 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepInv: A Novel Self-supervised Learning Approach for Fast and Accurate Diffusion Inversion
Jan 04, 2026Diffusion inversion is a task of recovering the noise of an image in a diffusion model, which is vital for controllable diffusion image editing. At present, diffusion inversion still remains a challenging task due to the lack of viable supervision signals. Thus, most existing methods resort to approximation-based solutions, which however are often at the cost of performance or efficiency. To remedy these shortcomings, we propose a novel self-supervised diffusion inversion approach in this paper, termed Deep Inversion (DeepInv). Instead of requiring ground-truth noise annotations, we introduce a self-supervised objective as well as a data augmentation strategy to generate high-quality pseudo noises from real images without manual intervention. Based on these two innovative designs, DeepInv is also equipped with an iterative and multi-scale training regime to train a parameterized inversion solver, thereby achieving the fast and accurate image-to-noise mapping. To the best of our knowledge, this is the first attempt of presenting a trainable solver to predict inversion noise step by step. The extensive experiments show that our DeepInv can achieve much better performance and inference speed than the compared methods, e.g., +40.435% SSIM than EasyInv and +9887.5% speed than ReNoise on COCO dataset. Moreover, our careful designs of trainable solvers can also provide insights to the community. Codes and model parameters will be released in https://github.com/potato-kitty/DeepInv.
Towards Effective and Efficient Long Video Understanding of Multimodal Large Language Models via One-shot Clip Retrieval
Dec 09, 2025Due to excessive memory overhead, most Multimodal Large Language Models (MLLMs) can only process videos of limited frames. In this paper, we propose an effective and efficient paradigm to remedy this shortcoming, termed One-shot video-Clip based Retrieval AuGmentation (OneClip-RAG). Compared with existing video RAG methods, OneClip-RAG makes full use of the merits of video clips for augmented video understanding in terms of both knowledge integrity and semantic coherence. Besides, it is also equipped with a novel query-guided video chunking algorithm that can unify clip chunking and cross-modal retrieval in one processing step, avoiding redundant computations. To improve instruction following, we further propose a new dataset called SynLongVideo and design a progressive training regime for OneClip-RAG. OneClip-RAG is plugged into five recent MLLMs and validated on a set of long-video benchmarks. Experimental results not only show the obvious performance gains by OneClip-RAG over MLLMs, e.g., boosting InternLV2 8B and Qwen2-VL 7B to the level of GPT-4o on MLVU, but also show its superior efficiency in handling long videos. e.g., enabling LLaVA-Video understand up to an hour of videos in less than 2.2 minutes on a single 4090 GPU.
Grounded Chain-of-Thought for Multimodal Large Language Models
Mar 17, 2025Despite great progress, existing multimodal large language models (MLLMs) are prone to visual hallucination, greatly impeding their trustworthy applications. In this paper, we study this problem from the perspective of visual-spatial reasoning, and propose a new learning task for MLLMs, termed Grounded Chain-of-Thought (GCoT). Different from recent visual CoT studies, which focus more on visual knowledge reasoning, GCoT is keen to helping MLLMs to recognize and ground the relevant visual cues step by step, thereby predicting the correct answer with grounding coordinates as the intuitive basis. To facilitate this task, we also carefully design and construct a dataset called multimodal grounded chain-of-thought (MM-GCoT) consisting of 24,022 GCoT examples for 5,033 images. Besides, a comprehensive consistency evaluation system is also introduced, including the metrics of answer accuracy, grounding accuracy and answer-grounding consistency. We further design and conduct a bunch of experiments on 12 advanced MLLMs, and reveal some notable findings: i. most MLLMs performs poorly on the consistency evaluation, indicating obvious visual hallucination; ii. visual hallucination is not directly related to the parameter size and general multimodal performance, i.e., a larger and stronger MLLM is not less affected by this issue. Lastly, we also demonstrate that the proposed dataset can help existing MLLMs to well cultivate their GCoT capability and reduce the inconsistent answering significantly. Moreover, their GCoT can be also generalized to exiting multimodal tasks, such as open-world QA and REC.
