 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycle-Consistent Tuning for Layered Image Decomposition
Feb 24, 2026Disentangling visual layers in real-world images is a persistent challenge in vision and graphics, as such layers often involve non-linear and globally coupled interactions, including shading, reflection, and perspective distortion. In this work, we present an in-context image decomposition framework that leverages large diffusion foundation models for layered separation. We focus on the challenging case of logo-object decomposition, where the goal is to disentangle a logo from the surface on which it appears while faithfully preserving both layers. Our method fine-tunes a pretrained diffusion model via lightweight LoRA adaptation and introduces a cycle-consistent tuning strategy that jointly trains decomposition and composition models, enforcing reconstruction consistency between decomposed and recomposed images. This bidirectional supervision substantially enhances robustness in cases where the layers exhibit complex interactions. Furthermore, we introduce a progressive self-improving process, which iteratively augments the training set with high-quality model-generated examples to refine performance. Extensive experiments demonstrate that our approach achieves accurate and coherent decompositions and also generalizes effectively across other decomposition types, suggesting its potential as a unified framework for layered image decomposition.
General OOD Detection via Model-aware and Subspace-aware Variable Priority
Dec 15, 2025Out-of-distribution (OOD) detection is essential for determining when a supervised model encounters inputs that differ meaningfully from its training distribution. While widely studied in classification, OOD detection for regression and survival analysis remains limited due to the absence of discrete labels and the challenge of quantifying predictive uncertainty. We introduce a framework for OOD detection that is simultaneously model aware and subspace aware, and that embeds variable prioritization directly into the detection step. The method uses the fitted predictor to construct localized neighborhoods around each test case that emphasize the features driving the model's learned relationship and downweight directions that are less relevant to prediction. It produces OOD scores without relying on global distance metrics or estimating the full feature density. The framework is applicable across outcome types, and in our implementation we use random forests, where the rule structure yields transparent neighborhoods and effective scoring. Experiments on synthetic and real data benchmarks designed to isolate functional shifts show consistent improvements over existing methods. We further demonstrate the approach in an esophageal cancer survival study, where distribution shifts related to lymphadenectomy identify patterns relevant to surgical guidelines.
iCD: A Implicit Clustering Distillation Mathod for Structural Information Mining
Sep 16, 2025Logit Knowledge Distillation has gained substantial research interest in recent years due to its simplicity and lack of requirement for intermediate feature alignment; however, it suffers from limited interpretability in its decision-making process. To address this, we propose implicit Clustering Distillation (iCD): a simple and effective method that mines and transfers interpretable structural knowledge from logits, without requiring ground-truth labels or feature-space alignment. iCD leverages Gram matrices over decoupled local logit representations to enable student models to learn latent semantic structural patterns. Extensive experiments on benchmark datasets demonstrate the effectiveness of iCD across diverse teacher-student architectures, with particularly strong performance in fine-grained classification tasks -- achieving a peak improvement of +5.08% over the baseline. The code is available at: https://github.com/maomaochongaa/iCD.
Model-independent variable selection via the rule-based variable priority
Sep 16, 2024



While achieving high prediction accuracy is a fundamental goal in machine learning, an equally important task is finding a small number of features with high explanatory power. One popular selection technique is permutation importance, which assesses a variable's impact by measuring the change in prediction error after permuting the variable. However, this can be problematic due to the need to create artificial data, a problem shared by other methods as well. Another problem is that variable selection methods can be limited by being model-specific. We introduce a new model-independent approach, Variable Priority (VarPro), which works by utilizing rules without the need to generate artificial data or evaluate prediction error. The method is relatively easy to use, requiring only the calculation of sample averages of simple statistics, and can be applied to many data settings, including regression, classification, and survival. We investigate the asymptotic properties of VarPro and show, among other things, that VarPro has a consistent filtering property for noise variables. Empirical studies using synthetic and real-world data show the method achieves a balanced performance and compares favorably to many state-of-the-art procedures currently used for variable selection.
