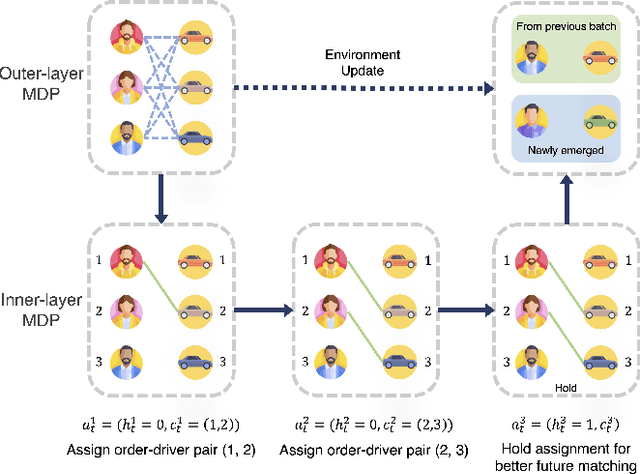

Assigning orders to drivers under localized spatiotemporal context (micro-view order-dispatching) is a major task in Didi, as it influences ride-hailing service experience. Existing industrial solutions mainly follow a two-stage pattern that incorporate heuristic or learning-based algorithms with naive combinatorial methods, tackling the uncertainty of both sides' behaviors, including emerging timings, spatial relationships, and travel duration, etc. In this paper, we propose a one-stage end-to-end reinforcement learning based order-dispatching approach that solves behavior prediction and combinatorial optimization uniformly in a sequential decision-making manner. Specifically, we employ a two-layer Markov Decision Process framework to model this problem, and present \underline{D}eep \underline{D}ouble \underline{S}calable \underline{N}etwork (D2SN), an encoder-decoder structure network to generate order-driver assignments directly and stop assignments accordingly. Besides, by leveraging contextual dynamics, our approach can adapt to the behavioral patterns for better performance. Extensive experiments on Didi's real-world benchmarks justify that the proposed approach significantly outperforms competitive baselines in optimizing matching efficiency and user experience tasks. In addition, we evaluate the deployment outline and discuss the gains and experiences obtained during the deployment tests from the view of large-scale engineering implementation.
Large Language Models Powered Context-aware Motion Prediction
Mar 17, 2024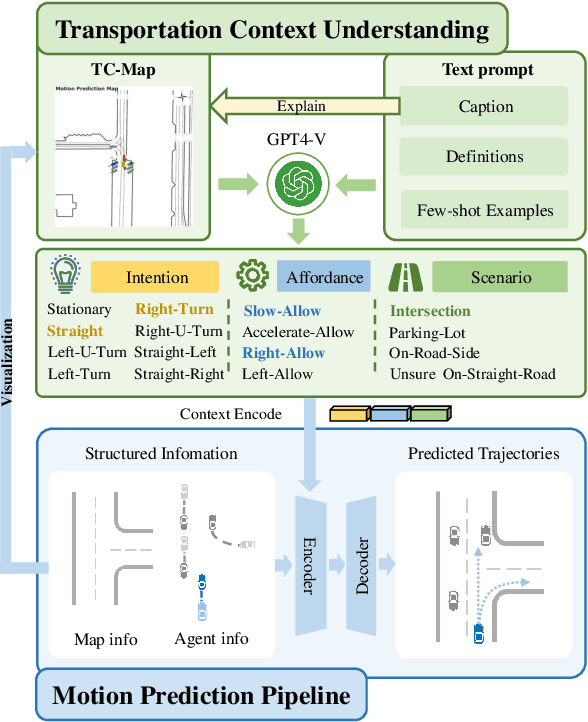
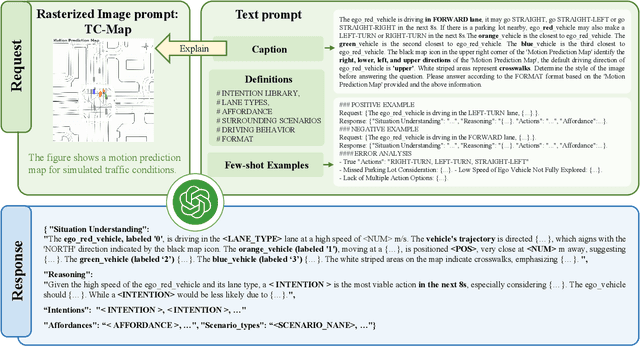
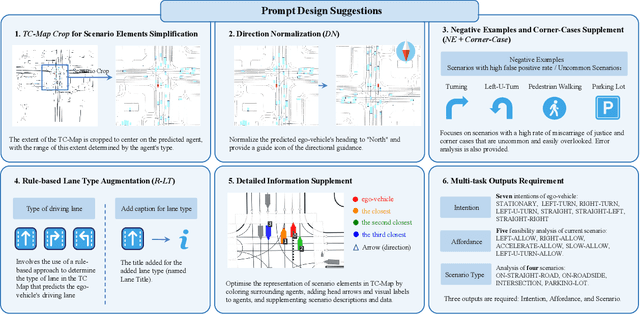
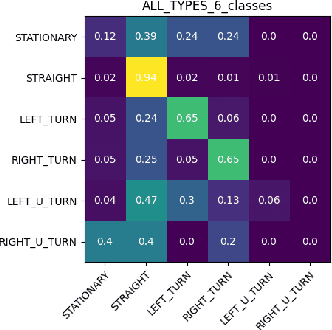
Motion prediction is among the most fundamental tasks in autonomous driving. Traditional methods of motion forecasting primarily encode vector information of maps and historical trajectory data of traffic participants, lacking a comprehensive understanding of overall traffic semantics, which in turn affects the performance of prediction tasks. In this paper, we utilized Large Language Models (LLMs) to enhance the global traffic context understanding for motion prediction tasks. We