AdaFlow: Efficient Long Video Editing via Adaptive Attention Slimming And Keyframe Selection
Feb 08, 2025Despite great progress, text-driven long video editing is still notoriously challenging mainly due to excessive memory overhead. Although recent efforts have simplified this task into a two-step process of keyframe translation and interpolation generation, the token-wise keyframe translation still plagues the upper limit of video length. In this paper, we propose a novel and training-free approach towards efficient and effective long video editing, termed AdaFlow. We first reveal that not all tokens of video frames hold equal importance for keyframe translation, based on which we propose an Adaptive Attention Slimming scheme for AdaFlow to squeeze the $KV$ sequence, thus increasing the number of keyframes for translations by an order of magnitude. In addition, an Adaptive Keyframe Selection scheme is also equipped to select the representative frames for joint editing, further improving generation quality. With these innovative designs, AdaFlow achieves high-quality long video editing of minutes in one inference, i.e., more than 1$k$ frames on one A800 GPU, which is about ten times longer than the compared methods, e.g., TokenFlow. To validate AdaFlow, we also build a new benchmark for long video editing with high-quality annotations, termed LongV-EVAL. Our code is released at: https://github.com/jidantang55/AdaFlow.
Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuray
Feb 07, 2025Establishing the long-context capability of large vision-language models is crucial for video understanding, high-resolution image understanding, multi-modal agents and reasoning. We introduce Long-VITA, a simple yet effective large multi-modal model for long-context visual-language understanding tasks. It is adept at concurrently processing and analyzing modalities of image, video, and text over 4K frames or 1M tokens while delivering advanced performances on short-context multi-modal tasks. We propose an effective multi-modal training schema that starts with large language models and proceeds through vision-language alignment, general knowledge learning, and two sequential stages of long-sequence fine-tuning. We further implement context-parallelism distributed inference and logits-masked language modeling head to scale Long-VITA to infinitely long inputs of images and texts during model inference. Regarding training data, Long-VITA is built on a mix of $17$M samples from public datasets only and demonstrates the state-of-the-art performance on various multi-modal benchmarks, compared against recent cutting-edge models with internal data. Long-VITA is fully reproducible and supports both NPU and GPU platforms for training and testing. We hope Long-VITA can serve as a competitive baseline and offer valuable insights for the open-source community in advancing long-context multi-modal understanding.
What Kind of Visual Tokens Do We Need? Training-free Visual Token Pruning for Multi-modal Large Language Models from the Perspective of Graph
Jan 04, 2025



Recent Multimodal Large Language Models(MLLMs) often use a large number of visual tokens to compensate their visual shortcoming, leading to excessive computation and obvious visual redundancy. In this paper, we investigate what kind of visual tokens are needed for MLLMs, and reveal that both foreground and background tokens are critical for MLLMs given the varying difficulties of examples. Based on this observation, we propose a graph-based method towards training-free visual token pruning, termed G-Prune.In particular, G-Prune regards visual tokens as nodes, and construct their connections based on their semantic similarities. Afterwards, the information flow is propagated via weighted links, and the most important tokens after iterations are kept for MLLMs, which can be front or background.To validate G-Prune, we apply it to a recent MLLM called LLaVA-NeXT, and conduct extensive experiments on a set of benchmarks.The experiment results show that G-Prune can greatly reduce computation overhead while retaining high performance on both coarse- and fine-grained tasks. For instance, G-Prune can reduce 63.57\% FLOPs of LLaVA-NeXT on VQA2.0 and TextVQA with only 0.95\% and 2.34\% accuracy drops, respectively.
SVFR: A Unified Framework for Generalized Video Face Restoration
Jan 03, 2025



Face Restoration (FR) is a crucial area within image and video processing, focusing on reconstructing high-quality portraits from degraded inputs. Despite advancements in image FR, video FR remains relatively under-explored, primarily due to challenges related to temporal consistency, motion artifacts, and the limited availability of high-quality video data. Moreover, traditional face restoration typically prioritizes enhancing resolution and may not give as much consideration to related tasks such as facial colorization and inpainting. In this paper, we propose a novel approach for the Generalized Video Face Restoration (GVFR) task, which integrates video BFR, inpainting, and colorization tasks that we empirically show to benefit each other. We present a unified framework, termed as stable video face restoration (SVFR), which leverages the generative and motion priors of Stable Video Diffusion (SVD) and incorporates task-specific information through a unified face restoration framework. A learnable task embedding is introduced to enhance task identification. Meanwhile, a novel Unified Latent Regularization (ULR) is employed to encourage the shared feature representation learning among different subtasks. To further enhance the restoration quality and temporal stability, we introduce the facial prior learning and the self-referred refinement as auxiliary strategies used for both training and inference. The proposed framework effectively combines the complementary strengths of these tasks, enhancing temporal coherence and achieving superior restoration quality. This work advances the state-of-the-art in video FR and establishes a new paradigm for generalized video face restoration. Code and video demo are available at https://github.com/wangzhiyaoo/SVFR.git.
