 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMPT: Decoupled Modality-aware Prompt Tuning for Multi-modal Object Re-identification
Apr 15, 2025Current multi-modal object re-identification approaches based on large-scale pre-trained backbones (i.e., ViT) have displayed remarkable progress and achieved excellent performance. However, these methods usually adopt the standard full fine-tuning paradigm, which requires the optimization of considerable backbone parameters, causing extensive computational and storage requirements. In this work, we propose an efficient prompt-tuning framework tailored for multi-modal object re-identification, dubbed DMPT, which freezes the main backbone and only optimizes several newly added decoupled modality-aware parameters. Specifically, we explicitly decouple the visual prompts into modality-specific prompts which leverage prior modality knowledge from a powerful text encoder and modality-independent semantic prompts which extract semantic information from multi-modal inputs, such as visible, near-infrared, and thermal-infrared. Built upon the extracted features, we further design a Prompt Inverse Bind (PromptIBind) strategy that employs bind prompts as a medium to connect the semantic prompt tokens of different modalities and facilitates the exchange of complementary multi-modal information, boosting final re-identification results. Experimental results on multiple common benchmarks demonstrate that our DMPT can achieve competitive results to existing state-of-the-art methods while requiring only 6.5% fine-tuning of the backbone parameters.
NTIRE 2025 Challenge on Cross-Domain Few-Shot Object Detection: Methods and Results
Apr 14, 2025Cross-Domain Few-Shot Object Detection (CD-FSOD) poses significant challenges to existing object detection and few-shot detection models when applied across domains. In conjunction with NTIRE 2025, we organized the 1st CD-FSOD Challenge, aiming to advance the performance of current object detectors on entirely novel target domains with only limited labeled data. The challenge attracted 152 registered participants, received submissions from 42 teams, and concluded with 13 teams making valid final submissions. Participants approached the task from diverse perspectives, proposing novel models that achieved new state-of-the-art (SOTA) results under both open-source and closed-source settings. In this report, we present an overview of the 1st NTIRE 2025 CD-FSOD Challenge, highlighting the proposed solutions and summarizing the results submitted by the participants.
Exploring the Evolution of Physics Cognition in Video Generation: A Survey
Mar 27, 2025Recent advancements in video generation have witnessed significant progress, especially with the rapid advancement of diffusion models. Despite this, their deficiencies in physical cognition have gradually received widespread attention - generated content often violates the fundamental laws of physics, falling into the dilemma of ''visual realism but physical absurdity". Researchers began to increasingly recognize the importance of physical fidelity in video generation and attempted to integrate heuristic physical cognition such as motion representations and physical knowledge into generative systems to simulate real-world dynamic scenarios. Considering the lack of a systematic overview in this field, this survey aims to provide a comprehensive summary of architecture designs and their applications to fill this gap. Specifically, we discuss and organize the evolutionary process of physical cognition in video generation from a cognitive science perspective, while proposing a three-tier taxonomy: 1) basic schema perception for generation, 2) passive cognition of physical knowledge for generation, and 3) active cognition for world simulation, encompassing state-of-the-art methods, classical paradigms, and benchmarks. Subsequently, we emphasize the inherent key challenges in this domain and delineate potential pathways for future research, contributing to advancing the frontiers of discussion in both academia and industry. Through structured review and interdisciplinary analysis, this survey aims to provide directional guidance for developing interpretable, controllable, and physically consistent video generation paradigms, thereby propelling generative models from the stage of ''visual mimicry'' towards a new phase of ''human-like physical comprehension''.