first conducted systematic prompt engineering, visualizing complex traffic environments and historical trajectory information of traffic participants into image prompts -- Transportation Context Map (TC-Map), accompanied by corresponding text prompts. Through this approach, we obtained rich traffic context information from the LLM. By integrating this information into the motion prediction model, we demonstrate that such context can enhance the accuracy of motion predictions. Furthermore, considering the cost associated with LLMs, we propose a cost-effective deployment strategy: enhancing the accuracy of motion prediction tasks at scale with 0.7\% LLM-augmented datasets. Our research offers valuable insights into enhancing the understanding of traffic scenes of LLMs and the motion prediction performance of autonomous driving.
Anomaly Detection via Learning-Based Sequential Controlled Sensing
Nov 30, 2023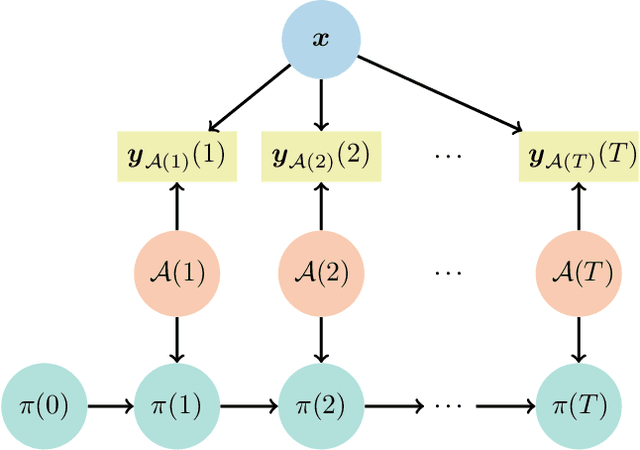

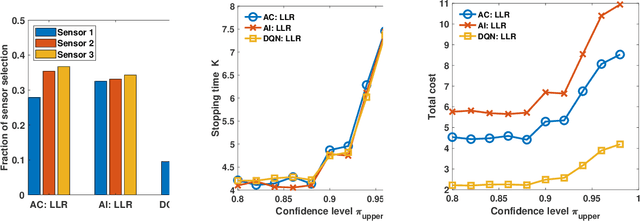
In this paper, we address the problem of detecting anomalies among a given set of binary processes via learning-based controlled sensing. Each process is parameterized by a binary random variable indicating whether the process is anomalous. To identify the anomalies, the decision-making agent is allowed to observe a subset of the processes at each time instant. Also, probing each process has an associated cost. Our objective is to design a sequential selection policy that dynamically determines which processes to observe at each time with the goal to minimize the delay in making the decision and the total sensing cost. We cast this problem as a sequential hypothesis testing problem within the framework of Markov decision processes. This formulation utilizes both a Bayesian log-likelihood ratio-based reward and an entropy-based reward. The problem is then solved using two approaches: 1) a deep reinforcement learning-based approach where we design both deep Q-learning and policy gradient actor-critic algorithms; and 2) a deep active inference-based approach. Using numerical experiments, we demonstrate the efficacy of our algorithms and show that our algorithms adapt to any unknown statistical dependence pattern of the processes.