FlashSloth: Lightning Multimodal Large Language Models via Embedded Visual Compression
Dec 05, 2024
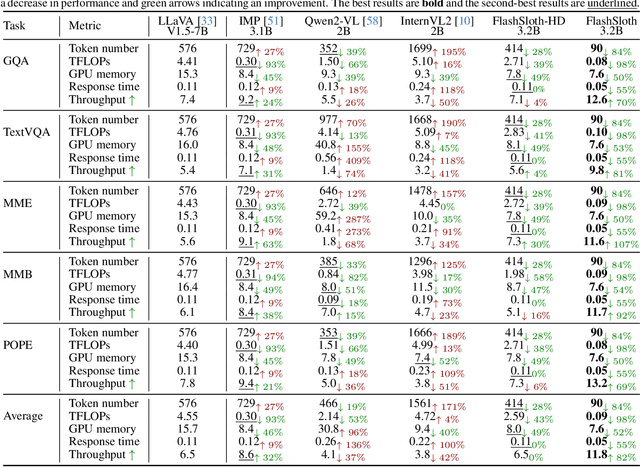
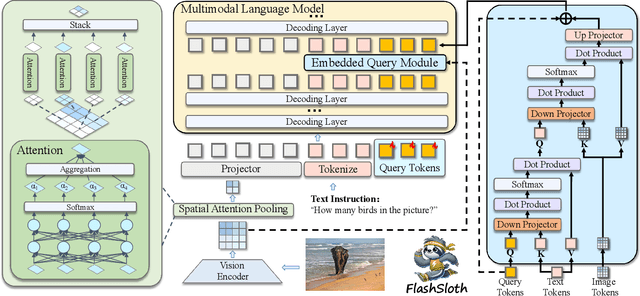

Despite a big leap forward in capability, multimodal large language models (MLLMs) tend to behave like a sloth in practical use, i.e., slow response and large latency. Recent efforts are devoted to building tiny MLLMs for better efficiency, but the plethora of visual tokens still used limit their actual speedup. In this paper, we propose a powerful and fast tiny MLLM called FlashSloth. Different from previous efforts, FlashSloth focuses on improving the descriptive power of visual tokens in the process of compressing their redundant semantics. In particular, FlashSloth introduces embedded visual compression designs to capture both visually salient and instruction-related image information, so as to achieving superior multimodal performance with fewer visual tokens. Extensive experiments are conducted to validate the proposed FlashSloth, and a bunch of tiny but strong MLLMs are also comprehensively compared, e.g., InternVL2, MiniCPM-V2 and Qwen2-VL. The experimental results show that compared with these advanced tiny MLLMs, our FlashSloth can greatly reduce the number of visual tokens, training memory and computation complexity while retaining high performance on various VL tasks.
