 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMASH: Mastering Scalable Whole-Body Skills for Humanoid Ping-Pong with Egocentric Vision
Apr 01, 2026Existing humanoid table tennis systems remain limited by their reliance on external sensing and their inability to achieve agile whole-body coordination for precise task execution. These limitations stem from two core challenges: achieving low-latency and robust onboard egocentric perception under fast robot motion, and obtaining sufficiently diverse task-aligned strike motions for learning precise yet natural whole-body behaviors. In this work, we present \methodname, a modular system for agile humanoid table tennis that unifies scalable whole-body skill learning with onboard egocentric perception, eliminating the need for external cameras during deployment. Our work advances prior humanoid table-tennis systems in three key aspects. First, we achieve agile and precise ball interaction with tightly coordinated whole-body control, rather than relying on decoupled upper- and lower-body behaviors. This enables the system to exhibit diverse strike motions, including explosive whole-body smashes and low crouching shots. Second, by augmenting and diversifying strike motions with a generative model, our framework benefits from scalable motion priors and produces natural, robust striking behaviors across a wide workspace. Third, to the best of our knowledge, we demonstrate the first humanoid table-tennis system capable of consecutive strikes using onboard sensing alone, despite the challenges of low-latency perception, ego-motion-induced instability, and limited field of view. Extensive real-world experiments demonstrate stable and precise ball exchanges under high-speed conditions, validating scalable, perception-driven whole-body skill learning for dynamic humanoid interaction tasks.
AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
Mar 09, 2025We explore how scalable robot data can address real-world challenges for generalized robotic manipulation. Introducing AgiBot World, a large-scale platform comprising over 1 million trajectories across 217 tasks in five deployment scenarios, we achieve an order-of-magnitude increase in data scale compared to existing datasets. Accelerated by a standardized collection pipeline with human-in-the-loop verification, AgiBot World guarantees high-quality and diverse data distribution. It is extensible from grippers to dexterous hands and visuo-tactile sensors for fine-grained skill acquisition. Building on top of data, we introduce Genie Operator-1 (GO-1), a novel generalist policy that leverages latent action representations to maximize data utilization, demonstrating predictable performance scaling with increased data volume. Policies pre-trained on our dataset achieve an average performance improvement of 30% over those trained on Open X-Embodiment, both in in-domain and out-of-distribution scenarios. GO-1 exhibits exceptional capability in real-world dexterous and long-horizon tasks, achieving over 60% success rate on complex tasks and outperforming prior RDT approach by 32%. By open-sourcing the dataset, tools, and models, we aim to democratize access to large-scale, high-quality robot data, advancing the pursuit of scalable and general-purpose intelligence.
KALE-LM: Unleash The Power Of AI For Science Via Knowledge And Logic Enhanced Large Model
Sep 27, 2024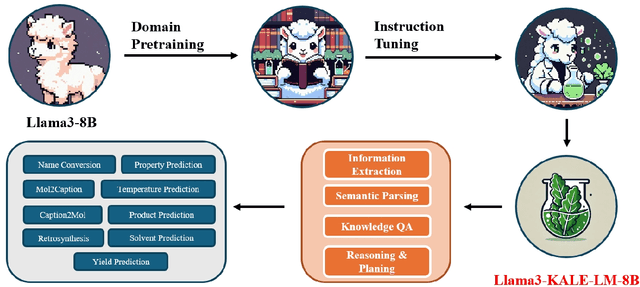
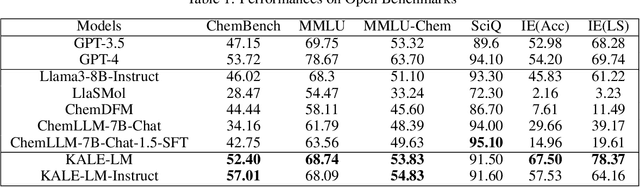
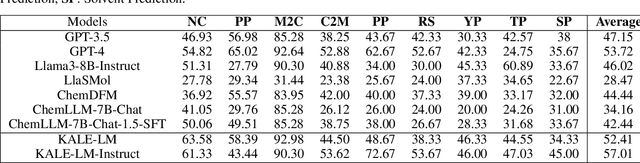
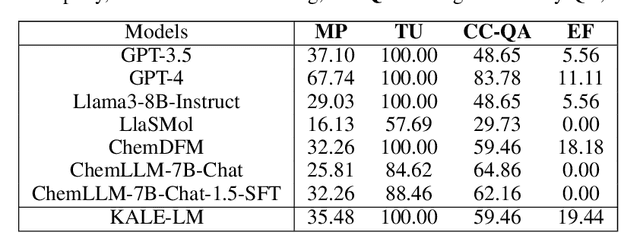
Artificial intelligence is gradually demonstrating its immense potential, and increasing attention is being given to how AI can be harnessed to advance scientific research. In this vision paper, we present our perspectives on how AI can better assist scientific inquiry and explore corresponding technical approach. We have proposed and open-sourced a large model of our KALE-LM model series, Llama3-KALE-LM-Chem-8B, which has achieved outstanding performance in tasks related to the field of chemistry. We hope that our work serves as a strong starting point, helping to realize more intelligent AI and promoting the advancement of human science and technology, as well as societal development.
Cross-Domain Few-Shot Object Detection via Enhanced Open-Set Object Detector
Feb 05, 2024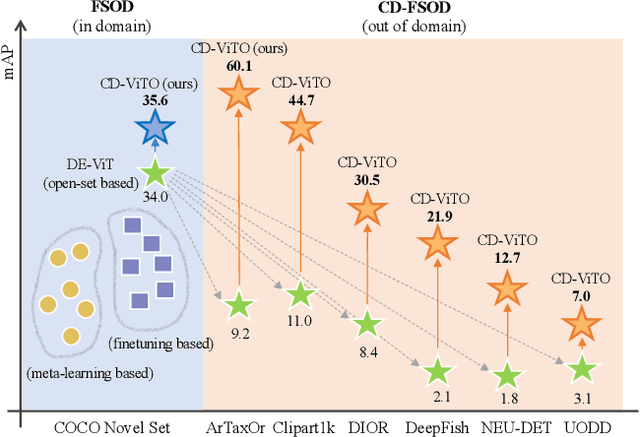

