 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLESA: Learnable Stage-Aware Predictors for Diffusion Model Acceleration
Feb 24, 2026Diffusion models have achieved remarkable success in image and video generation tasks. However, the high computational demands of Diffusion Transformers (DiTs) pose a significant challenge to their practical deployment. While feature caching is a promising acceleration strategy, existing methods based on simple reusing or training-free forecasting struggle to adapt to the complex, stage-dependent dynamics of the diffusion process, often resulting in quality degradation and failing to maintain consistency with the standard denoising process. To address this, we propose a LEarnable Stage-Aware (LESA) predictor framework based on two-stage training. Our approach leverages a Kolmogorov-Arnold Network (KAN) to accurately learn temporal feature mappings from data. We further introduce a multi-stage, multi-expert architecture that assigns specialized predictors to different noise-level stages, enabling more precise and robust feature forecasting. Extensive experiments show our method achieves significant acceleration while maintaining high-fidelity generation. Experiments demonstrate 5.00x acceleration on FLUX.1-dev with minimal quality degradation (1.0% drop), 6.25x speedup on Qwen-Image with a 20.2% quality improvement over the previous SOTA (TaylorSeer), and 5.00x acceleration on HunyuanVideo with a 24.7% PSNR improvement over TaylorSeer. State-of-the-art performance on both text-to-image and text-to-video synthesis validates the effectiveness and generalization capability of our training-based framework across different models. Our code is included in the supplementary materials and will be released on GitHub.
DisCa: Accelerating Video Diffusion Transformers with Distillation-Compatible Learnable Feature Caching
Feb 05, 2026While diffusion models have achieved great success in the field of video generation, this progress is accompanied by a rapidly escalating computational burden. Among the existing acceleration methods, Feature Caching is popular due to its training-free property and considerable speedup performance, but it inevitably faces semantic and detail drop with further compression. Another widely adopted method, training-aware step-distillation, though successful in image generation, also faces drastic degradation in video generation with a few steps. Furthermore, the quality loss becomes more severe when simply applying training-free feature caching to the step-distilled models, due to the sparser sampling steps. This paper novelly introduces a distillation-compatible learnable feature caching mechanism for the first time. We employ a lightweight learnable neural predictor instead of traditional training-free heuristics for diffusion models, enabling a more accurate capture of the high-dimensional feature evolution process. Furthermore, we explore the challenges of highly compressed distillation on large-scale video models and propose a conservative Restricted MeanFlow approach to achieve more stable and lossless distillation. By undertaking these initiatives, we further push the acceleration boundaries to $11.8\times$ while preserving generation quality. Extensive experiments demonstrate the effectiveness of our method. The code is in the supplementary materials and will be publicly available.
From Sketch to Fresco: Efficient Diffusion Transformer with Progressive Resolution
Jan 12, 2026Diffusion Transformers achieve impressive generative quality but remain computationally expensive due to iterative sampling. Recently, dynamic resolution sampling has emerged as a promising acceleration technique by reducing the resolution of early sampling steps. However, existing methods rely on heuristic re-noising at every resolution transition, injecting noise that breaks cross-stage consistency and forces the model to relearn global structure. In addition, these methods indiscriminately upsample the entire latent space at once without checking which regions have actually converged, causing accumulated errors, and visible artifacts. Therefore, we propose \textbf{Fresco}, a dynamic resolution framework that unifies re-noise and global structure across stages with progressive upsampling, preserving both the efficiency of low-resolution drafting and the fidelity of high-resolution refinement, with all stages aligned toward the same final target. Fresco achieves near-lossless acceleration across diverse domains and models, including 10$\times$ speedup on FLUX, and 5$\times$ on HunyuanVideo, while remaining orthogonal to distillation, quantization and feature caching, reaching 22$\times$ speedup when combined with distilled models. Our code is in supplementary material and will be released on Github.
HiCache: Training-free Acceleration of Diffusion Models via Hermite Polynomial-based Feature Caching
Aug 23, 2025Diffusion models have achieved remarkable success in content generation but suffer from prohibitive computational costs due to iterative sampling. While recent feature caching methods tend to accelerate inference through temporal extrapolation, these methods still suffer from server quality loss due to the failure in modeling the complex dynamics of feature evolution. To solve this problem, this paper presents HiCache, a training-free acceleration framework that fundamentally improves feature prediction by aligning mathematical tools with empirical properties. Our key insight is that feature derivative approximations in Diffusion Transformers exhibit multivariate Gaussian characteristics, motivating the use of Hermite polynomials-the potentially theoretically optimal basis for Gaussian-correlated processes. Besides, We further introduce a dual-scaling mechanism that ensures numerical stability while preserving predictive accuracy. Extensive experiments demonstrate HiCache's superiority: achieving 6.24x speedup on FLUX.1-dev while exceeding baseline quality, maintaining strong performance across text-to-image, video generation, and super-resolution tasks. Core implementation is provided in the appendix, with complete code to be released upon acceptance.