Scalable and Decentralized Algorithms for Anomaly Detection via Learning-Based Controlled Sensing
Dec 08, 2021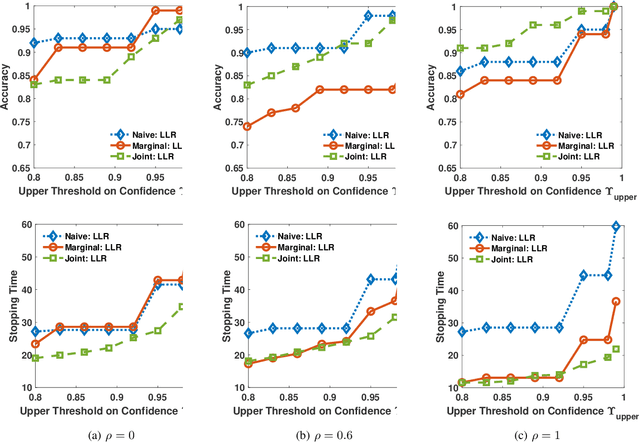
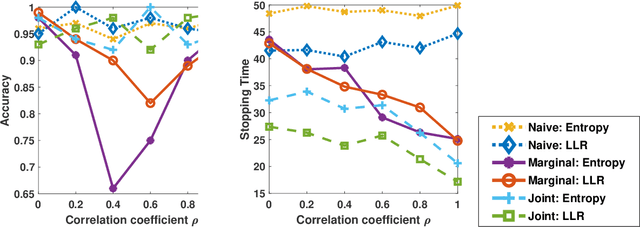
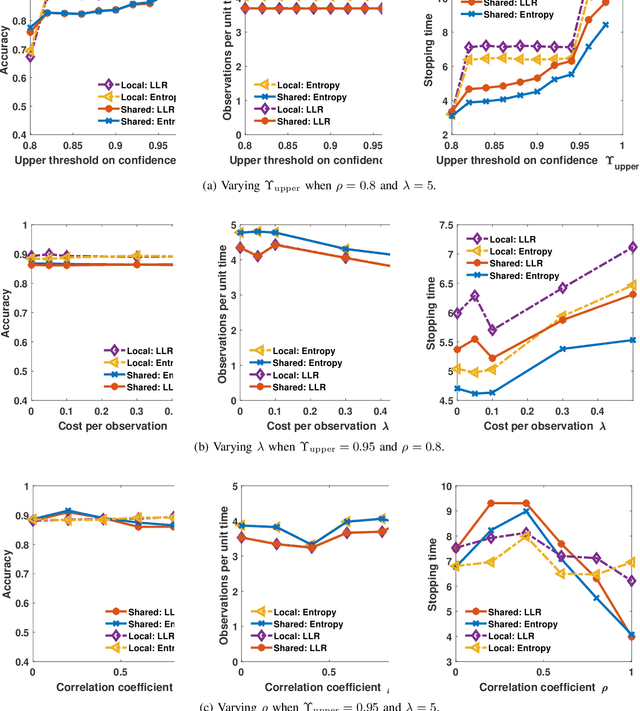
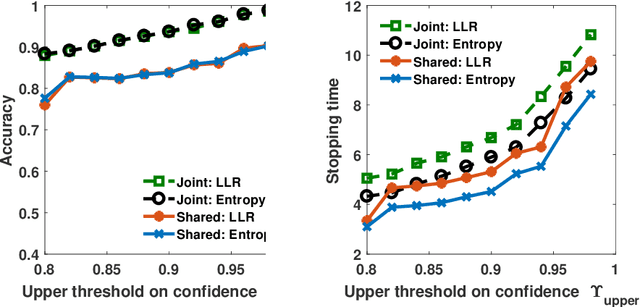
We address the problem of sequentially selecting and observing processes from a given set to find the anomalies among them. The decision-maker observes a subset of the processes at any given time instant and obtains a noisy binary indicator of whether or not the corresponding process is anomalous. In this setting, we develop an anomaly detection algorithm that chooses the processes to be observed at a given time instant, decides when to stop taking observations, and declares the decision on anomalous processes. The objective of the detection algorithm is to identify the anomalies with an accuracy exceeding the desired value while minimizing the delay in decision making. We devise a centralized algorithm where the processes are jointly selected by a common agent as well as a decentralized algorithm where the decision of whether to select a process is made independently for each process. Our algorithms rely on a Markov decision process defined using the marginal probability of each process being normal or anomalous, conditioned on the observations. We implement the detection algorithms using the deep actor-critic reinforcement learning framework. Unlike prior work on this topic that has exponential complexity in the number of processes, our algorithms have computational and memory requirements that are both polynomial in the number of processes. We demonstrate the efficacy of these algorithms using numerical experiments by comparing them with state-of-the-art methods.