HyRSM++: Hybrid Relation Guided Temporal Set Matching for Few-shot Action Recognition
Jan 09, 2023



Recent attempts mainly focus on learning deep representations for each video individually under the episodic meta-learning regime and then performing temporal alignment to match query and support videos. However, they still suffer from two drawbacks: (i) learning individual features without considering the entire task may result in limited representation capability, and (ii) existing alignment strategies are sensitive to noises and misaligned instances. To handle the two limitations, we propose a novel Hybrid Relation guided temporal Set Matching (HyRSM++) approach for few-shot action recognition. The core idea of HyRSM++ is to integrate all videos within the task to learn discriminative representations and involve a robust matching technique. To be specific, HyRSM++ consists of two key components, a hybrid relation module and a temporal set matching metric. Given the basic representations from the feature extractor, the hybrid relation module is introduced to fully exploit associated relations within and cross videos in an episodic task and thus can learn task-specific embeddings. Subsequently, in the temporal set matching metric, we carry out the distance measure between query and support videos from a set matching perspective and design a Bi-MHM to improve the resilience to misaligned instances. In addition, we explicitly exploit the temporal coherence in videos to regularize the matching process. Furthermore, we extend the proposed HyRSM++ to deal with the more challenging semi-supervised few-shot action recognition and unsupervised few-shot action recognition tasks. Experimental results on multiple benchmarks demonstrate that our method achieves state-of-the-art performance under various few-shot settings. The source code is available at https://github.com/alibaba-mmai-research/HyRSMPlusPlus.
Hybrid Relation Guided Set Matching for Few-shot Action Recognition
Apr 28, 2022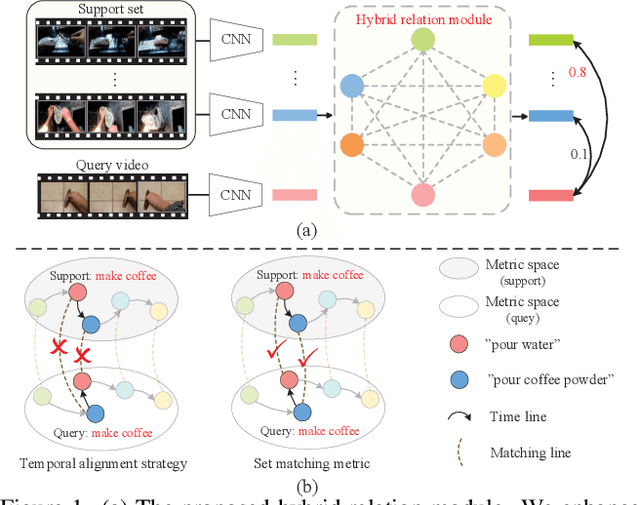
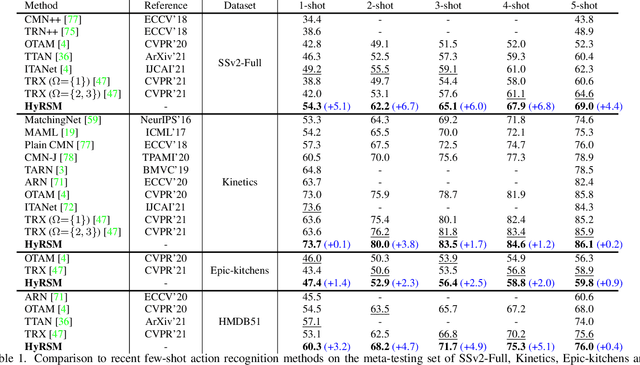
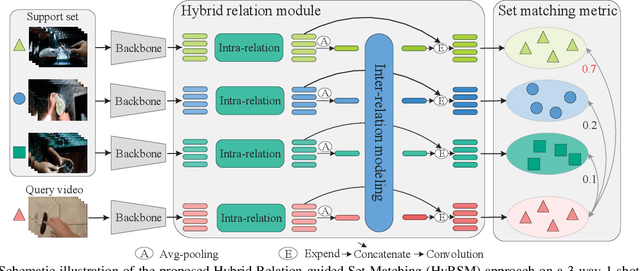
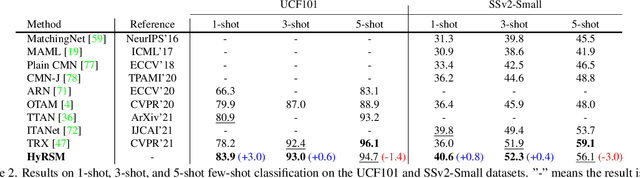
Current few-shot action recognition methods reach impressive performance by learning discriminative features for each video via episodic training and designing various temporal alignment strategies. Nevertheless, they are limited in that (a) learning individual features without considering the entire task may lose the most relevant information in the current episode, and (b) these alignment strategies may fail in misaligned instances. To overcome the two limitations, we propose a novel Hybrid Relation guided Set Matching (HyRSM) approach that incorporates two key components: hybrid relation module and set matching metric. The purpose of the hybrid relation module is to learn task-specific embeddings by fully exploiting associated relations within and cross videos in an episode. Built upon the task-specific features, we reformulate distance measure between query and support videos as a set matching problem and further design a bidirectional Mean Hausdorff Metric to improve the resilience to misaligned instances. By this means, the proposed HyRSM can be highly informative and flexible to predict query categories under the few-shot settings. We evaluate HyRSM on six challenging benchmarks, and the experimental results show its superiority over the state-of-the-art methods by a convincing margin. Project page: https://hyrsm-cvpr2022.github.io/.