An End-to-End Reinforcement Learning Based Approach for Micro-View Order-Dispatching in Ride-Hailing
Aug 20, 2024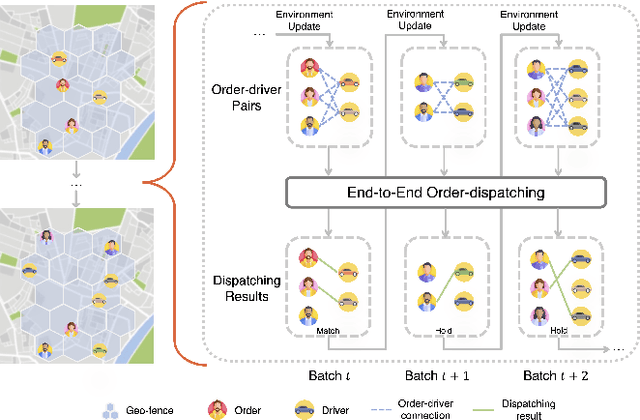

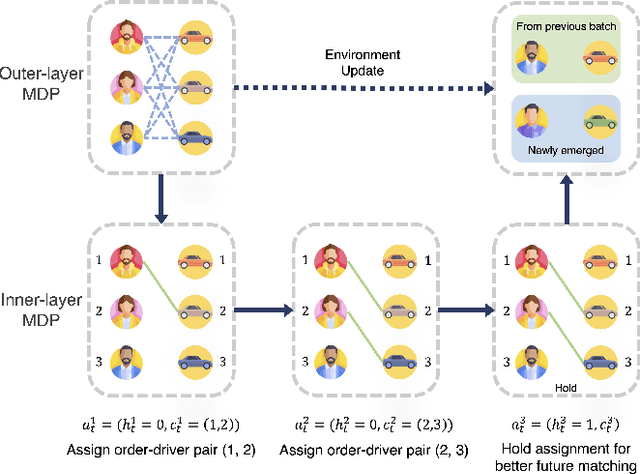

Assigning orders to drivers under localized spatiotemporal context (micro-view order-dispatching) is a major task in Didi, as it influences ride-hailing service experience. Existing industrial solutions mainly follow a two-stage pattern that incorporate heuristic or learning-based algorithms with naive combinatorial methods, tackling the uncertainty of both sides' behaviors, including emerging timings, spatial relationships, and travel duration, etc. In this paper, we propose a one-stage end-to-end reinforcement learning based order-dispatching approach that solves behavior prediction and combinatorial optimization uniformly in a sequential decision-making manner. Specifically, we employ a two-layer Markov Decision Process framework to model this problem, and present \underline{D}eep \underline{D}ouble \underline{S}calable \underline{N}etwork (D2SN), an encoder-decoder structure network to generate order-driver assignments directly and stop assignments accordingly. Besides, by leveraging contextual dynamics, our approach can adapt to the behavioral patterns for better performance. Extensive experiments on Didi's real-world benchmarks justify that the proposed approach significantly outperforms competitive baselines in optimizing matching efficiency and user experience tasks. In addition, we evaluate the deployment outline and discuss the gains and experiences obtained during the deployment tests from the view of large-scale engineering implementation.
Layered Image Vectorization via Semantic Simplification
Jun 08, 2024



This work presents a novel progressive image vectorization technique aimed at generating layered vectors that represent the original image from coarse to fine detail levels. Our approach introduces semantic simplification, which combines Score Distillation Sampling and semantic segmentation to iteratively simplify the input image. Subsequently, our method optimizes the vector layers for each of the progressively simplified images. Our method provides robust optimization, which avoids local minima and enables adjustable detail levels in the final output. The layered, compact vector representation enhances usability for further editing and modification. Comparative analysis with conventional vectorization methods demonstrates our technique's superiority in producing vectors with high visual fidelity, and more importantly, maintaining vector compactness and manageability. The project homepage is https://szuviz.github.io/layered_vectorization/.