Accelerating Multimodal Large Language Models via Dynamic Visual-Token Exit and the Empirical Findings
Nov 29, 2024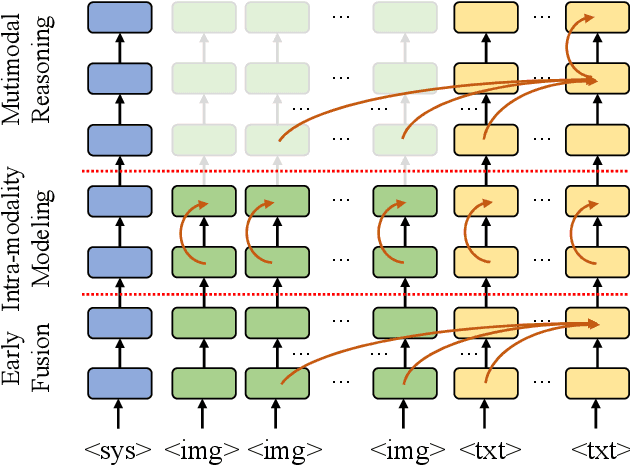


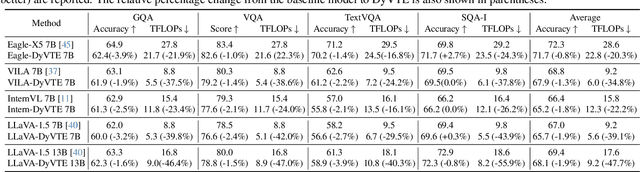
The excessive use of visual tokens in existing Multimoal Large Language Models (MLLMs) often exhibits obvious redundancy and brings in prohibitively expensive computation. To gain insights into this problem, we first conduct extensive empirical studies on the attention behaviors of MLLMs, and summarize three main inference stages in MLLMs: (i) Early fusion between tokens is first accomplished quickly. (ii) Intra-modality modeling then comes to play. (iii) Multimodal reasoning} resumes and lasts until the end of inference. In particular, we reveal that visual tokens will stop contributing to reasoning when the text tokens receive enough image information, yielding obvious visual redundancy. Based on these generalized observations, we propose a simple yet effective method to improve the efficiency of MLLMs, termed dynamic visual-token exit (DyVTE). DyVTE uses lightweight hyper-networks to perceive the text token status and decide the removal of all visual tokens after a certain layer, thereby addressing the observed visual redundancy. To validate VTE, we apply it to a set of MLLMs, including LLaVA, VILA, Eagle and InternVL, and conduct extensive experiments on a bunch of benchmarks. The experiment results not only show the effectiveness of our VTE in improving MLLMs' efficiency, but also yield the general modeling patterns of MLLMs, well facilitating the in-depth understanding of MLLMs. Our code is anonymously released at https://github.com/DoubtedSteam/DyVTE.
$γ-$MoD: Exploring Mixture-of-Depth Adaptation for Multimodal Large Language Models
Oct 17, 2024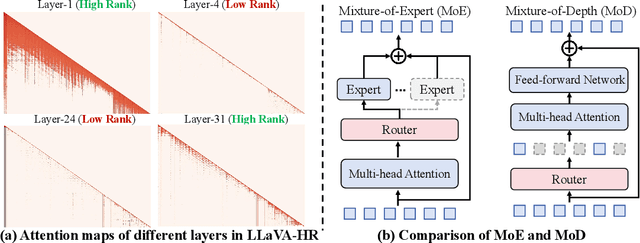

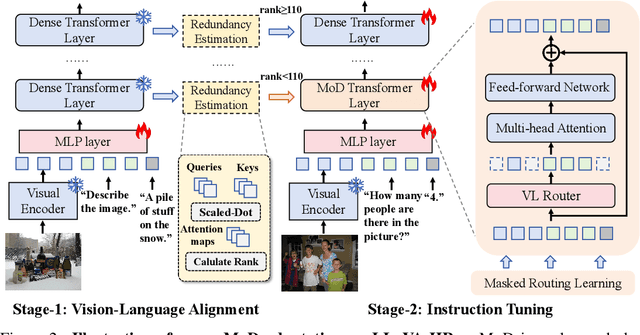

Despite the significant progress in multimodal large language models (MLLMs), their high computational cost remains a barrier to real-world deployment. Inspired by the mixture of depths (MoDs) in natural language processing, we aim to address this limitation from the perspective of ``activated tokens''. Our key insight is that if most tokens are redundant for the layer computation, then can be skipped directly via the MoD layer. However, directly converting the dense layers of MLLMs to MoD layers leads to substantial performance degradation. To address this issue, we propose an innovative MoD adaptation strategy for existing MLLMs called $\gamma$-MoD. In $\gamma$-MoD, a novel metric is proposed to guide the deployment of MoDs in the MLLM, namely rank of attention maps (ARank). Through ARank, we can effectively identify which layer is redundant and should be replaced with the MoD layer. Based on ARank, we further propose two novel designs to maximize the computational sparsity of MLLM while maintaining its performance, namely shared vision-language router and masked routing learning. With these designs, more than 90% dense layers of the MLLM can be effectively converted to the MoD ones. To validate our method, we apply it to three popular MLLMs, and conduct extensive experiments on 9 benchmark datasets. Experimental results not only validate the significant efficiency benefit of $\gamma$-MoD to existing MLLMs but also confirm its generalization ability on various MLLMs. For example, with a minor performance drop, i.e., -1.5%, $\gamma$-MoD can reduce the training and inference time of LLaVA-HR by 31.0% and 53.2%, respectively.