OadTR: Online Action Detection with Transformers
Jun 21, 2021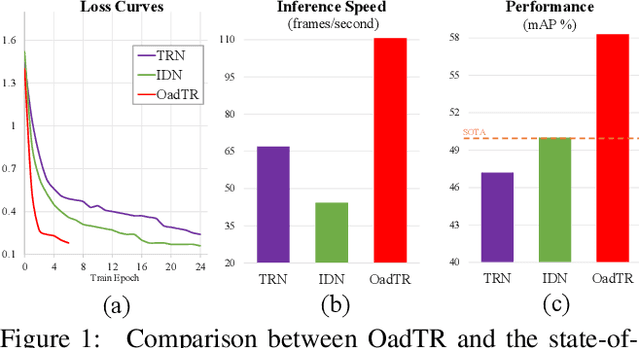

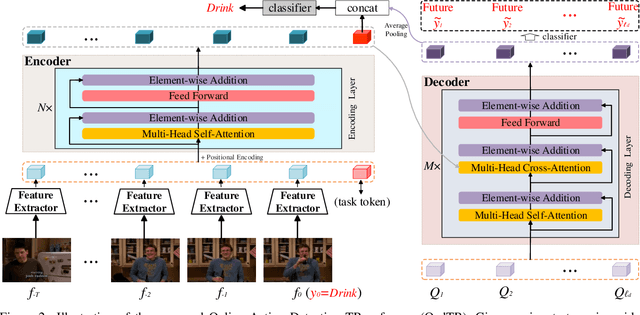
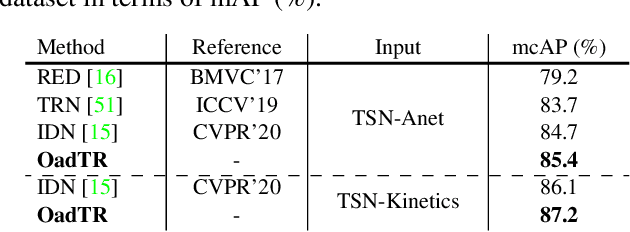
Most recent approaches for online action detection tend to apply Recurrent Neural Network (RNN) to capture long-range temporal structure. However, RNN suffers from non-parallelism and gradient vanishing, hence it is hard to be optimized. In this paper, we propose a new encoder-decoder framework based on Transformers, named OadTR, to tackle these problems. The encoder attached with a task token aims to capture the relationships and global interactions between historical observations. The decoder extracts auxiliary information by aggregating anticipated future clip representations. Therefore, OadTR can recognize current actions by encoding historical information and predicting future context simultaneously. We extensively evaluate the proposed OadTR on three challenging datasets: HDD, TVSeries, and THUMOS14. The experimental results show that OadTR achieves higher training and inference speeds than current RNN based approaches, and significantly outperforms the state-of-the-art methods in terms of both mAP and mcAP. Code is available at https://github.com/wangxiang1230/OadTR.