 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-Rex-Omni: Integrating Negative Visual Prompt in Generic Object Detection
Nov 12, 2025Object detection methods have evolved from closed-set to open-set paradigms over the years. Current open-set object detectors, however, remain constrained by their exclusive reliance on positive indicators based on given prompts like text descriptions or visual exemplars. This positive-only paradigm experiences consistent vulnerability to visually similar but semantically different distractors. We propose T-Rex-Omni, a novel framework that addresses this limitation by incorporating negative visual prompts to negate hard negative distractors. Specifically, we first introduce a unified visual prompt encoder that jointly processes positive and negative visual prompts. Next, a training-free Negating Negative Computing (NNC) module is proposed to dynamically suppress negative responses during the probability computing stage. To further boost performance through fine-tuning, our Negating Negative Hinge (NNH) loss enforces discriminative margins between positive and negative embeddings. T-Rex-Omni supports flexible deployment in both positive-only and joint positive-negative inference modes, accommodating either user-specified or automatically generated negative examples. Extensive experiments demonstrate remarkable zero-shot detection performance, significantly narrowing the performance gap between visual-prompted and text-prompted methods while showing particular strength in long-tailed scenarios (51.2 AP_r on LVIS-minival). This work establishes negative prompts as a crucial new dimension for advancing open-set visual recognition systems.
Multimodal Spatial Reasoning in the Large Model Era: A Survey and Benchmarks
Oct 29, 2025Humans possess spatial reasoning abilities that enable them to understand spaces through multimodal observations, such as vision and sound. Large multimodal reasoning models extend these abilities by learning to perceive and reason, showing promising performance across diverse spatial tasks. However, systematic reviews and publicly available benchmarks for these models remain limited. In this survey, we provide a comprehensive review of multimodal spatial reasoning tasks with large models, categorizing recent progress in multimodal large language models (MLLMs) and introducing open benchmarks for evaluation. We begin by outlining general spatial reasoning, focusing on post-training techniques, explainability, and architecture. Beyond classical 2D tasks, we examine spatial relationship reasoning, scene and layout understanding, as well as visual question answering and grounding in 3D space. We also review advances in embodied AI, including vision-language navigation and action models. Additionally, we consider emerging modalities such as audio and egocentric video, which contribute to novel spatial understanding through new sensors. We believe this survey establishes a solid foundation and offers insights into the growing field of multimodal spatial reasoning. Updated information about this survey, codes and implementation of the open benchmarks can be found at https://github.com/zhengxuJosh/Awesome-Spatial-Reasoning.
AI for Service: Proactive Assistance with AI Glasses
Oct 16, 2025In an era where AI is evolving from a passive tool into an active and adaptive companion, we introduce AI for Service (AI4Service), a new paradigm that enables proactive and real-time assistance in daily life. Existing AI services remain largely reactive, responding only to explicit user commands. We argue that a truly intelligent and helpful assistant should be capable of anticipating user needs and taking actions proactively when appropriate. To realize this vision, we propose Alpha-Service, a unified framework that addresses two fundamental challenges: Know When to intervene by detecting service opportunities from egocentric video streams, and Know How to provide both generalized and personalized services. Inspired by the von Neumann computer architecture and based on AI glasses, Alpha-Service consists of five key components: an Input Unit for perception, a Central Processing Unit for task scheduling, an Arithmetic Logic Unit for tool utilization, a Memory Unit for long-term personalization, and an Output Unit for natural human interaction. As an initial exploration, we implement Alpha-Service through a multi-agent system deployed on AI glasses. Case studies, including a real-time Blackjack advisor, a museum tour guide, and a shopping fit assistant, demonstrate its ability to seamlessly perceive the environment, infer user intent, and provide timely and useful assistance without explicit prompts.
PhysToolBench: Benchmarking Physical Tool Understanding for MLLMs
Oct 10, 2025The ability to use, understand, and create tools is a hallmark of human intelligence, enabling sophisticated interaction with the physical world. For any general-purpose intelligent agent to achieve true versatility, it must also master these fundamental skills. While modern Multimodal Large Language Models (MLLMs) leverage their extensive common knowledge for high-level planning in embodied AI and in downstream Vision-Language-Action (VLA) models, the extent of their true understanding of physical tools remains unquantified. To bridge this gap, we present PhysToolBench, the first benchmark dedicated to evaluating the comprehension of physical tools by MLLMs. Our benchmark is structured as a Visual Question Answering (VQA) dataset comprising over 1,000 image-text pairs. It assesses capabilities across three distinct difficulty levels: (1) Tool Recognition: Requiring the recognition of a tool's primary function. (2) Tool Understanding: Testing the ability to grasp the underlying principles of a tool's operation. (3) Tool Creation: Challenging the model to fashion a new tool from surrounding objects when conventional options are unavailable. Our comprehensive evaluation of 32 MLLMs-spanning proprietary, open-source, specialized embodied, and backbones in VLAs-reveals a significant deficiency in tool understanding. Furthermore, we provide an in-depth analysis and propose preliminary solutions. Code and dataset are publicly available.