AGMDT: Virtual Staining of Renal Histology Images with Adjacency-Guided Multi-Domain Transfer
Sep 17, 2023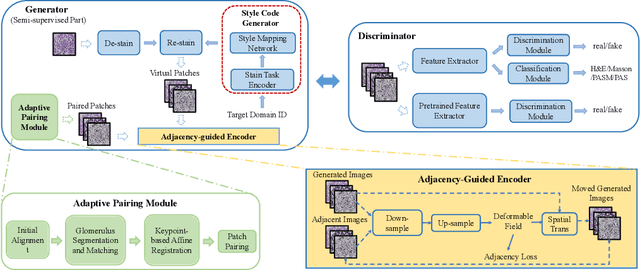
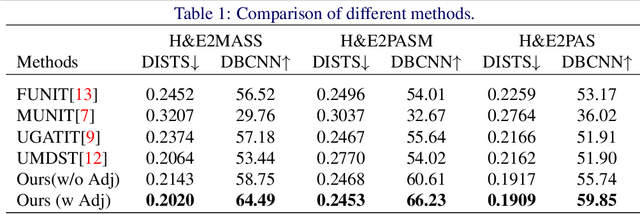


Renal pathology, as the gold standard of kidney disease diagnosis, requires doctors to analyze a series of tissue slices stained by H&E staining and special staining like Masson, PASM, and PAS, respectively. These special staining methods are costly, time-consuming, and hard to standardize for wide use especially in primary hospitals. Advances of supervised learning methods have enabled the virtually conversion of H&E images into special staining images, but achieving pixel-to-pixel alignment for training remains challenging. In contrast, unsupervised learning methods regarding different stains as different style transfer domains can utilize unpaired data, but they ignore the spatial inter-domain correlations and thus decrease the trustworthiness of structural details for diagnosis. In this paper, we propose a novel virtual staining framework AGMDT to translate images into other domains by avoiding pixel-level alignment and meanwhile utilizing the correlations among adjacent tissue slices. We first build a high-quality multi-domain renal histological dataset where each specimen case comprises a series of slices stained in various ways. Based on it, the proposed framework AGMDT discovers patch-level aligned pairs across the serial slices of multi-domains through glomerulus detection and bipartite graph matching, and utilizes such correlations to supervise the end-to-end model for multi-domain staining transformation. Experimental results show that the proposed AGMDT achieves a good balance between the precise pixel-level alignment and unpaired domain transfer by exploiting correlations across multi-domain serial pathological slices, and outperforms the state-of-the-art methods in both quantitative measure and morphological details.
Follow the Prophet: Accurate Online Conversion Rate Prediction in the Face of Delayed Feedback
Aug 13, 2021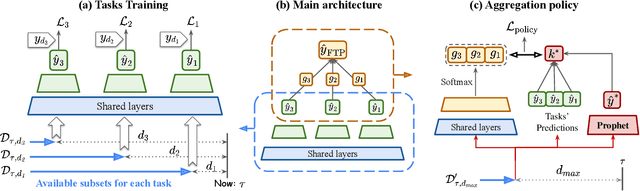
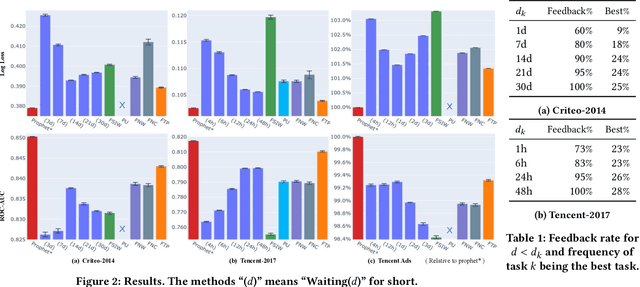
The delayed feedback problem is one of the imperative challenges in online advertising, which is caused by the highly diversified feedback delay of a conversion varying from a few minutes to several days. It is hard to design an appropriate online learning system under these non-identical delay for different types of ads and users. In this paper, we propose to tackle the delayed feedback problem in online advertising by "Following the Prophet" (FTP for short). The key insight is that, if the feedback came instantly for all the logged samples, we could get a model without delayed feedback, namely the "prophet". Although the prophet cannot be obtained during online learning, we show that we could predict the prophet's predictions by an aggregation policy on top of a set of multi-task predictions, where each task captures the feedback patterns of different periods. We propose the objective and optimization approach for the policy, and use the logged data to imitate the prophet. Extensive experiments on three real-world advertising datasets show that our method outperforms the previous state-of-the-art baselines.
