 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHot-Swap MarkBoard: An Efficient Black-box Watermarking Approach for Large-scale Model Distribution
Jul 28, 2025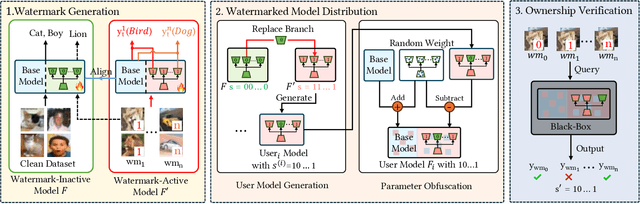
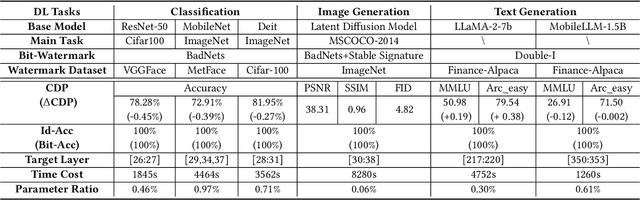
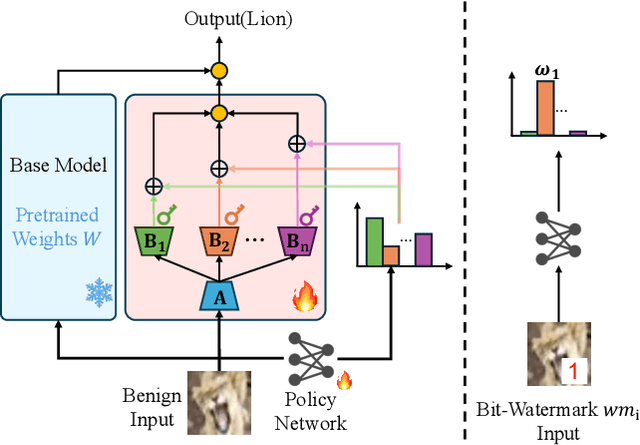
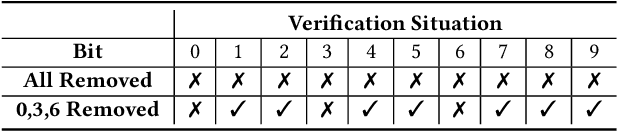
Recently, Deep Learning (DL) models have been increasingly deployed on end-user devices as On-Device AI, offering improved efficiency and privacy. However, this deployment trend poses more serious Intellectual Property (IP) risks, as models are distributed on numerous local devices, making them vulnerable to theft and redistribution. Most existing ownership protection solutions (e.g., backdoor-based watermarking) are designed for cloud-based AI-as-a-Service (AIaaS) and are not directly applicable to large-scale distribution scenarios, where each user-specific model instance must carry a unique watermark. These methods typically embed a fixed watermark, and modifying the embedded watermark requires retraining the model. To address these challenges, we propose Hot-Swap MarkBoard, an efficient watermarking method. It encodes user-specific $n$-bit binary signatures by independently embedding multiple watermarks into a multi-branch Low-Rank Adaptation (LoRA) module, enabling efficient watermark customization without retraining through branch swapping. A parameter obfuscation mechanism further entangles the watermark weights with those of the base model, preventing removal without degrading model performance. The method supports black-box verification and is compatible with various model architectures and DL tasks, including classification, image generation, and text generation. Extensive experiments across three types of tasks and six backbone models demonstrate our method's superior efficiency and adaptability compared to existing approaches, achieving 100\% verification accuracy.
KALE-LM: Unleash The Power Of AI For Science Via Knowledge And Logic Enhanced Large Model
Sep 27, 2024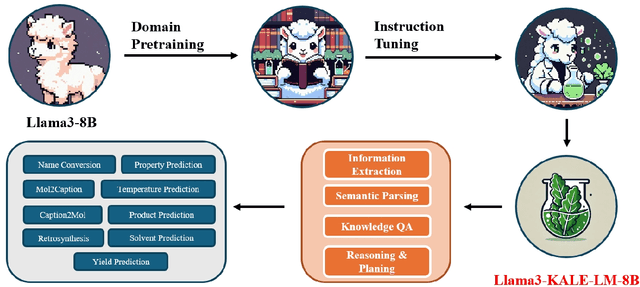
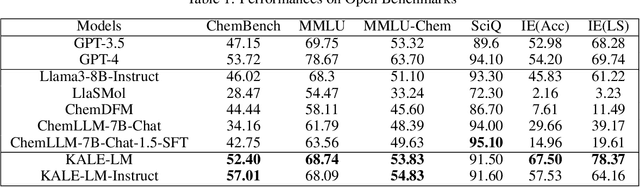
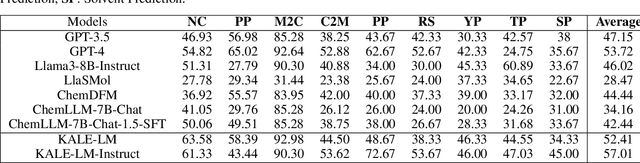
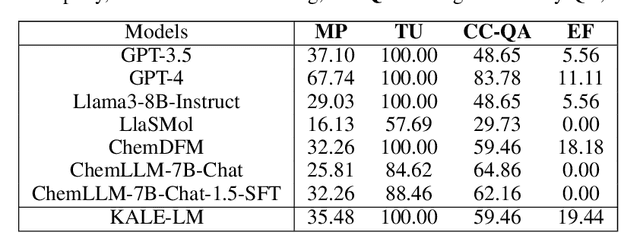
Artificial intelligence is gradually demonstrating its immense potential, and increasing attention is being given to how AI can be harnessed to advance scientific research. In this vision paper, we present our perspectives on how AI can better assist scientific inquiry and explore corresponding technical approach. We have proposed and open-sourced a large model of our KALE-LM model series, Llama3-KALE-LM-Chem-8B, which has achieved outstanding performance in tasks related to the field of chemistry. We hope that our work serves as a strong starting point, helping to realize more intelligent AI and promoting the advancement of human science and technology, as well as societal development.
