 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexRepNet++: Learning Dexterous Robotic Manipulation with Geometric and Spatial Hand-Object Representations
Feb 25, 2026Robotic dexterous manipulation is a challenging problem due to high degrees of freedom (DoFs) and complex contacts of multi-fingered robotic hands. Many existing deep reinforcement learning (DRL) based methods aim at improving sample efficiency in high-dimensional output action spaces. However, existing works often overlook the role of representations in achieving generalization of a manipulation policy in the complex input space during the hand-object interaction. In this paper, we propose DexRep, a novel hand-object interaction representation to capture object surface features and spatial relations between hands and objects for dexterous manipulation skill learning. Based on DexRep, policies are learned for three dexterous manipulation tasks, i.e. grasping, in-hand reorientation, bimanual handover, and extensive experiments are conducted to verify the effectiveness. In simulation, for grasping, the policy learned with 40 objects achieves a success rate of 87.9% on more than 5000 unseen objects of diverse categories, significantly surpassing existing work trained with thousands of objects; for the in-hand reorientation and handover tasks, the policies also boost the success rates and other metrics of existing hand-object representations by 20% to 40%. The grasp policies with DexRep are deployed to the real world under multi-camera and single-camera setups and demonstrate a small sim-to-real gap.
* Accepted by IEEE Transactions on Robotics (T-RO), 2026
RNBF: Real-Time RGB-D Based Neural Barrier Functions for Safe Robotic Navigation
May 04, 2025
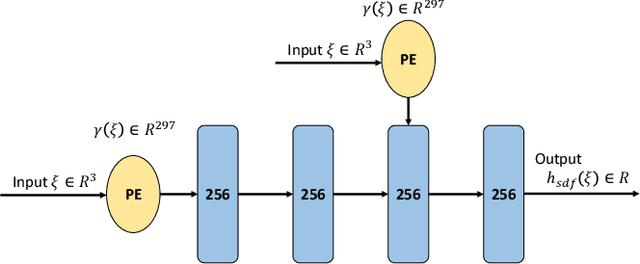
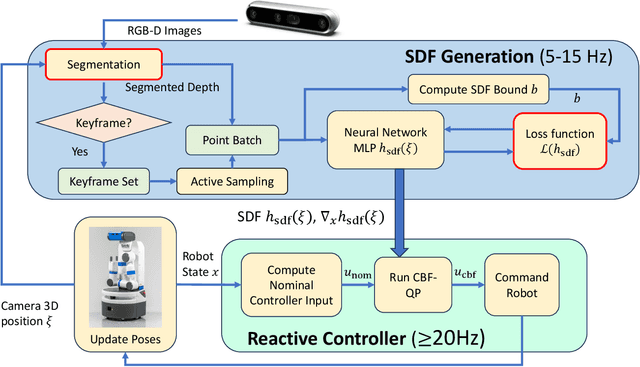
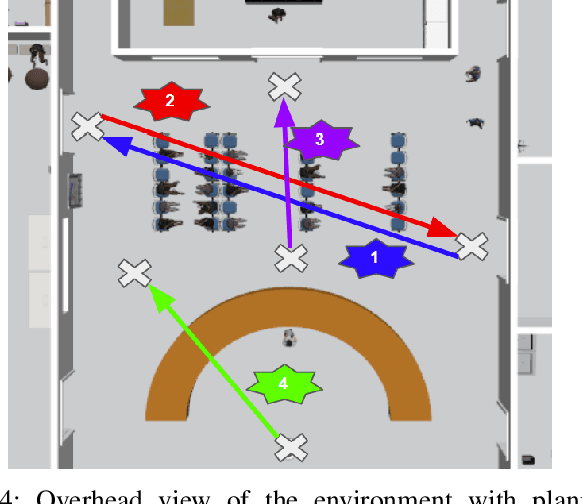
Autonomous safe navigation in unstructured and novel environments poses significant challenges, especially when environment information can only be provided through low-cost vision sensors. Although safe reactive approaches have been proposed to ensure robot safety in complex environments, many base their theory off the assumption that the robot has prior knowledge on obstacle locations and geometries. In this paper, we present a real-time, vision-based framework that constructs continuous, first-order differentiable Signed Distance Fields (SDFs) of unknown environments without any pre-training. Our proposed method ensures full compatibility with established SDF-based reactive controllers. To achieve robust performance under practical sensing conditions, our approach explicitly accounts for noise in affordable RGB-D cameras, refining the neural SDF representation online for smoother geometry and stable gradient estimates. We validate the proposed method in simulation and real-world experiments using a Fetch robot.
