 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Kolmogorov-Arnold Deep Model in Medical Image Segmentation
Feb 03, 2026Deeply stacked KANs are practically impossible due to high training difficulties and substantial memory requirements. Consequently, existing studies can only incorporate few KAN layers, hindering the comprehensive exploration of KANs. This study overcomes these limitations and introduces the first fully KA-based deep model, demonstrating that KA-based layers can entirely replace traditional architectures in deep learning and achieve superior learning capacity. Specifically, (1) the proposed Share-activation KAN (SaKAN) reformulates Sprecher's variant of Kolmogorov-Arnold representation theorem, which achieves better optimization due to its simplified parameterization and denser training samples, to ease training difficulty, (2) this paper indicates that spline gradients contribute negligibly to training while consuming huge GPU memory, thus proposes the Grad-Free Spline to significantly reduce memory usage and computational overhead. (3) Building on these two innovations, our ALL U-KAN is the first representative implementation of fully KA-based deep model, where the proposed KA and KAonv layers completely replace FC and Conv layers. Extensive evaluations on three medical image segmentation tasks confirm the superiority of the full KA-based architecture compared to partial KA-based and traditional architectures, achieving all higher segmentation accuracy. Compared to directly deeply stacked KAN, ALL U-KAN achieves 10 times reduction in parameter count and reduces memory consumption by more than 20 times, unlocking the new explorations into deep KAN architectures.
Ambiguity-aware Truncated Flow Matching for Ambiguous Medical Image Segmentation
Nov 10, 2025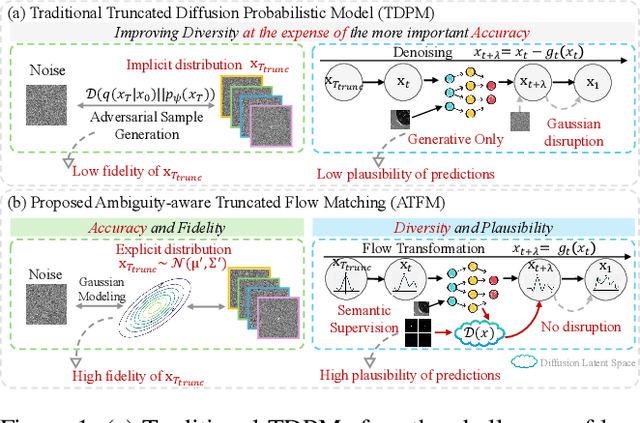
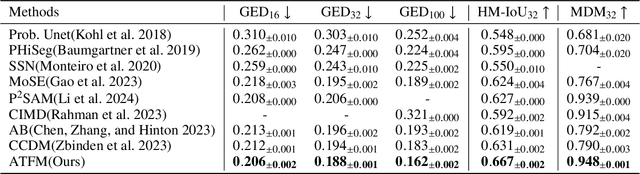
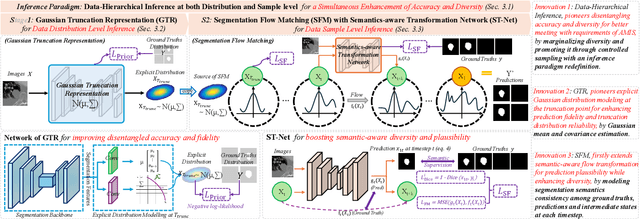
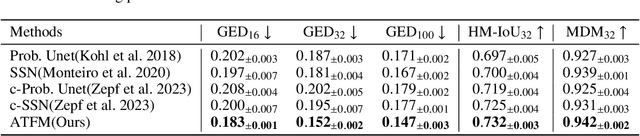
A simultaneous enhancement of accuracy and diversity of predictions remains a challenge in ambiguous medical image segmentation (AMIS) due to the inherent trade-offs. While truncated diffusion probabilistic models (TDPMs) hold strong potential with a paradigm optimization, existing TDPMs suffer from entangled accuracy and diversity of predictions with insufficient fidelity and plausibility. To address the aforementioned challenges, we propose Ambiguity-aware Truncated Flow Matching (ATFM), which introduces a novel inference paradigm and dedicated model components. Firstly, we propose Data-Hierarchical Inference, a redefinition of AMIS-specific inference paradigm, which enhances accuracy and diversity at data-distribution and data-sample level, respectively, for an effective disentanglement. Secondly, Gaussian Truncation Representation (GTR) is introduced to enhance both fidelity of predictions and reliability of truncation distribution, by explicitly modeling it as a Gaussian distribution at $T_{\text{trunc}}$ instead of using sampling-based approximations.Thirdly, Segmentation Flow Matching (SFM) is proposed to enhance the plausibility of diverse predictions by extending semantic-aware flow transformation in Flow Matching (FM). Comprehensive evaluations on LIDC and ISIC3 datasets demonstrate that ATFM outperforms SOTA methods and simultaneously achieves a more efficient inference. ATFM improves GED and HM-IoU by up to $12\%$ and $7.3\%$ compared to advanced methods.