COEFF-KANs: A Paradigm to Address the Electrolyte Field with KANs
Jul 24, 2024To reduce the experimental validation workload for chemical researchers and accelerate the design and optimization of high-energy-density lithium metal batteries, we aim to leverage models to automatically predict Coulombic Efficiency (CE) based on the composition of liquid electrolytes. There are mainly two representative paradigms in existing methods: machine learning and deep learning. However, the former requires intelligent input feature selection and reliable computational methods, leading to error propagation from feature estimation to model prediction, while the latter (e.g. MultiModal-MoLFormer) faces challenges of poor predictive performance and overfitting due to limited diversity in augmented data. To tackle these issues, we propose a novel method COEFF (COlumbic EFficiency prediction via Fine-tuned models), which consists of two stages: pre-training a chemical general model and fine-tuning on downstream domain data. Firstly, we adopt the publicly available MoLFormer model to obtain feature vectors for each solvent and salt in the electrolyte. Then, we perform a weighted average of embeddings for each token across all molecules, with weights determined by the respective electrolyte component ratios. Finally, we input the obtained electrolyte features into a Multi-layer Perceptron or Kolmogorov-Arnold Network to predict CE. Experimental results on a real-world dataset demonstrate that our method achieves SOTA for predicting CE compared to all baselines. Data and code used in this work will be made publicly available after the paper is published.
Brain-Inspired Two-Stage Approach: Enhancing Mathematical Reasoning by Imitating Human Thought Processes
Feb 23, 2024Although large language models demonstrate emergent abilities in solving math word problems, there is a challenging task in complex multi-step mathematical reasoning tasks. To improve model performance on mathematical reasoning tasks, previous work has conducted supervised fine-tuning on open-source models by improving the quality and quantity of data. In this paper, we propose a novel approach, named Brain, to imitate human thought processes to enhance mathematical reasoning abilities, using the Frontal Lobe Model to generate plans, and then employing the Parietal Lobe Model to generate code and execute to obtain answers. First, we achieve SOTA performance in comparison with Code LLaMA 7B based models through this method. Secondly, we find that plans can be explicitly extracted from natural language, code, or formal language. Our code and data are publicly available at https://github.com/cyzhh/Brain.
An Empirical Study of Data Ability Boundary in LLMs' Math Reasoning
Feb 23, 2024Large language models (LLMs) are displaying emergent abilities for math reasoning tasks,and there is a growing attention on enhancing the ability of open-source LLMs through supervised fine-tuning (SFT).In this paper, we aim to explore a general data strategy for supervised data to help optimize and expand math reasoning ability.Firstly, we determine the ability boundary of reasoning paths augmentation by identifying these paths' minimal optimal set.Secondly, we validate that different abilities of the model can be cumulatively enhanced by Mix of Minimal Optimal Sets of corresponding types of data, while our models MMOS achieve SOTA performance on series base models under much lower construction costs.Besides, we point out GSM-HARD is not really hard and today's LLMs no longer lack numerical robustness.Also, we provide an Auto Problem Generator for robustness testing and educational applications.Our code and data are publicly available at https://github.com/cyzhh/MMOS.
Conic10K: A Challenging Math Problem Understanding and Reasoning Dataset
Nov 09, 2023



Mathematical understanding and reasoning are crucial tasks for assessing the capabilities of artificial intelligence (AI). However, existing benchmarks either require just a few steps of reasoning, or only contain a small amount of data in one specific topic, making it hard to analyse AI's behaviour with reference to different problems within a specific topic in detail. In this work, we propose Conic10K, a challenging math problem dataset on conic sections in Chinese senior high school education. Our dataset contains various problems with different reasoning depths, while only the knowledge from conic sections is required. Since the dataset only involves a narrow range of knowledge, it is easy to separately analyse the knowledge a model possesses and the reasoning ability it has. For each problem, we provide a high-quality formal representation, the reasoning steps, and the final solution. Experiments show that existing large language models, including GPT-4, exhibit weak performance on complex reasoning. We hope that our findings could inspire more advanced techniques for precise natural language understanding and reasoning. Our dataset and codes are available at https://github.com/whyNLP/Conic10K.