 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Diffusion Transformers with Token-wise Feature Caching
Paper and Code
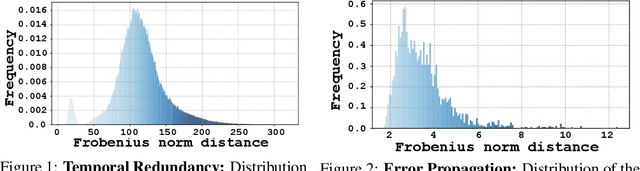
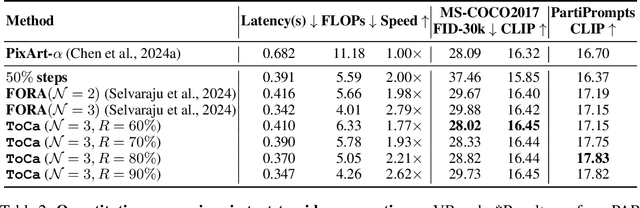
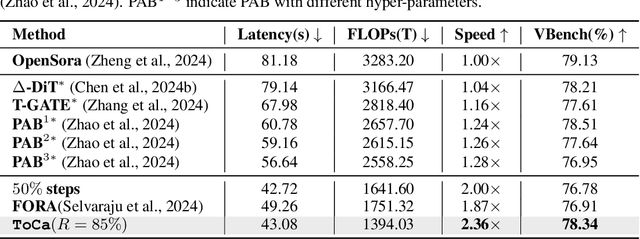
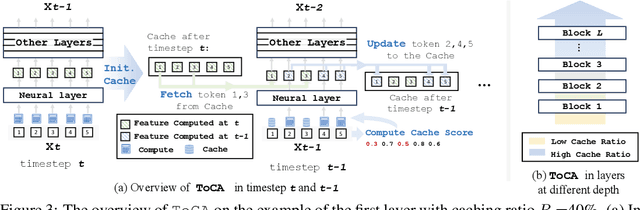
Diffusion transformers have shown significant effectiveness in both image and video synthesis at the expense of huge computation costs. To address this problem, feature caching methods have been introduced to accelerate diffusion transformers by caching the features in previous timesteps and reusing them in the following timesteps. However, previous caching methods ignore that different tokens exhibit different sensitivities to feature caching, and feature caching on some tokens may lead to 10$\times$ more destruction to the overall generation quality compared with other tokens. In this paper, we introduce token-wise feature caching, allowing us to adaptively select the most suitable tokens for caching, and further enable us to apply different caching ratios to neural layers in different types and depths. Extensive experiments on PixArt-$\alpha$, OpenSora, and DiT demonstrate our effectiveness in both image and video generation with no requirements for training. For instance, 2.36$\times$ and 1.93$\times$ acceleration are achieved on OpenSora and PixArt-$\alpha$ with almost no drop in generation quality.