Anomaly Detection via Controlled Sensing and Deep Active Inference
May 12, 2021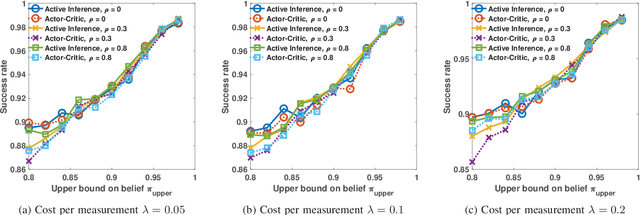
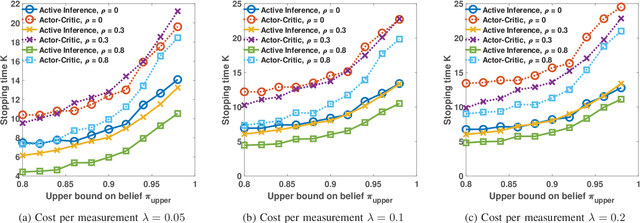
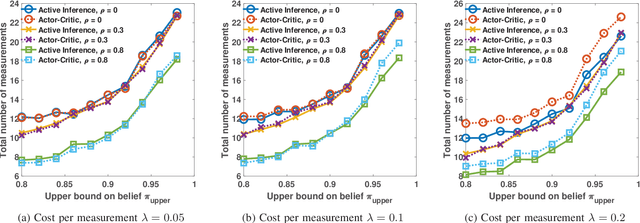
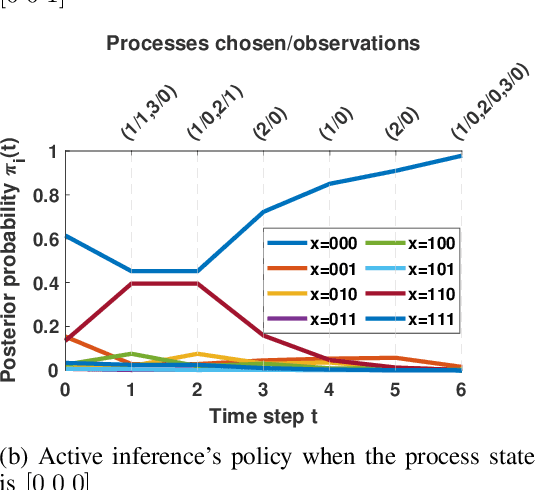
In this paper, we address the anomaly detection problem where the objective is to find the anomalous processes among a given set of processes. To this end, the decision-making agent probes a subset of processes at every time instant and obtains a potentially erroneous estimate of the binary variable which indicates whether or not the corresponding process is anomalous. The agent continues to probe the processes until it obtains a sufficient number of measurements to reliably identify the anomalous processes. In this context, we develop a sequential selection algorithm that decides which processes to be probed at every instant to detect the anomalies with an accuracy exceeding a desired value while minimizing the delay in making the decision and the total number of measurements taken. Our algorithm is based on active inference which is a general framework to make sequential decisions in order to maximize the notion of free energy. We define the free energy using the objectives of the selection policy and implement the active inference framework using a deep neural network approximation. Using numerical experiments, we compare our algorithm with the state-of-the-art method based on deep actor-critic reinforcement learning and demonstrate the superior performance of our algorithm.