PLANET: A Collection of Benchmarks for Evaluating LLMs' Planning Capabilities
Apr 21, 2025Planning is central to agents and agentic AI. The ability to plan, e.g., creating travel itineraries within a budget, holds immense potential in both scientific and commercial contexts. Moreover, optimal plans tend to require fewer resources compared to ad-hoc methods. To date, a comprehensive understanding of existing planning benchmarks appears to be lacking. Without it, comparing planning algorithms' performance across domains or selecting suitable algorithms for new scenarios remains challenging. In this paper, we examine a range of planning benchmarks to identify commonly used testbeds for algorithm development and highlight potential gaps. These benchmarks are categorized into embodied environments, web navigation, scheduling, games and puzzles, and everyday task automation. Our study recommends the most appropriate benchmarks for various algorithms and offers insights to guide future benchmark development.
Systematic Analysis of LLM Contributions to Planning: Solver, Verifier, Heuristic
Dec 12, 2024
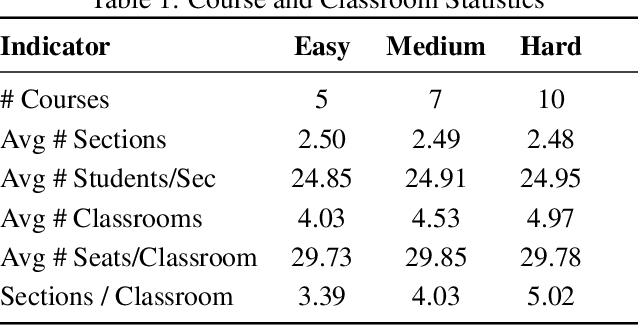
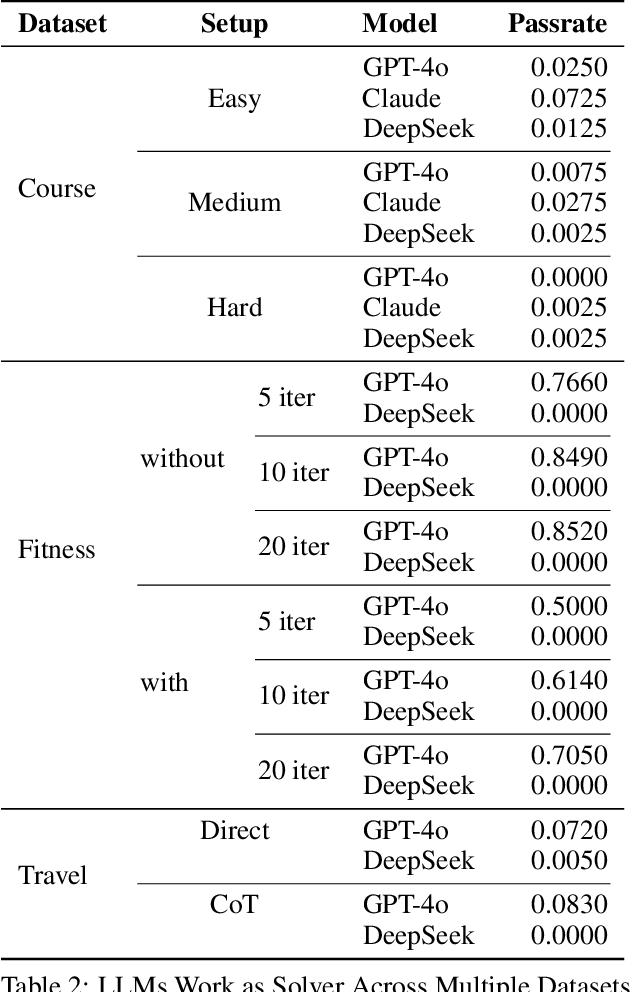
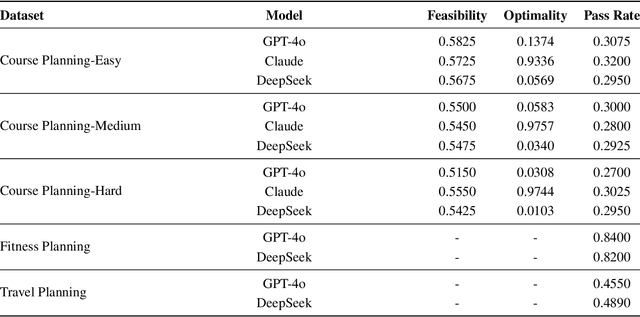
In this work, we provide a systematic analysis of how large language models (LLMs) contribute to solving planning problems. In particular, we examine how LLMs perform when they are used as problem solver, solution verifier, and heuristic guidance to improve intermediate solutions. Our analysis reveals that although it is difficult for LLMs to generate correct plans out-of-the-box, LLMs are much better at providing feedback signals to intermediate/incomplete solutions in the form of comparative heuristic functions. This evaluation framework provides insights into how future work may design better LLM-based tree-search algorithms to solve diverse planning and reasoning problems. We also propose a novel benchmark to evaluate LLM's ability to learn user preferences on the fly, which has wide applications in practical settings.
Characterized Diffusion Networks for Enhanced Autonomous Driving Trajectory Prediction
Nov 25, 2024In this paper, we present a novel trajectory prediction model for autonomous driving, combining a Characterized Diffusion Module and a Spatial-Temporal Interaction Network to address the challenges posed by dynamic and heterogeneous traffic environments. Our model enhances the accuracy and reliability of trajectory predictions by incorporating uncertainty estimation and complex agent interactions. Through extensive experimentation on public datasets such as NGSIM, HighD, and MoCAD, our model significantly outperforms existing state-of-the-art methods. We demonstrate its ability to capture the underlying spatial-temporal dynamics of traffic scenarios and improve prediction precision, especially in complex environments. The proposed model showcases strong potential for application in real-world autonomous driving systems.