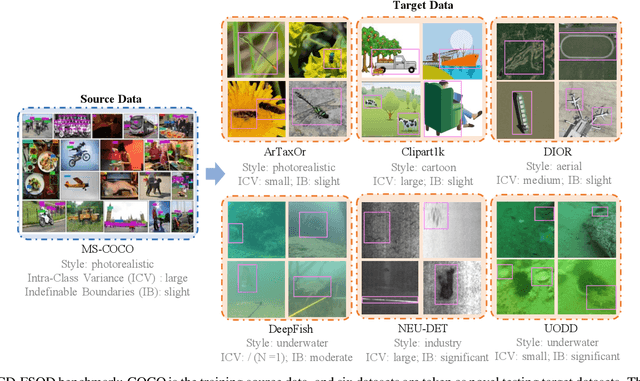

This paper addresses the challenge of cross-domain few-shot object detection (CD-FSOD), aiming to develop an accurate object detector for novel domains with minimal labeled examples. While transformer-based open-set detectors e.g., DE-ViT~\cite{zhang2023detect} have excelled in both open-vocabulary object detection and traditional few-shot object detection, detecting categories beyond those seen during training, we thus naturally raise two key questions: 1) can such open-set detection methods easily generalize to CD-FSOD? 2) If no, how to enhance the results of open-set methods when faced with significant domain gaps? To address the first question, we introduce several metrics to quantify domain variances and establish a new CD-FSOD benchmark with diverse domain metric values. Some State-Of-The-Art (SOTA) open-set object detection methods are evaluated on this benchmark, with evident performance degradation observed across out-of-domain datasets. This indicates the failure of adopting open-set detectors directly for CD-FSOD. Sequentially, to overcome the performance degradation issue and also to answer the second proposed question, we endeavor to enhance the vanilla DE-ViT. With several novel components including finetuning, a learnable prototype module, and a lightweight attention module, we present an improved Cross-Domain Vision Transformer for CD-FSOD (CD-ViTO). Experiments show that our CD-ViTO achieves impressive results on both out-of-domain and in-domain target datasets, establishing new SOTAs for both CD-FSOD and FSOD. All the datasets, codes, and models will be released to the community.
A Data-Driven Analytical Framework of Estimating Multimodal Travel Demand Patterns using Mobile Device Location Data
Dec 08, 2020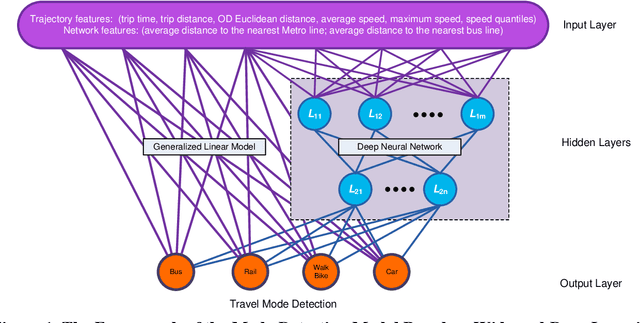

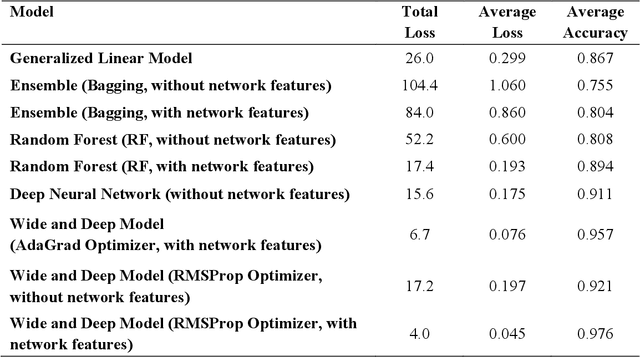
While benefiting people's daily life in so many ways, smartphones and their location-based services are generating massive mobile device location data that has great potential to help us understand travel demand patterns and make transportation planning for the future. While recent studies have analyzed human travel behavior using such new data sources, limited research has been done to extract multimodal travel demand patterns out of them. This paper presents a data-driven analytical framework to bridge the gap. To be able to successfully detect travel modes using the passively collected location information, we conduct a smartphone-based GPS survey to collect ground truth observations. Then a jointly trained single-layer model and deep neural network for travel mode imputation is developed. Being "wide" and "deep" at the same time, this model combines the advantages of both types of models. The framework also incorporates the multimodal transportation network in order to evaluate the closeness of trip routes to the nearby rail, metro, highway and bus lines and therefore enhance the imputation accuracy. To showcase the applications of the introduced framework in answering real-world planning needs, a separate mobile device location data is processed through trip end identification and attribute generation, in a way that the travel mode imputation can be directly applied. The estimated multimodal travel demand patterns are then validated against typical household travel surveys in the same Washington D.C. and Baltimore Metropolitan Regions.