EfficientVLA: Training-Free Acceleration and Compression for Vision-Language-Action Models
Jun 11, 2025
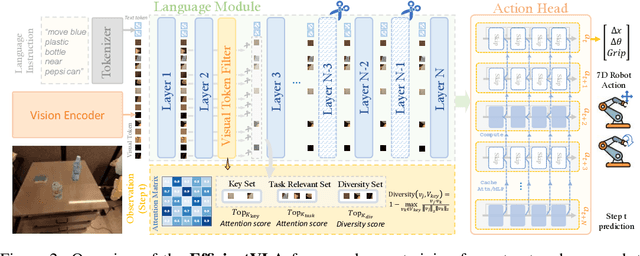

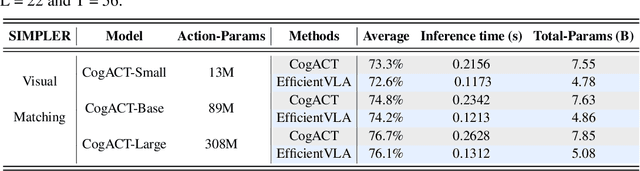
Vision-Language-Action (VLA) models, particularly diffusion-based architectures, demonstrate transformative potential for embodied intelligence but are severely hampered by high computational and memory demands stemming from extensive inherent and inference-time redundancies. While existing acceleration efforts often target isolated inefficiencies, such piecemeal solutions typically fail to holistically address the varied computational and memory bottlenecks across the entire VLA pipeline, thereby limiting practical deployability. We introduce EfficientVLA, a structured and training-free inference acceleration framework that systematically eliminates these barriers by cohesively exploiting multifaceted redundancies. EfficientVLA synergistically integrates three targeted strategies: (1) pruning of functionally inconsequential layers from the language module, guided by an analysis of inter-layer redundancies; (2) optimizing the visual processing pathway through a task-aware strategy that selects a compact, diverse set of visual tokens, balancing task-criticality with informational coverage; and (3) alleviating temporal computational redundancy within the iterative diffusion-based action head by strategically caching and reusing key intermediate features. We apply our method to a standard VLA model CogACT, yielding a 1.93X inference speedup and reduces FLOPs to 28.9%, with only a 0.6% success rate drop in the SIMPLER benchmark.
Shifting AI Efficiency From Model-Centric to Data-Centric Compression
May 25, 2025The rapid advancement of large language models (LLMs) and multi-modal LLMs (MLLMs) has historically relied on model-centric scaling through increasing parameter counts from millions to hundreds of billions to drive performance gains. However, as we approach hardware limits on model size, the dominant computational bottleneck has fundamentally shifted to the quadratic cost of self-attention over long token sequences, now driven by ultra-long text contexts, high-resolution images, and extended videos. In this position paper, \textbf{we argue that the focus of research for efficient AI is shifting from model-centric compression to data-centric compression}. We position token compression as the new frontier, which improves AI efficiency via reducing the number of tokens during model training or inference. Through comprehensive analysis, we first examine recent developments in long-context AI across various domains and establish a unified mathematical framework for existing model efficiency strategies, demonstrating why token compression represents a crucial paradigm shift in addressing long-context overhead. Subsequently, we systematically review the research landscape of token compression, analyzing its fundamental benefits and identifying its compelling advantages across diverse scenarios. Furthermore, we provide an in-depth analysis of current challenges in token compression research and outline promising future directions. Ultimately, our work aims to offer a fresh perspective on AI efficiency, synthesize existing research, and catalyze innovative developments to address the challenges that increasing context lengths pose to the AI community's advancement.