LASP: Surveying the State-of-the-Art in Large Language Model-Assisted AI Planning
Sep 03, 2024
Effective planning is essential for the success of any task, from organizing a vacation to routing autonomous vehicles and developing corporate strategies. It involves setting goals, formulating plans, and allocating resources to achieve them. LLMs are particularly well-suited for automated planning due to their strong capabilities in commonsense reasoning. They can deduce a sequence of actions needed to achieve a goal from a given state and identify an effective course of action. However, it is frequently observed that plans generated through direct prompting often fail upon execution. Our survey aims to highlight the existing challenges in planning with language models, focusing on key areas such as embodied environments, optimal scheduling, competitive and cooperative games, task decomposition, reasoning, and planning. Through this study, we explore how LLMs transform AI planning and provide unique insights into the future of LM-assisted planning.
Trajectory-wise Iterative Reinforcement Learning Framework for Auto-bidding
Feb 23, 2024



In online advertising, advertisers participate in ad auctions to acquire ad opportunities, often by utilizing auto-bidding tools provided by demand-side platforms (DSPs). The current auto-bidding algorithms typically employ reinforcement learning (RL). However, due to safety concerns, most RL-based auto-bidding policies are trained in simulation, leading to a performance degradation when deployed in online environments. To narrow this gap, we can deploy multiple auto-bidding agents in parallel to collect a large interaction dataset. Offline RL algorithms can then be utilized to train a new policy. The trained policy can subsequently be deployed for further data collection, resulting in an iterative training framework, which we refer to as iterative offline RL. In this work, we identify the performance bottleneck of this iterative offline RL framework, which originates from the ineffective exploration and exploitation caused by the inherent conservatism of offline RL algorithms. To overcome this bottleneck, we propose Trajectory-wise Exploration and Exploitation (TEE), which introduces a novel data collecting and data utilization method for iterative offline RL from a trajectory perspective. Furthermore, to ensure the safety of online exploration while preserving the dataset quality for TEE, we propose Safe Exploration by Adaptive Action Selection (SEAS). Both offline experiments and real-world experiments on Alibaba display advertising platform demonstrate the effectiveness of our proposed method.