Structure and Smoothness Constrained Dual Networks for MR Bias Field Correction
Jul 02, 2025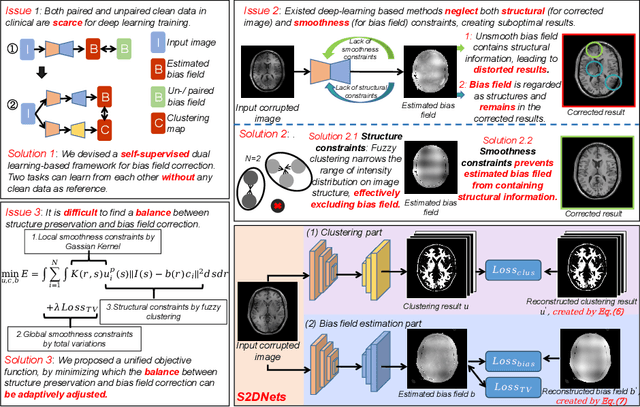
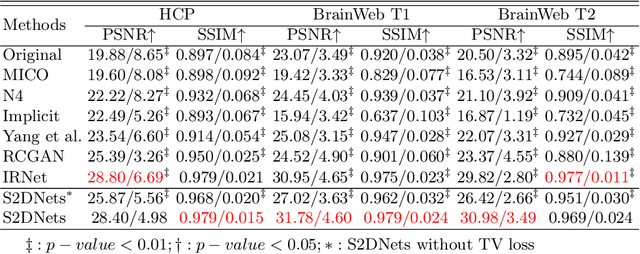
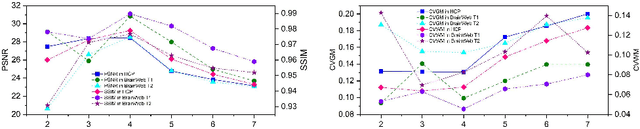
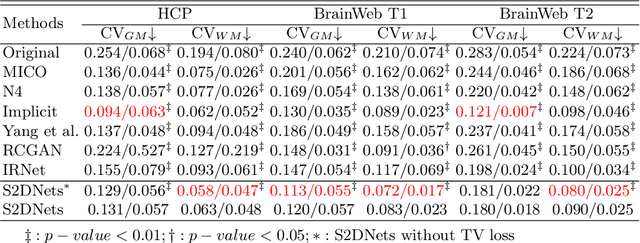
MR imaging techniques are of great benefit to disease diagnosis. However, due to the limitation of MR devices, significant intensity inhomogeneity often exists in imaging results, which impedes both qualitative and quantitative medical analysis. Recently, several unsupervised deep learning-based models have been proposed for MR image improvement. However, these models merely concentrate on global appearance learning, and neglect constraints from image structures and smoothness of bias field, leading to distorted corrected results. In this paper, novel structure and smoothness constrained dual networks, named S2DNets, are proposed aiming to self-supervised bias field correction. S2DNets introduce piece-wise structural constraints and smoothness of bias field for network training to effectively remove non-uniform intensity and retain much more structural details. Extensive experiments executed on both clinical and simulated MR datasets show that the proposed model outperforms other conventional and deep learning-based models. In addition to comparison on visual metrics, downstream MR image segmentation tasks are also used to evaluate the impact of the proposed model. The source code is available at: https://github.com/LeongDong/S2DNets}{https://github.com/LeongDong/S2DNets.