* 6 pages,9 figures
Anomaly Detection and Sampling Cost Control via Hierarchical GANs
Sep 28, 2020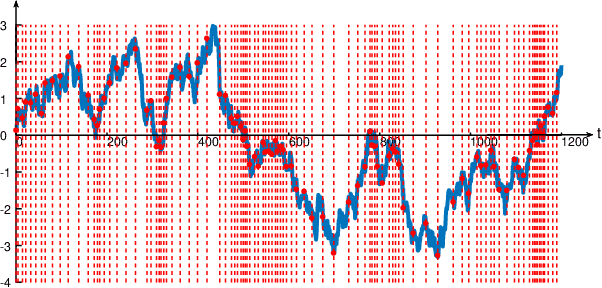
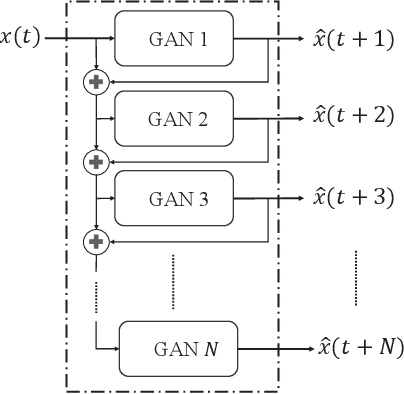
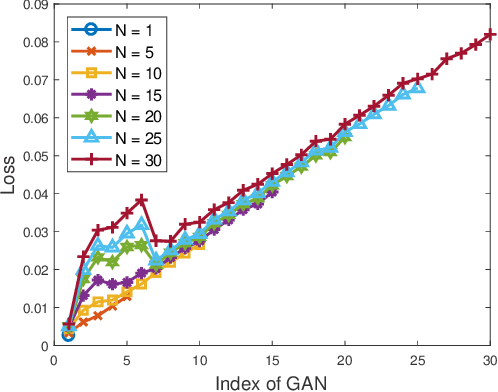
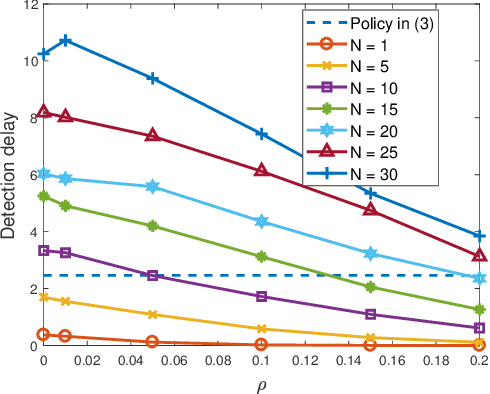
Anomaly detection incurs certain sampling and sensing costs and therefore it is of great importance to strike a balance between the detection accuracy and these costs. In this work, we study anomaly detection by considering the detection of threshold crossings in a stochastic time series without the knowledge of its statistics. To reduce the sampling cost in this detection process, we propose the use of hierarchical generative adversarial networks (GANs) to perform nonuniform sampling. In order to improve the detection accuracy and reduce the delay in detection, we introduce a buffer zone in the operation of the proposed GAN-based detector. In the experiments, we analyze the performance of the proposed hierarchical GAN detector considering the metrics of detection delay, miss rates, average cost of error, and sampling ratio. We identify the tradeoffs in the performance as the buffer zone sizes and the number of GAN levels in the hierarchy vary. We also compare the performance with that of a sampling policy that approximately minimizes the sum of average costs of sampling and error given the parameters of the stochastic process. We demonstrate that the proposed GAN-based detector can have significant performance improvements in terms of detection delay and average cost of error with a larger buffer zone but at the cost of increased sampling rates.
