 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulat3D: Reconstructing Articulated Digital Twins From Monocular Videos with Geometric and Motion Constraints
Mar 12, 2026Building high-fidelity digital twins of articulated objects from visual data remains a central challenge. Existing approaches depend on multi-view captures of the object in discrete, static states, which severely constrains their real-world scalability. In this paper, we introduce Articulat3D, a novel framework that constructs such digital twins from casually captured monocular videos by jointly enforcing explicit 3D geometric and motion constraints. We first propose Motion Prior-Driven Initialization, which leverages 3D point tracks to exploit the low-dimensional structure of articulated motion. By modeling scene dynamics with a compact set of motion bases, we facilitate soft decomposition of the scene into multiple rigidly-moving groups. Building on this initialization, we introduce Geometric and Motion Constraints Refinement, which enforces physically plausible articulation through learnable kinematic primitives parameterized by a joint axis, a pivot point, and per-frame motion scalars, yielding reconstructions that are both geometrically accurate and temporally coherent. Extensive experiments demonstrate that Articulat3D achieves state-of-the-art performance on synthetic benchmarks and real-world casually captured monocular videos, significantly advancing the feasibility of digital twin creation under uncontrolled real-world conditions. Our project page is at https://maxwell-zhao.github.io/Articulat3D.
RynnBrain: Open Embodied Foundation Models
Feb 13, 2026Despite rapid progress in multimodal foundation models, embodied intelligence community still lacks a unified, physically grounded foundation model that integrates perception, reasoning, and planning within real-world spatial-temporal dynamics. We introduce RynnBrain, an open-source spatiotemporal foundation model for embodied intelligence. RynnBrain strengthens four core capabilities in a unified framework: comprehensive egocentric understanding, diverse spatiotemporal localization, physically grounded reasoning, and physics-aware planning. The RynnBrain family comprises three foundation model scales (2B, 8B, and 30B-A3B MoE) and four post-trained variants tailored for downstream embodied tasks (i.e., RynnBrain-Nav, RynnBrain-Plan, and RynnBrain-VLA) or complex spatial reasoning tasks (i.e., RynnBrain-CoP). In terms of extensive evaluations on 20 embodied benchmarks and 8 general vision understanding benchmarks, our RynnBrain foundation models largely outperform existing embodied foundation models by a significant margin. The post-trained model suite further substantiates two key potentials of the RynnBrain foundation model: (i) enabling physically grounded reasoning and planning, and (ii) serving as a strong pretrained backbone that can be efficiently adapted to diverse embodied tasks.
HiF-VLA: Hindsight, Insight and Foresight through Motion Representation for Vision-Language-Action Models
Dec 10, 2025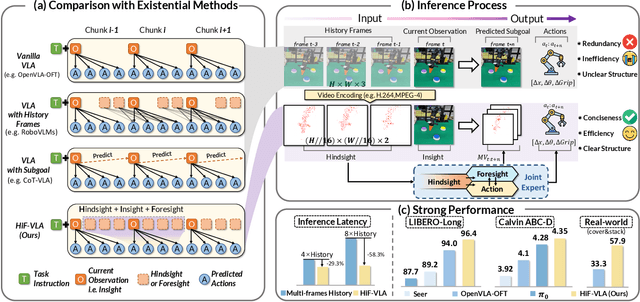
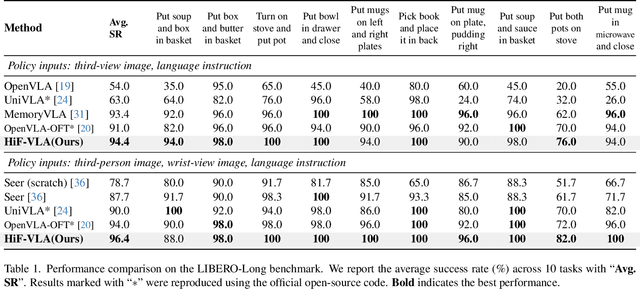
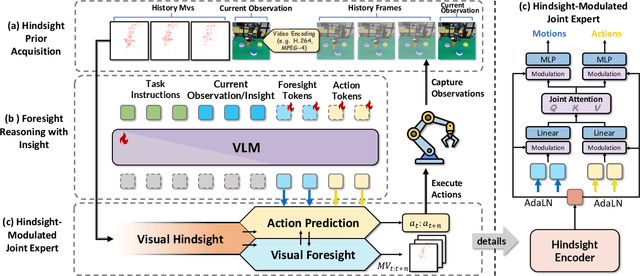
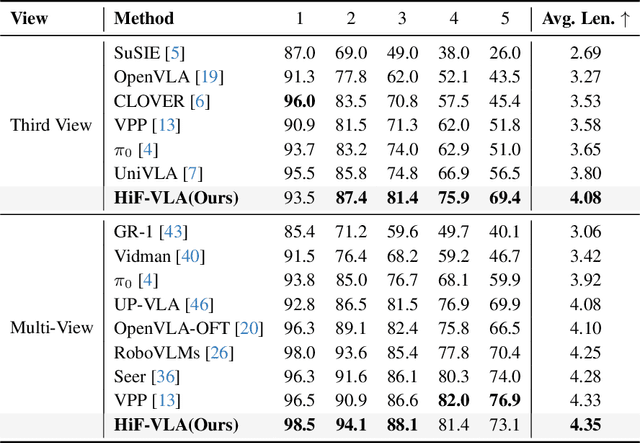
Vision-Language-Action (VLA) models have recently enabled robotic manipulation by grounding visual and linguistic cues into actions. However, most VLAs assume the Markov property, relying only on the current observation and thus suffering from temporal myopia that degrades long-horizon coherence. In this work, we view motion as a more compact and informative representation of temporal context and world dynamics, capturing inter-state changes while filtering static pixel-level noise. Building on this idea, we propose HiF-VLA (Hindsight, Insight, and Foresight for VLAs), a unified framework that leverages motion for bidirectional temporal reasoning. HiF-VLA encodes past dynamics through hindsight priors, anticipates future motion via foresight reasoning, and integrates both through a hindsight-modulated joint expert to enable a ''think-while-acting'' paradigm for long-horizon manipulation. As a result, HiF-VLA surpasses strong baselines on LIBERO-Long and CALVIN ABC-D benchmarks, while incurring negligible additional inference latency. Furthermore, HiF-VLA achieves substantial improvements in real-world long-horizon manipulation tasks, demonstrating its broad effectiveness in practical robotic settings.