Are We Using the Right Benchmark: An Evaluation Framework for Visual Token Compression Methods
Oct 08, 2025Recent endeavors to accelerate inference in Multimodal Large Language Models (MLLMs) have primarily focused on visual token compression. The effectiveness of these methods is typically assessed by measuring the accuracy drop on established benchmarks, comparing model performance before and after compression. However, these benchmarks are originally designed to assess the perception and reasoning capabilities of MLLMs, rather than to evaluate compression techniques. As a result, directly applying them to visual token compression introduces a task mismatch. Strikingly, our investigation reveals that simple image downsampling consistently outperforms many advanced compression methods across multiple widely used benchmarks. Through extensive experiments, we make the following observations: (i) Current benchmarks are noisy for the visual token compression task. (ii) Down-sampling is able to serve as a data filter to evaluate the difficulty of samples in the visual token compression task. Motivated by these findings, we introduce VTC-Bench, an evaluation framework that incorporates a data filtering mechanism to denoise existing benchmarks, thereby enabling fairer and more accurate assessment of visual token compression methods. All data and code are available at https://github.com/Chenfei-Liao/VTC-Bench.
PANORAMA: The Rise of Omnidirectional Vision in the Embodied AI Era
Sep 16, 2025Omnidirectional vision, using 360-degree vision to understand the environment, has become increasingly critical across domains like robotics, industrial inspection, and environmental monitoring. Compared to traditional pinhole vision, omnidirectional vision provides holistic environmental awareness, significantly enhancing the completeness of scene perception and the reliability of decision-making. However, foundational research in this area has historically lagged behind traditional pinhole vision. This talk presents an emerging trend in the embodied AI era: the rapid development of omnidirectional vision, driven by growing industrial demand and academic interest. We highlight recent breakthroughs in omnidirectional generation, omnidirectional perception, omnidirectional understanding, and related datasets. Drawing on insights from both academia and industry, we propose an ideal panoramic system architecture in the embodied AI