EEdit : Rethinking the Spatial and Temporal Redundancy for Efficient Image Editing
Mar 13, 2025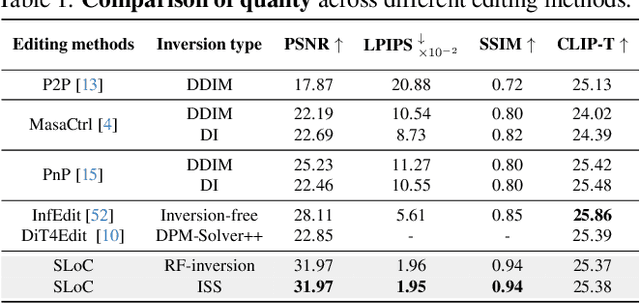
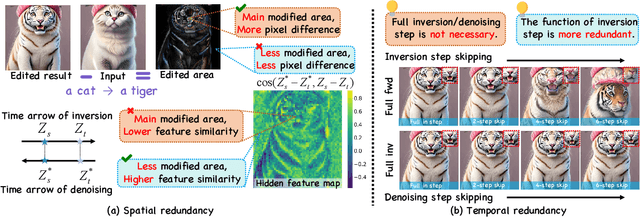
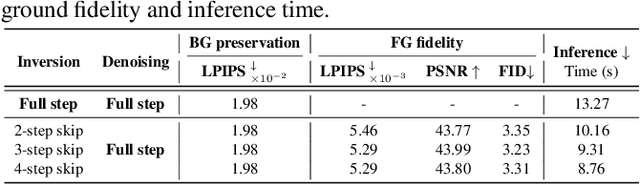
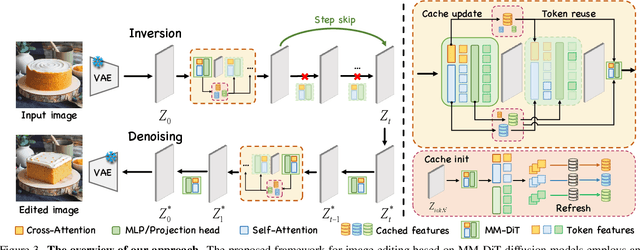
Inversion-based image editing is rapidly gaining momentum while suffering from significant computation overhead, hindering its application in real-time interactive scenarios. In this paper, we rethink that the redundancy in inversion-based image editing exists in both the spatial and temporal dimensions, such as the unnecessary computation in unedited regions and the redundancy in the inversion progress. To tackle these challenges, we propose a practical framework, named EEdit, to achieve efficient image editing. Specifically, we introduce three techniques to solve them one by one. For spatial redundancy, spatial locality caching is introduced to compute the edited region and its neighboring regions while skipping the unedited regions, and token indexing preprocessing is designed to further accelerate the caching. For temporal redundancy, inversion step skipping is proposed to reuse the latent for efficient editing. Our experiments demonstrate an average of 2.46 $\times$ acceleration without performance drop in a wide range of editing tasks including prompt-guided image editing, dragging and image composition. Our codes are available at https://github.com/yuriYanZeXuan/EEdit
From Reusing to Forecasting: Accelerating Diffusion Models with TaylorSeers
Mar 10, 2025Diffusion Transformers (DiT) have revolutionized high-fidelity image and video synthesis, yet their computational demands remain prohibitive for real-time applications. To solve this problem, feature caching has been proposed to accelerate diffusion models by caching the features in the previous timesteps and then reusing them in the following timesteps. However, at timesteps with significant intervals, the feature similarity in diffusion models decreases substantially, leading to a pronounced increase in errors introduced by feature caching, significantly harming the generation quality. To solve this problem, we propose TaylorSeer, which firstly shows that features of diffusion models at future timesteps can be predicted based on their values at previous timesteps. Based on the fact that features change slowly and continuously across timesteps, TaylorSeer employs a differential method to approximate the higher-order derivatives of features and predict features in future timesteps with Taylor series expansion. Extensive experiments demonstrate its significant effectiveness in both image and video synthesis, especially in high acceleration ratios. For instance, it achieves an almost lossless acceleration of 4.99$\times$ on FLUX and 5.00$\times$ on HunyuanVideo without additional training. On DiT, it achieves $3.41$ lower FID compared with previous SOTA at $4.53$$\times$ acceleration. %Our code is provided in the supplementary materials and will be made publicly available on GitHub. Our codes have been released in Github:https://github.com/Shenyi-Z/TaylorSeer
Token Pruning for Caching Better: 9 Times Acceleration on Stable Diffusion for Free
Dec 31, 2024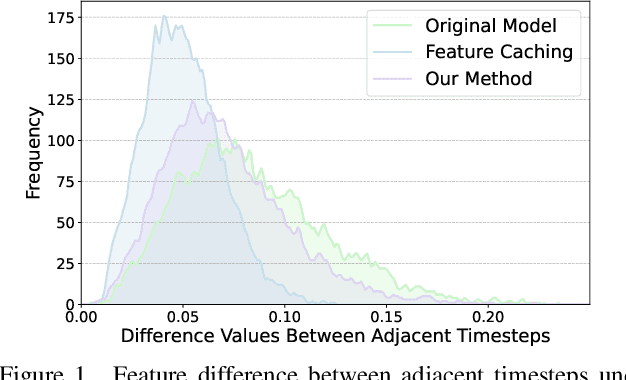