RynnVLA-001: Using Human Demonstrations to Improve Robot Manipulation
Sep 18, 2025This paper presents RynnVLA-001, a vision-language-action(VLA) model built upon large-scale video generative pretraining from human demonstrations. We propose a novel two-stage pretraining methodology. The first stage, Ego-Centric Video Generative Pretraining, trains an Image-to-Video model on 12M ego-centric manipulation videos to predict future frames conditioned on an initial frame and a language instruction. The second stage, Human-Centric Trajectory-Aware Modeling, extends this by jointly predicting future keypoint trajectories, thereby effectively bridging visual frame prediction with action prediction. Furthermore, to enhance action representation, we propose ActionVAE, a variational autoencoder that compresses sequences of actions into compact latent embeddings, reducing the complexity of the VLA output space. When finetuned on the same downstream robotics datasets, RynnVLA-001 achieves superior performance over state-of-the-art baselines, demonstrating that the proposed pretraining strategy provides a more effective initialization for VLA models.
VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
Sep 11, 2025Vision-Language-Action (VLA) models typically bridge the gap between perceptual and action spaces by pre-training a large-scale Vision-Language Model (VLM) on robotic data. While this approach greatly enhances performance, it also incurs significant training costs. In this paper, we investigate how to effectively bridge vision-language (VL) representations to action (A). We introduce VLA-Adapter, a novel paradigm designed to reduce the reliance of VLA models on large-scale VLMs and extensive pre-training. To this end, we first systematically analyze the effectiveness of various VL conditions and present key findings on which conditions are essential for bridging perception and action spaces. Based on these insights, we propose a lightweight Policy module with Bridge Attention, which autonomously injects the optimal condition into the action space. In this way, our method achieves high performance using only a 0.5B-parameter backbone, without any robotic data pre-training. Extensive experiments on both simulated and real-world robotic benchmarks demonstrate that VLA-Adapter not only achieves state-of-the-art level performance, but also offers the fast inference speed reported to date. Furthermore, thanks to the proposed advanced bridging paradigm, VLA-Adapter enables the training of a powerful VLA model in just 8 hours on a single consumer-grade GPU, greatly lowering the barrier to deploying the VLA model. Project page: https://vla-adapter.github.io/.
Long-VLA: Unleashing Long-Horizon Capability of Vision Language Action Model for Robot Manipulation
Aug 28, 2025Vision-Language-Action (VLA) models have become a cornerstone in robotic policy learning, leveraging large-scale multimodal data for robust and scalable control. However, existing VLA frameworks primarily address short-horizon tasks, and their effectiveness on long-horizon, multi-step robotic manipulation remains limited due to challenges in skill chaining and subtask dependencies. In this work, we introduce Long-VLA, the first end-to-end VLA model specifically designed for long-horizon robotic tasks. Our approach features a novel phase-aware input masking strategy that adaptively segments each subtask into moving and interaction phases, enabling the model to focus on phase-relevant sensory cues and enhancing subtask compatibility. This unified strategy preserves the scalability and data efficiency of VLA training, and our architecture-agnostic module can be seamlessly integrated into existing VLA models. We further propose the L-CALVIN benchmark to systematically evaluate long-horizon manipulation. Extensive experiments on both simulated and real-world tasks demonstrate that Long-VLA significantly outperforms prior state-of-the-art methods, establishing a new baseline for long-horizon robotic control.