era, PANORAMA, which consists of four key subsystems. Moreover, we offer in-depth opinions related to emerging trends and cross-community impacts at the intersection of panoramic vision and embodied AI, along with the future roadmap and open challenges. This overview synthesizes state-of-the-art advancements and outlines challenges and opportunities for future research in building robust, general-purpose omnidirectional AI systems in the embodied AI era.
MLLMs are Deeply Affected by Modality Bias
May 24, 2025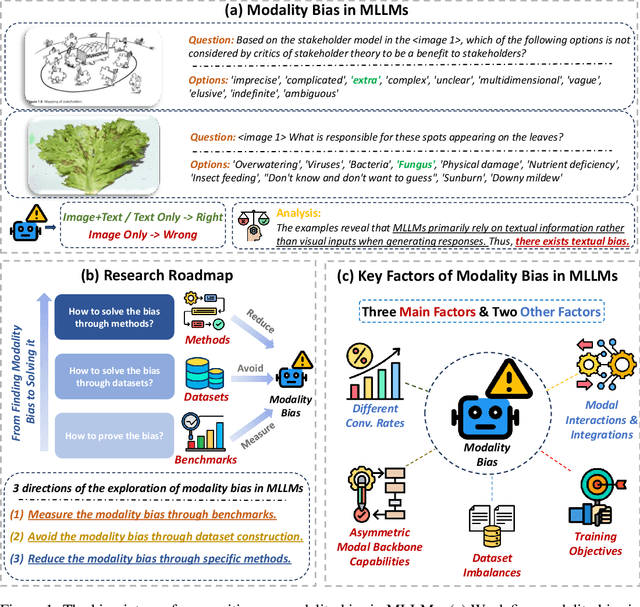
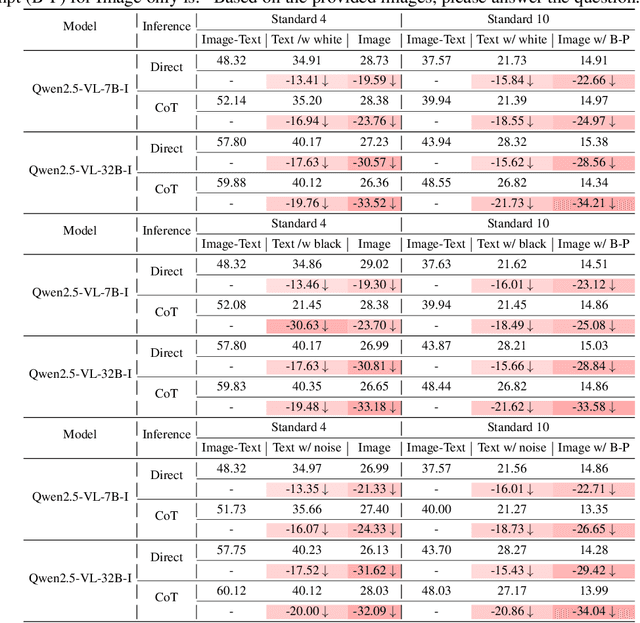
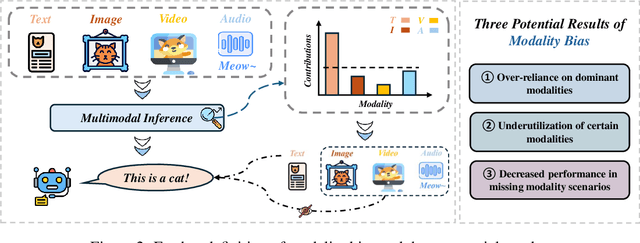
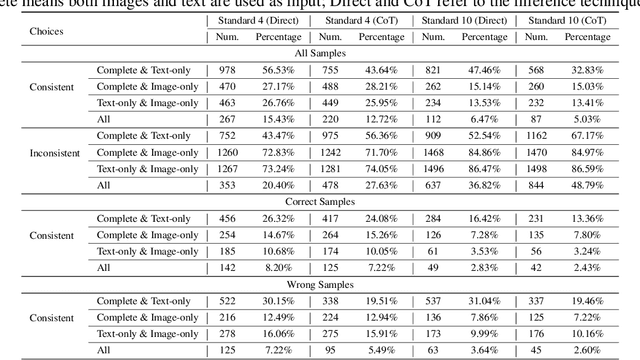
Recent advances in Multimodal Large Language Models (MLLMs) have shown promising results in integrating diverse modalities such as texts and images. MLLMs are heavily influenced by modality bias, often relying on language while under-utilizing other modalities like visual inputs. This position paper argues that MLLMs are deeply affected by modality bias. Firstly, we diagnose the current state of modality bias, highlighting its manifestations across various tasks. Secondly, we propose a systematic research road-map related to modality bias in MLLMs. Thirdly, we identify key factors of modality bias in MLLMs and offer actionable suggestions for future research to mitigate it. To substantiate these findings, we conduct experiments that demonstrate the influence of each factor: 1. Data Characteristics: Language data is compact and abstract, while visual data is redundant and complex, creating an inherent imbalance in learning dynamics. 2. Imbalanced Backbone Capabilities: The dominance of pretrained language models in MLLMs leads to overreliance on language and neglect of visual information. 3. Training Objectives: Current objectives often fail to promote balanced cross-modal alignment, resulting in shortcut learning biased toward language. These findings highlight the need for balanced training strategies and model architectures to better integrate multiple modalities in MLLMs. We call for interdisciplinary efforts to tackle these challenges and drive innovation in MLLM research. Our work provides a fresh perspective on modality bias in MLLMs and offers insights for developing more robust and generalizable multimodal systems-advancing progress toward Artificial General Intelligence.
Are Multimodal Large Language Models Ready for Omnidirectional Spatial Reasoning?
