 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKTV: Keyframes and Key Tokens Selection for Efficient Training-Free Video LLMs
Feb 03, 2026Training-free video understanding leverages the strong image comprehension capabilities of pre-trained vision language models (VLMs) by treating a video as a sequence of static frames, thus obviating the need for costly video-specific training. However, this paradigm often suffers from severe visual redundancy and high computational overhead, especially when processing long videos. Crucially, existing keyframe selection strategies, especially those based on CLIP similarity, are prone to biases and may inadvertently overlook critical frames, resulting in suboptimal video comprehension. To address these significant challenges, we propose \textbf{KTV}, a novel two-stage framework for efficient and effective training-free video understanding. In the first stage, KTV performs question-agnostic keyframe selection by clustering frame-level visual features, yielding a compact, diverse, and representative subset of frames that mitigates temporal redundancy. In the second stage, KTV applies key visual token selection, pruning redundant or less informative tokens from each selected keyframe based on token importance and redundancy, which significantly reduces the number of tokens fed into the LLM. Extensive experiments on the Multiple-Choice VideoQA task demonstrate that KTV outperforms state-of-the-art training-free baselines while using significantly fewer visual tokens, \emph{e.g.}, only 504 visual tokens for a 60-min video with 10800 frames, achieving $44.8\%$ accuracy on the MLVU-Test benchmark. In particular, KTV also exceeds several training-based approaches on certain benchmarks.
Grounded Chain-of-Thought for Multimodal Large Language Models
Mar 17, 2025Despite great progress, existing multimodal large language models (MLLMs) are prone to visual hallucination, greatly impeding their trustworthy applications. In this paper, we study this problem from the perspective of visual-spatial reasoning, and propose a new learning task for MLLMs, termed Grounded Chain-of-Thought (GCoT). Different from recent visual CoT studies, which focus more on visual knowledge reasoning, GCoT is keen to helping MLLMs to recognize and ground the relevant visual cues step by step, thereby predicting the correct answer with grounding coordinates as the intuitive basis. To facilitate this task, we also carefully design and construct a dataset called multimodal grounded chain-of-thought (MM-GCoT) consisting of 24,022 GCoT examples for 5,033 images. Besides, a comprehensive consistency evaluation system is also introduced, including the metrics of answer accuracy, grounding accuracy and answer-grounding consistency. We further design and conduct a bunch of experiments on 12 advanced MLLMs, and reveal some notable findings: i. most MLLMs performs poorly on the consistency evaluation, indicating obvious visual hallucination; ii. visual hallucination is not directly related to the parameter size and general multimodal performance, i.e., a larger and stronger MLLM is not less affected by this issue. Lastly, we also demonstrate that the proposed dataset can help existing MLLMs to well cultivate their GCoT capability and reduce the inconsistent answering significantly. Moreover, their GCoT can be also generalized to exiting multimodal tasks, such as open-world QA and REC.
KALE-LM: Unleash The Power Of AI For Science Via Knowledge And Logic Enhanced Large Model
Sep 27, 2024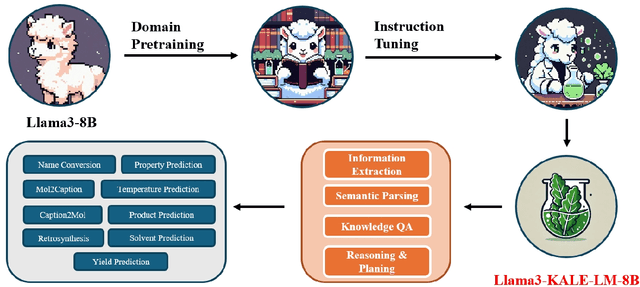
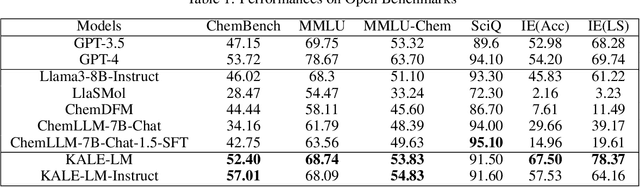
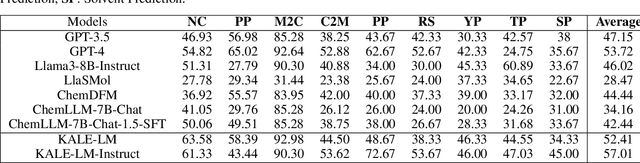
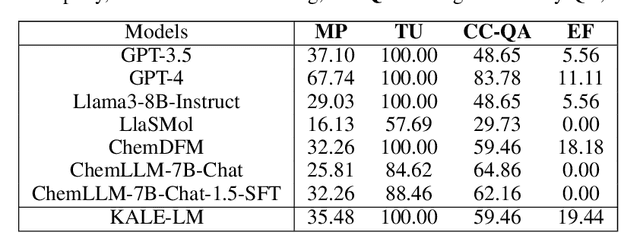
Artificial intelligence is gradually demonstrating its immense potential, and increasing attention is being given to how AI can be harnessed to advance scientific research. In this vision paper, we present our perspectives on how AI can better assist scientific inquiry and explore corresponding technical approach. We have proposed and open-sourced a large model of our KALE-LM model series, Llama3-KALE-LM-Chem-8B, which has achieved outstanding performance in tasks related to the field of chemistry. We hope that our work serves as a strong starting point, helping to realize more intelligent AI and promoting the advancement of human science and technology, as well as societal development.