Towards reliable and fair probabilistic predictions: field-aware calibration with neural networks
May 28, 2019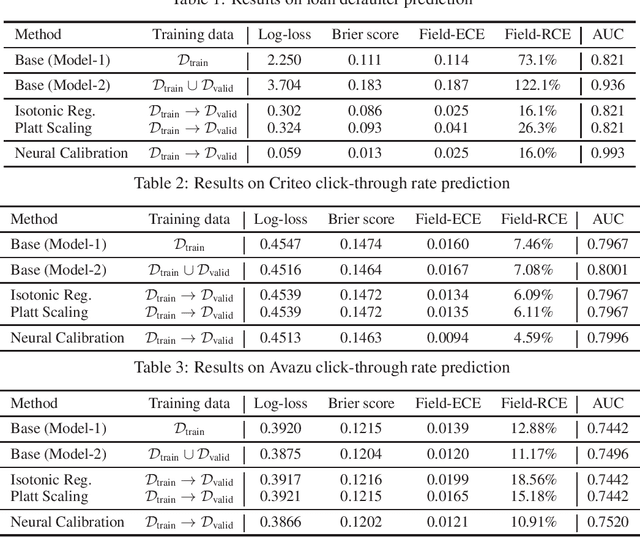
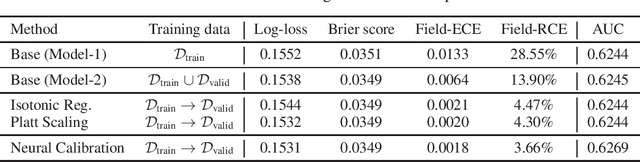
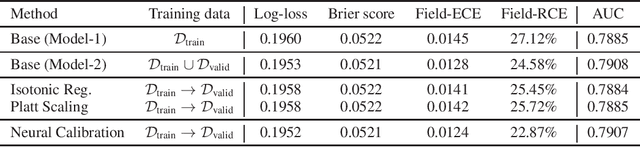
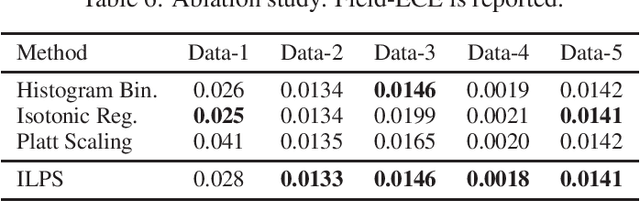
In machine learning, it is observed that probabilistic predictions sometimes disagree with averaged actual outcomes on certain subsets of data. This is also known as miscalibration that is responsible for unreliability and unfairness of practical machine learning systems. In this paper, we put forward an evaluation metric for calibration, coined field-level calibration error, that measures bias in predictions over the input fields that the decision maker concerns. We show that existing calibration methods perform poorly under our new metric. Specifically, after learning a calibration mapping over the validation dataset, existing methods have limited improvements in our error metric and completely fail to improve other non-calibration metrics such as the AUC score. We propose Neural Calibration, a new calibration method, which learns to calibrate by making full use of all input information over the validation set. We test our method on five large-scale real-world datasets. The results show that Neural Calibration significantly improves against uncalibrated predictions in all well-known metrics such as the negative log-likelihood, the Brier score, the AUC score, as well as our proposed field-level calibration error.