* 11 pages, 3 figures, accepted by MICCAI
Domain-RAG: Retrieval-Guided Compositional Image Generation for Cross-Domain Few-Shot Object Detection
Jun 06, 2025Cross-Domain Few-Shot Object Detection (CD-FSOD) aims to detect novel objects with only a handful of labeled samples from previously unseen domains. While data augmentation and generative methods have shown promise in few-shot learning, their effectiveness for CD-FSOD remains unclear due to the need for both visual realism and domain alignment. Existing strategies, such as copy-paste augmentation and text-to-image generation, often fail to preserve the correct object category or produce backgrounds coherent with the target domain, making them non-trivial to apply directly to CD-FSOD. To address these challenges, we propose Domain-RAG, a training-free, retrieval-guided compositional image generation framework tailored for CD-FSOD. Domain-RAG consists of three stages: domain-aware background retrieval, domain-guided background generation, and foreground-background composition. Specifically, the input image is first decomposed into foreground and background regions. We then retrieve semantically and stylistically similar images to guide a generative model in synthesizing a new background, conditioned on both the original and retrieved contexts. Finally, the preserved foreground is composed with the newly generated domain-aligned background to form the generated image. Without requiring any additional supervision or training, Domain-RAG produces high-quality, domain-consistent samples across diverse tasks, including CD-FSOD, remote sensing FSOD, and camouflaged FSOD. Extensive experiments show consistent improvements over strong baselines and establish new state-of-the-art results. Codes will be released upon acceptance.
NTIRE 2025 Challenge on Cross-Domain Few-Shot Object Detection: Methods and Results
Apr 14, 2025Cross-Domain Few-Shot Object Detection (CD-FSOD) poses significant challenges to existing object detection and few-shot detection models when applied across domains. In conjunction with NTIRE 2025, we organized the 1st CD-FSOD Challenge, aiming to advance the performance of current object detectors on entirely novel target domains with only limited labeled data. The challenge attracted 152 registered participants, received submissions from 42 teams, and concluded with 13 teams making valid final submissions. Participants approached the task from diverse perspectives, proposing novel models that achieved new state-of-the-art (SOTA) results under both open-source and closed-source settings. In this report, we present an overview of the 1st NTIRE 2025 CD-FSOD Challenge, highlighting the proposed solutions and summarizing the results submitted by the participants.
Finding Local Diffusion Schrödinger Bridge using Kolmogorov-Arnold Network
Feb 27, 2025In image generation, Schr\"odinger Bridge (SB)-based methods theoretically enhance the efficiency and quality compared to the diffusion models by finding the least costly path between two distributions. However, they are computationally expensive and time-consuming when applied to complex image data. The reason is that they focus on fitting globally optimal paths in high-dimensional spaces, directly generating images as next step on the path using complex networks through self-supervised training, which typically results in a gap with the global optimum. Meanwhile, most diffusion models are in the same path subspace generated by weights $f_A(t)$ and $f_B(t)$, as they follow the paradigm ($x_t = f_A(t)x_{Img} + f_B(t)\epsilon$). To address the limitations of SB-based methods, this paper proposes for the first time to find local Diffusion Schr\"odinger Bridges (LDSB) in the diffusion path subspace, which strengthens the connection between the SB problem and diffusion models. Specifically, our method optimizes the diffusion paths using Kolmogorov-Arnold Network (KAN), which has the advantage of resistance to forgetting and continuous output. The experiment shows that our LDSB significantly improves the quality and efficiency of image generation using the same pre-trained denoising network and the KAN for optimising is only less than 0.1MB. The FID metric is reduced by \textbf{more than 15\%}, especially with a reduction of 48.50\% when NFE of DDIM is $5$ for the CelebA dataset. Code is available at https://github.com/Qiu-XY/LDSB.