May 17, 2025The 180x360 omnidirectional field of view captured by 360-degree cameras enables their use in a wide range of applications such as embodied AI and virtual reality. Although recent advances in multimodal large language models (MLLMs) have shown promise in visual-spatial reasoning, most studies focus on standard pinhole-view images, leaving omnidirectional perception largely unexplored. In this paper, we ask: Are MLLMs ready for omnidirectional spatial reasoning? To investigate this, we introduce OSR-Bench, the first benchmark specifically designed for this setting. OSR-Bench includes over 153,000 diverse question-answer pairs grounded in high-fidelity panoramic indoor scene maps. It covers key reasoning types including object counting, relative distance, and direction. We also propose a negative sampling strategy that inserts non-existent objects into prompts to evaluate hallucination and grounding robustness. For fine-grained analysis, we design a two-stage evaluation framework assessing both cognitive map generation and QA accuracy using rotation-invariant matching and a combination of rule-based and LLM-based metrics. We evaluate eight state-of-the-art MLLMs, including GPT-4o, Gemini 1.5 Pro, and leading open-source models under zero-shot settings. Results show that current models struggle with spatial reasoning in panoramic contexts, highlighting the need for more perceptually grounded MLLMs. OSR-Bench and code will be released at: https://huggingface.co/datasets/UUUserna/OSR-Bench
Reducing Unimodal Bias in Multi-Modal Semantic Segmentation with Multi-Scale Functional Entropy Regularization
May 10, 2025Fusing and balancing multi-modal inputs from novel sensors for dense prediction tasks, particularly semantic segmentation, is critically important yet remains a significant challenge. One major limitation is the tendency of multi-modal frameworks to over-rely on easily learnable modalities, a phenomenon referred to as unimodal dominance or bias. This issue becomes especially problematic in real-world scenarios where the dominant modality may be unavailable, resulting in severe performance degradation. To this end, we apply a simple but effective plug-and-play regularization term based on functional entropy, which introduces no additional parameters or modules. This term is designed to intuitively balance the contribution of each visual modality to the segmentation results. Specifically, we leverage the log-Sobolev inequality to bound functional entropy using functional-Fisher-information. By maximizing the information contributed by each visual modality, our approach mitigates unimodal dominance and establishes a more balanced and robust segmentation framework. A multi-scale regularization module is proposed to apply our proposed plug-and-play term on high-level features and also segmentation predictions for more balanced multi-modal learning. Extensive experiments on three datasets demonstrate that our proposed method achieves superior performance, i.e., +13.94%, +3.25%, and +3.64%, without introducing any additional parameters.
DiMeR: Disentangled Mesh Reconstruction Model
Apr 24, 2025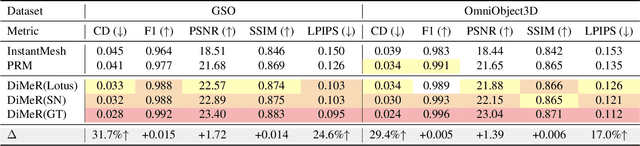

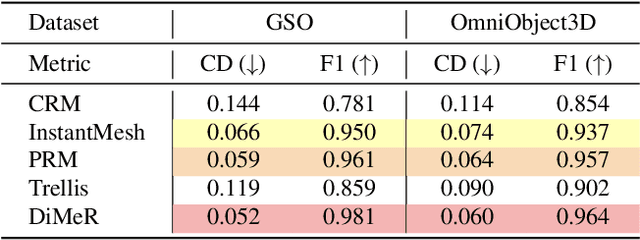
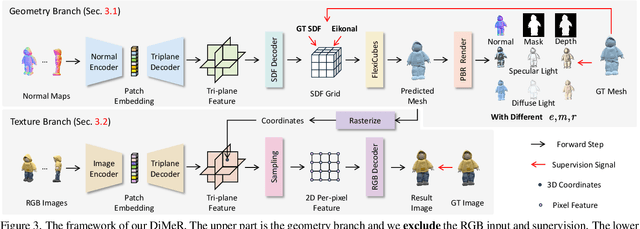
With the advent of large-scale 3D datasets, feed-forward 3D generative models, such as the Large Reconstruction Model (LRM), have gained significant attention and achieved remarkable success. However, we observe that RGB images often lead to conflicting training objectives and lack the necessary clarity for geometry reconstruction. In this paper, we revisit the inductive biases associated with mesh reconstruction and introduce DiMeR, a novel disentangled dual-stream feed-forward model for sparse-view mesh reconstruction. The key idea is to disentangle both the input and framework into geometry and texture parts, thereby reducing the training difficulty for each part according to the Principle of Occam's Razor. Given that normal maps are strictly consistent with geometry and accurately capture surface variations, we utilize normal maps as exclusive input for the geometry branch to reduce the complexity between the network's input and output. Moreover, we improve the mesh extraction algorithm to introduce 3D ground truth supervision. As for texture branch, we use RGB images as input to obtain the textured mesh. Overall, DiMeR demonstrates robust capabilities across various tasks, including sparse-view reconstruction, single-image-to-3D, and text-to-3D. Numerous experiments show that DiMeR significantly outperforms previous methods, achieving over 30% improvement in Chamfer Distance on the GSO and OmniObject3D dataset.