Towards Affordance-Aware Robotic Dexterous Grasping with Human-like Priors
Aug 12, 2025A dexterous hand capable of generalizable grasping objects is fundamental for the development of general-purpose embodied AI. However, previous methods focus narrowly on low-level grasp stability metrics, neglecting affordance-aware positioning and human-like poses which are crucial for downstream manipulation. To address these limitations, we propose AffordDex, a novel framework with two-stage training that learns a universal grasping policy with an inherent understanding of both motion priors and object affordances. In the first stage, a trajectory imitator is pre-trained on a large corpus of human hand motions to instill a strong prior for natural movement. In the second stage, a residual module is trained to adapt these general human-like motions to specific object instances. This refinement is critically guided by two components: our Negative Affordance-aware Segmentation (NAA) module, which identifies functionally inappropriate contact regions, and a privileged teacher-student distillation process that ensures the final vision-based policy is highly successful. Extensive experiments demonstrate that AffordDex not only achieves universal dexterous grasping but also remains remarkably human-like in posture and functionally appropriate in contact location. As a result, AffordDex significantly outperforms state-of-the-art baselines across seen objects, unseen instances, and even entirely novel categories.
WorldVLA: Towards Autoregressive Action World Model
Jun 26, 2025We present WorldVLA, an autoregressive action world model that unifies action and image understanding and generation. Our WorldVLA intergrates Vision-Language-Action (VLA) model and world model in one single framework. The world model predicts future images by leveraging both action and image understanding, with the purpose of learning the underlying physics of the environment to improve action generation. Meanwhile, the action model generates the subsequent actions based on image observations, aiding in visual understanding and in turn helps visual generation of the world model. We demonstrate that WorldVLA outperforms standalone action and world models, highlighting the mutual enhancement between the world model and the action model. In addition, we find that the performance of the action model deteriorates when generating sequences of actions in an autoregressive manner. This phenomenon can be attributed to the model's limited generalization capability for action prediction, leading to the propagation of errors from earlier actions to subsequent ones. To address this issue, we propose an attention mask strategy that selectively masks prior actions during the generation of the current action, which shows significant performance improvement in the action chunk generation task.
VARD: Efficient and Dense Fine-Tuning for Diffusion Models with Value-based RL
May 21, 2025



Diffusion models have emerged as powerful generative tools across various domains, yet tailoring pre-trained models to exhibit specific desirable properties remains challenging. While reinforcement learning (RL) offers a promising solution,current methods struggle to simultaneously achieve stable, efficient fine-tuning and support non-differentiable rewards. Furthermore, their reliance on sparse rewards provides inadequate supervision during intermediate steps, often resulting in suboptimal generation quality. To address these limitations, dense and differentiable signals are required throughout the diffusion process. Hence, we propose VAlue-based Reinforced Diffusion (VARD): a novel approach that first learns a value function predicting expection of rewards from intermediate states, and subsequently uses this value function with KL regularization to provide dense supervision throughout the generation process. Our method maintains proximity to the pretrained model while enabling effective and stable training via backpropagation. Experimental results demonstrate that our approach facilitates better trajectory guidance, improves training efficiency and extends the applicability of RL to diffusion models optimized for complex, non-differentiable reward functions.
SSR: Enhancing Depth Perception in Vision-Language Models via Rationale-Guided Spatial Reasoning
May 18, 2025



Despite impressive advancements in Visual-Language Models (VLMs) for multi-modal tasks, their reliance on RGB inputs limits precise spatial understanding. Existing methods for integrating spatial cues, such as point clouds or depth, either require specialized sensors or fail to effectively exploit depth information for higher-order reasoning. To this end, we propose a novel Spatial Sense and Reasoning method, dubbed SSR, a novel framework that transforms raw depth data into structured, interpretable textual rationales. These textual rationales serve as meaningful intermediate representations to significantly enhance spatial reasoning capabilities. Additionally, we leverage knowledge distillation to compress the generated rationales into compact latent embeddings, which facilitate resource-efficient and plug-and-play integration into existing VLMs without retraining. To enable comprehensive evaluation, we introduce a new dataset named SSR-CoT, a million-scale visual-language reasoning dataset enriched with intermediate spatial reasoning annotations, and present SSRBench, a comprehensive multi-task benchmark. Extensive experiments on multiple benchmarks demonstrate SSR substantially improves depth utilization and enhances spatial reasoning, thereby advancing VLMs toward more human-like multi-modal understanding. Our project page is at https://yliu-cs.github.io/SSR.