Cross-Domain Few-Shot Object Detection via Enhanced Open-Set Object Detector
Feb 05, 2024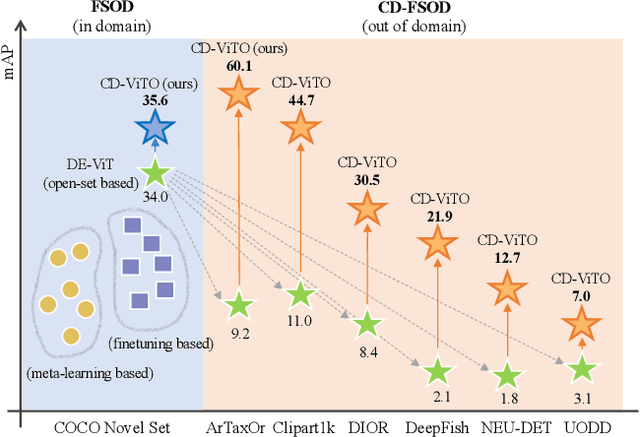

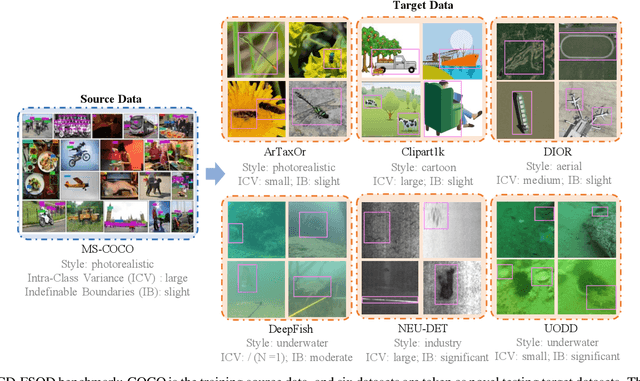

This paper addresses the challenge of cross-domain few-shot object detection (CD-FSOD), aiming to develop an accurate object detector for novel domains with minimal labeled examples. While transformer-based open-set detectors e.g., DE-ViT~\cite{zhang2023detect} have excelled in both open-vocabulary object detection and traditional few-shot object detection, detecting categories beyond those seen during training, we thus naturally raise two key questions: 1) can such open-set detection methods easily generalize to CD-FSOD? 2) If no, how to enhance the results of open-set methods when faced with significant domain gaps? To address the first question, we introduce several metrics to quantify domain variances and establish a new CD-FSOD benchmark with diverse domain metric values. Some State-Of-The-Art (SOTA) open-set object detection methods are evaluated on this benchmark, with evident performance degradation observed across out-of-domain datasets. This indicates the failure of adopting open-set detectors directly for CD-FSOD. Sequentially, to overcome the performance degradation issue and also to answer the second proposed question, we endeavor to enhance the vanilla DE-ViT. With several novel components including finetuning, a learnable prototype module, and a lightweight attention module, we present an improved Cross-Domain Vision Transformer for CD-FSOD (CD-ViTO). Experiments show that our CD-ViTO achieves impressive results on both out-of-domain and in-domain target datasets, establishing new SOTAs for both CD-FSOD and FSOD. All the datasets, codes, and models will be released to the community.
Unsupervised Decomposition Networks for Bias Field Correction in MR Image
Jul 30, 2023



Bias field, which is caused by imperfect MR devices or imaged objects, introduces intensity inhomogeneity into MR images and degrades the performance of MR image analysis methods. Many retrospective algorithms were developed to facilitate the bias correction, to which the deep learning-based methods outperformed. However, in the training phase, the supervised deep learning-based methods heavily rely on the synthesized bias field. As the formation of the bias field is extremely complex, it is difficult to mimic the true physical property of MR images by synthesized data. While bias field correction and image segmentation are strongly related, the segmentation map is precisely obtained by decoupling the bias field from the original MR image, and the bias value is indicated by the segmentation map in reverse. Thus, we proposed novel unsupervised decomposition networks that are trained only with biased data to obtain the bias-free MR images. Networks are made up of: a segmentation part to predict the probability of every pixel belonging to each class, and an estimation part to calculate the bias field, which are optimized alternately. Furthermore, loss functions based on the combination of fuzzy clustering and the multiplicative bias field are also devised. The proposed loss functions introduce the smoothness of bias field and construct the soft relationships among different classes under intra-consistency constraints. Extensive experiments demonstrate that the proposed method can accurately estimate bias fields and produce better bias correction results. The code is available on the link: https://github.com/LeongDong/Bias-Decomposition-Networks.