Adversarial jamming attacks and defense strategies via adaptive deep reinforcement learning
Jul 12, 2020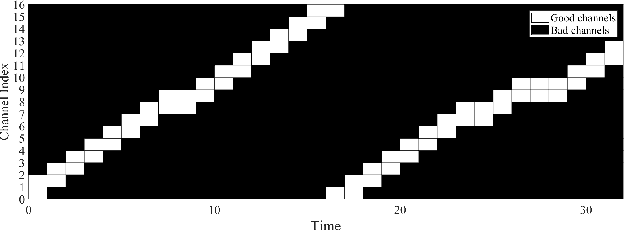
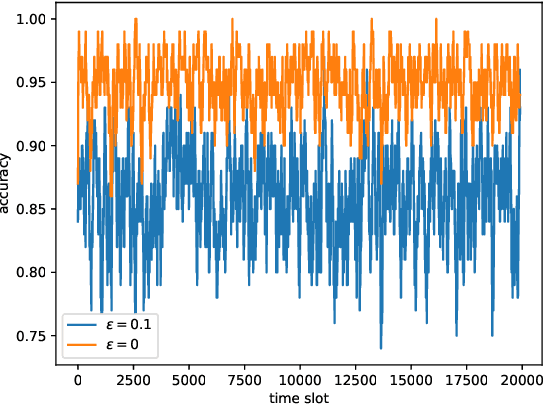
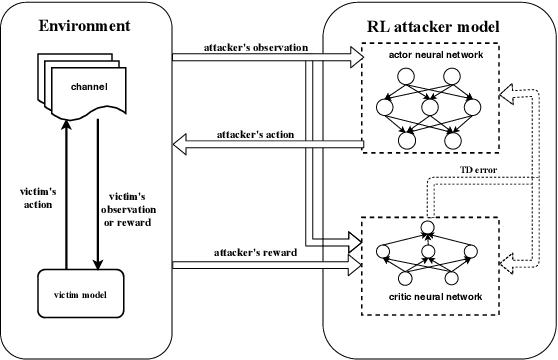
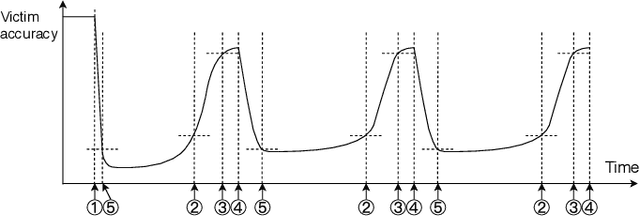
As the applications of deep reinforcement learning (DRL) in wireless communications grow, sensitivity of DRL based wireless communication strategies against adversarial attacks has started to draw increasing attention. In order to address such sensitivity and alleviate the resulting security concerns, we in this paper consider a victim user that performs DRL-based dynamic channel access, and an attacker that executes DRLbased jamming attacks to disrupt the victim. Hence, both the victim and attacker are DRL agents and can interact with each other, retrain their models, and adapt to opponents' policies. In this setting, we initially develop an adversarial jamming attack policy that aims at minimizing the accuracy of victim's decision making on dynamic channel access. Subsequently, we devise defense strategies against such an attacker, and propose three defense strategies, namely diversified defense with proportional-integral-derivative (PID) control, diversified defense with an imitation attacker, and defense via orthogonal policies. We design these strategies to maximize the attacked victim's accuracy and evaluate their performances.