RRescue: Ranking LLM Responses to Enhance Reasoning Over Context
Nov 15, 2023Effectively using a given context is paramount for large language models. A context window can include task specifications, retrieved documents, previous conversations, and even model self-reflections, functioning similarly to episodic memory. While efforts are being made to expand the context window, studies indicate that LLMs do not use their context optimally for response generation. In this paper, we present a novel approach to optimize LLMs using ranking metrics, which teaches LLMs to rank a collection of contextually-grounded candidate responses. Rather than a traditional full ordering, we advocate for a partial ordering. This is because achieving consensus on the perfect order for system responses can be challenging. Our partial ordering is more robust, less sensitive to noise, and can be acquired through human labelers, heuristic functions, or model distillation. We test our system's improved contextual understanding using the latest benchmarks, including a new multi-document question answering dataset. We conduct ablation studies to understand crucial factors, such as how to gather candidate responses, determine their most suitable order, and balance supervised fine-tuning with ranking metrics. Our approach, named RRescue, suggests a promising avenue for enhancing LLMs' contextual understanding via response ranking.
Pedestrian Recognition with Radar Data-Enhanced Deep Learning Approach Based on Micro-Doppler Signatures
Jun 14, 2023



As a hot topic in recent years, the ability of pedestrians identification based on radar micro-Doppler signatures is limited by the lack of adequate training data. In this paper, we propose a data-enhanced multi-characteristic learning (DEMCL) model with data enhancement (DE) module and multi-characteristic learning (MCL) module to learn more complementary pedestrian micro-Doppler (m-D) signatures. In DE module, a range-Doppler generative adversarial network (RDGAN) is proposed to enhance free walking datasets, and MCL module with multi-scale convolution neural network (MCNN) and radial basis function neural network (RBFNN) is trained to learn m-D signatures extracted from enhanced datasets. Experimental results show that our model is 3.33% to 10.24% more accurate than other studies and has a short run time of 0.9324 seconds on a 25-minute walking dataset.
Moccasin: Efficient Tensor Rematerialization for Neural Networks
Apr 27, 2023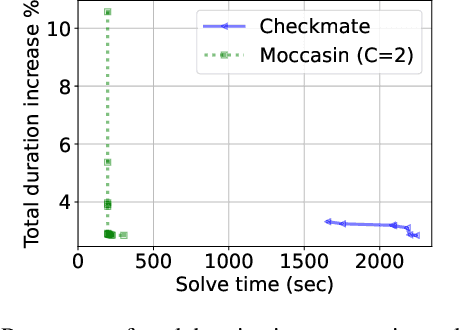

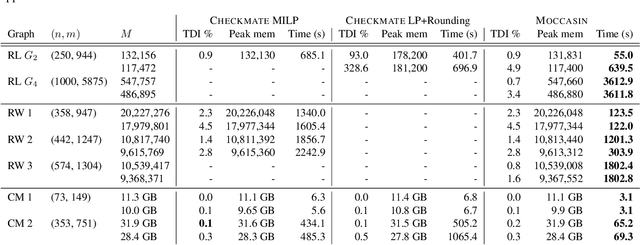
The deployment and training of neural networks on edge computing devices pose many challenges. The low memory nature of edge devices is often one of the biggest limiting factors encountered in the deployment of large neural network models. Tensor rematerialization or recompute is a way to address high memory requirements for neural network training and inference. In this paper we consider the problem of execution time minimization of compute graphs subject to a memory budget. In particular, we develop a new constraint programming formulation called \textsc{Moccasin} with only $O(n)$ integer variables, where $n$ is the number of nodes in the compute graph. This is a significant improvement over the works in the recent literature that propose formulations with $O(n^2)$ Boolean variables. We present numerical studies that show that our approach is up to an order of magnitude faster than recent work especially for large-scale graphs.