 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAS-Mamba: Phase-Amplitude-Spatial State Space Model for MRI Reconstruction
Jan 20, 2026Joint feature modeling in both the spatial and frequency domains has become a mainstream approach in MRI reconstruction. However, existing methods generally treat the frequency domain as a whole, neglecting the differences in the information carried by its internal components. According to Fourier transform theory, phase and amplitude represent different types of information in the image. Our spectrum swapping experiments show that magnitude mainly reflects pixel-level intensity, while phase predominantly governs image structure. To prevent interference between phase and magnitude feature learning caused by unified frequency-domain modeling, we propose the Phase-Amplitude-Spatial State Space Model (PAS-Mamba) for MRI Reconstruction, a framework that decouples phase and magnitude modeling in the frequency domain and combines it with image-domain features for better reconstruction. In the image domain, LocalMamba preserves spatial locality to sharpen fine anatomical details. In frequency domain, we disentangle amplitude and phase into two specialized branches to avoid representational coupling. To respect the concentric geometry of frequency information, we propose Circular Frequency Domain Scanning (CFDS) to serialize features from low to high frequencies. Finally, a Dual-Domain Complementary Fusion Module (DDCFM) adaptively fuses amplitude phase representations and enables bidirectional exchange between frequency and image domains, delivering superior reconstruction. Extensive experiments on the IXI and fastMRI knee datasets show that PAS-Mamba consistently outperforms state of the art reconstruction methods.
SAVEn-Vid: Synergistic Audio-Visual Integration for Enhanced Understanding in Long Video Context
Nov 25, 2024Endeavors have been made to explore Large Language Models for video analysis (Video-LLMs), particularly in understanding and interpreting long videos. However, existing Video-LLMs still face challenges in effectively integrating the rich and diverse audio-visual information inherent in long videos, which is crucial for comprehensive understanding. This raises the question: how can we leverage embedded audio-visual information to enhance long video understanding? Therefore, (i) we introduce SAVEn-Vid, the first-ever long audio-visual video dataset comprising over 58k audio-visual instructions. (ii) From the model perspective, we propose a time-aware Audio-Visual Large Language Model (AV-LLM), SAVEnVideo, fine-tuned on SAVEn-Vid. (iii) Besides, we present AVBench, a benchmark containing 2,500 QAs designed to evaluate models on enhanced audio-visual comprehension tasks within long video, challenging their ability to handle intricate audio-visual interactions. Experiments on AVBench reveal the limitations of current AV-LLMs. Experiments also demonstrate that SAVEnVideo outperforms the best Video-LLM by 3.61% on the zero-shot long video task (Video-MME) and surpasses the leading audio-visual LLM by 1.29% on the zero-shot audio-visual task (Music-AVQA). Consequently, at the 7B parameter scale, SAVEnVideo can achieve state-of-the-art performance. Our dataset and code will be released at https://ljungang.github.io/SAVEn-Vid/ upon acceptance.
Pedestrian Recognition with Radar Data-Enhanced Deep Learning Approach Based on Micro-Doppler Signatures
Jun 14, 2023As a hot topic in recent years, the ability of pedestrians identification based on radar micro-Doppler signatures is limited by the lack of adequate training data. In this paper, we propose a data-enhanced multi-characteristic learning (DEMCL) model with data enhancement (DE) module and multi-characteristic learning (MCL) module to learn more complementary pedestrian micro-Doppler (m-D) signatures. In DE module, a range-Doppler generative adversarial network (RDGAN) is proposed to enhance free walking datasets, and MCL module with multi-scale convolution neural network (MCNN) and radial basis function neural network (RBFNN) is trained to learn m-D signatures extracted from enhanced datasets. Experimental results show that our model is 3.33% to 10.24% more accurate than other studies and has a short run time of 0.9324 seconds on a 25-minute walking dataset.
A Multi-Characteristic Learning Method with Micro-Doppler Signatures for Pedestrian Identification
Mar 23, 2022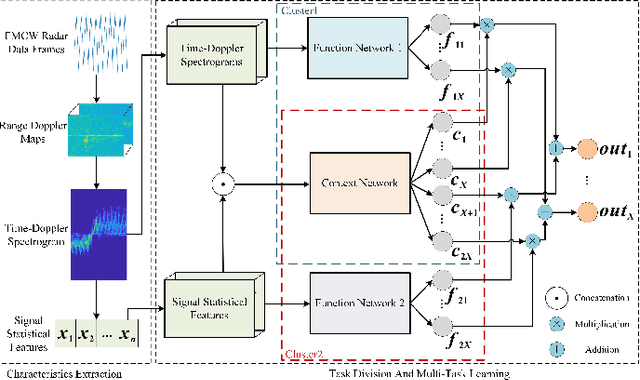
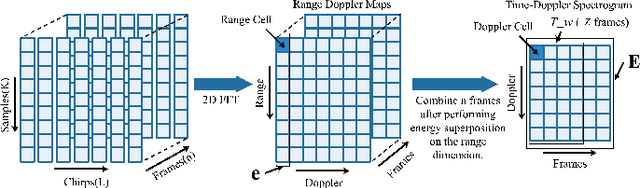
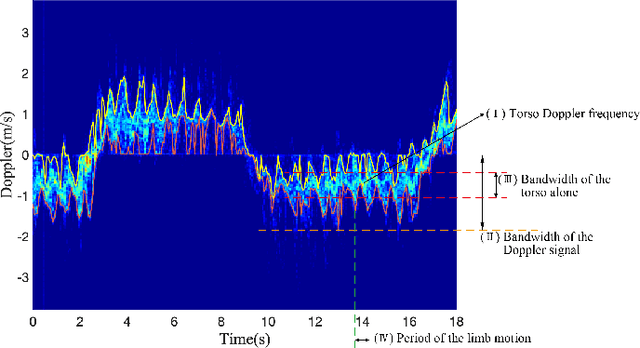
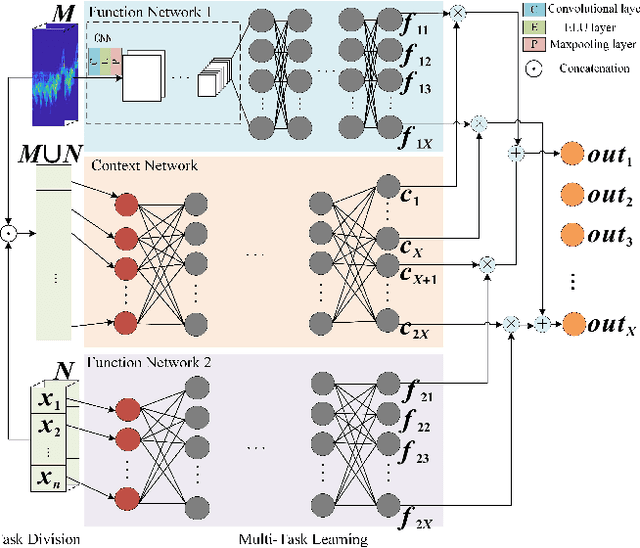
The identification of pedestrians using radar micro-Doppler signatures has become a hot topic in recent years. In this paper, we propose a multi-characteristic learning (MCL) model with clusters to jointly learn discrepant pedestrian micro-Doppler signatures and fuse the knowledge learned from each cluster into final decisions. Time-Doppler spectrogram (TDS) and signal statistical features extracted from FMCW radar, as two categories of micro-Doppler signatures, are used in MCL to learn the micro-motion information inside pedestrians' free walking patterns. The experimental results show that our model achieves a higher accuracy rate and is more stable for pedestrian identification than other studies, which make our model more practical.