A Machine Learning Alternative to P-values
Feb 20, 2017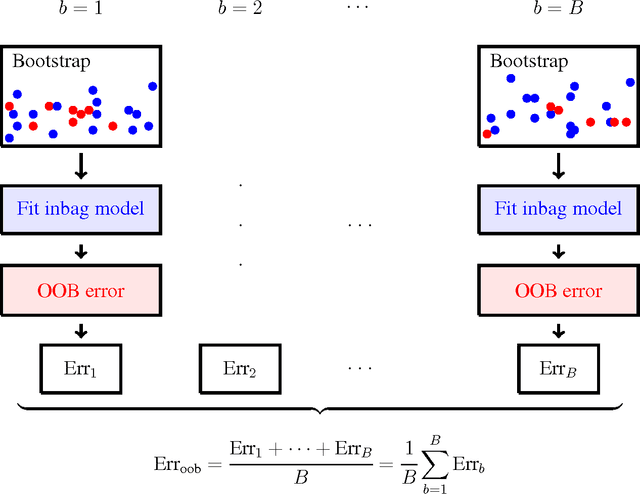
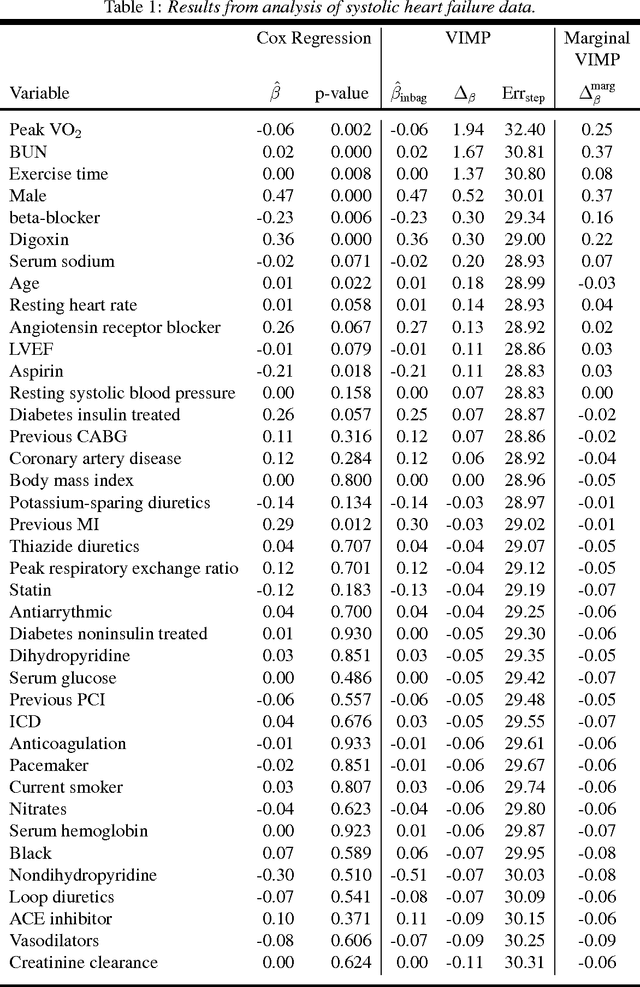

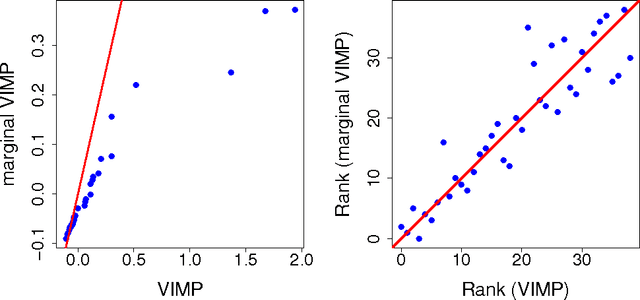
This paper presents an alternative approach to p-values in regression settings. This approach, whose origins can be traced to machine learning, is based on the leave-one-out bootstrap for prediction error. In machine learning this is called the out-of-bag (OOB) error. To obtain the OOB error for a model, one draws a bootstrap sample and fits the model to the in-sample data. The out-of-sample prediction error for the model is obtained by calculating the prediction error for the model using the out-of-sample data. Repeating and averaging yields the OOB error, which represents a robust cross-validated estimate of the accuracy of the underlying model. By a simple modification to the bootstrap data involving "noising up" a variable, the OOB method yields a variable importance (VIMP) index, which directly measures how much a specific variable contributes to the prediction precision of a model. VIMP provides a scientifically interpretable measure of the effect size of a variable, we call the "predictive effect size", that holds whether the researcher's model is correct or not, unlike the p-value whose calculation is based on the assumed correctness of the model. We also discuss a marginal VIMP index, also easily calculated, which measures the marginal effect of a variable, or what we call "the discovery effect". The OOB procedure can be applied to both parametric and nonparametric regression models and requires only that the researcher can repeatedly fit their model to bootstrap and modified bootstrap data. We illustrate this approach on a survival data set involving patients with systolic heart failure and to a simulated survival data set where the model is incorrectly specified to illustrate its robustness to model misspecification.