Deep Actor-Critic Reinforcement Learning for Anomaly Detection
Aug 28, 2019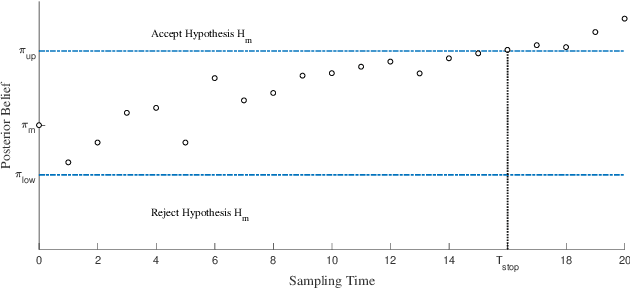
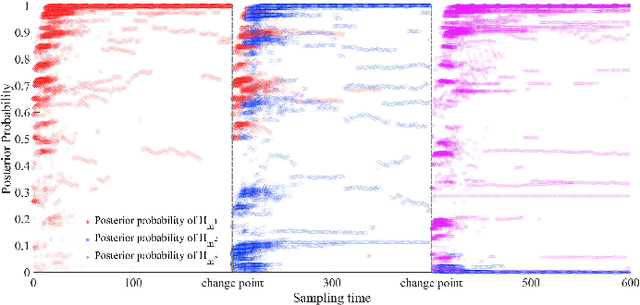
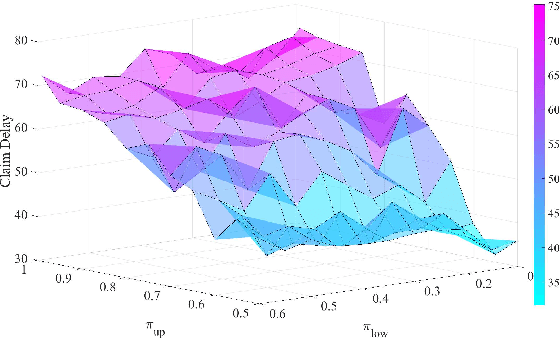
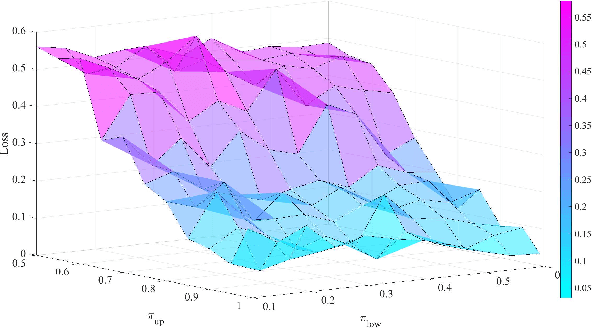
Anomaly detection is widely applied in a variety of domains, involving for instance, smart home systems, network traffic monitoring, IoT applications and sensor networks. In this paper, we study deep reinforcement learning based active sequential testing for anomaly detection. We assume that there is an unknown number of abnormal processes at a time and the agent can only check with one sensor in each sampling step. To maximize the confidence level of the decision and minimize the stopping time concurrently, we propose a deep actor-critic reinforcement learning framework that can dynamically select the sensor based on the posterior probabilities. We provide simulation results for both the training phase and testing phase, and compare the proposed framework with the Chernoff test in terms of claim delay and loss.