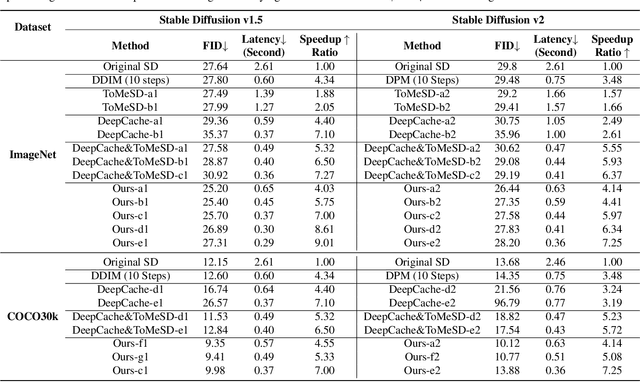

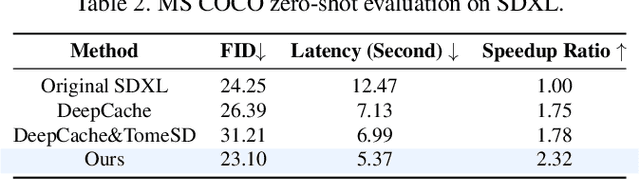
Stable Diffusion has achieved remarkable success in the field of text-to-image generation, with its powerful generative capabilities and diverse generation results making a lasting impact. However, its iterative denoising introduces high computational costs and slows generation speed, limiting broader adoption. The community has made numerous efforts to reduce this computational burden, with methods like feature caching attracting attention due to their effectiveness and simplicity. Nonetheless, simply reusing features computed at previous timesteps causes the features across adjacent timesteps to become similar, reducing the dynamics of features over time and ultimately compromising the quality of generated images. In this paper, we introduce a dynamics-aware token pruning (DaTo) approach that addresses the limitations of feature caching. DaTo selectively prunes tokens with lower dynamics, allowing only high-dynamic tokens to participate in self-attention layers, thereby extending feature dynamics across timesteps. DaTo combines feature caching with token pruning in a training-free manner, achieving both temporal and token-wise information reuse. Applied to Stable Diffusion on the ImageNet, our approach delivered a 9$\times$ speedup while reducing FID by 0.33, indicating enhanced image quality. On the COCO-30k, we observed a 7$\times$ acceleration coupled with a notable FID reduction of 2.17.
Accelerating Diffusion Transformers with Dual Feature Caching
Dec 25, 2024



Diffusion Transformers (DiT) have become the dominant methods in image and video generation yet still suffer substantial computational costs. As an effective approach for DiT acceleration, feature caching methods are designed to cache the features of DiT in previous timesteps and reuse them in the next timesteps, allowing us to skip the computation in the next timesteps. However, on the one hand, aggressively reusing all the features cached in previous timesteps leads to a severe drop in generation quality. On the other hand, conservatively caching only the features in the redundant layers or tokens but still computing the important ones successfully preserves the generation quality but results in reductions in acceleration ratios. Observing such a tradeoff between generation quality and acceleration performance, this paper begins by quantitatively studying the accumulated error from cached features. Surprisingly, we find that aggressive caching does not introduce significantly more caching errors in the caching step, and the conservative feature caching can fix the error introduced by aggressive caching. Thereby, we propose a dual caching strategy that adopts aggressive and conservative caching iteratively, leading to significant acceleration and high generation quality at the same time. Besides, we further introduce a V-caching strategy for token-wise conservative caching, which is compatible with flash attention and requires no training and calibration data. Our codes have been released in Github: \textbf{Code: \href{https://github.com/Shenyi-Z/DuCa}{\texttt{\textcolor{cyan}{https://github.com/Shenyi-Z/DuCa}}}}