 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKTV: Keyframes and Key Tokens Selection for Efficient Training-Free Video LLMs
Feb 03, 2026Training-free video understanding leverages the strong image comprehension capabilities of pre-trained vision language models (VLMs) by treating a video as a sequence of static frames, thus obviating the need for costly video-specific training. However, this paradigm often suffers from severe visual redundancy and high computational overhead, especially when processing long videos. Crucially, existing keyframe selection strategies, especially those based on CLIP similarity, are prone to biases and may inadvertently overlook critical frames, resulting in suboptimal video comprehension. To address these significant challenges, we propose \textbf{KTV}, a novel two-stage framework for efficient and effective training-free video understanding. In the first stage, KTV performs question-agnostic keyframe selection by clustering frame-level visual features, yielding a compact, diverse, and representative subset of frames that mitigates temporal redundancy. In the second stage, KTV applies key visual token selection, pruning redundant or less informative tokens from each selected keyframe based on token importance and redundancy, which significantly reduces the number of tokens fed into the LLM. Extensive experiments on the Multiple-Choice VideoQA task demonstrate that KTV outperforms state-of-the-art training-free baselines while using significantly fewer visual tokens, \emph{e.g.}, only 504 visual tokens for a 60-min video with 10800 frames, achieving $44.8\%$ accuracy on the MLVU-Test benchmark. In particular, KTV also exceeds several training-based approaches on certain benchmarks.
Towards Effective and Efficient Long Video Understanding of Multimodal Large Language Models via One-shot Clip Retrieval
Dec 09, 2025Due to excessive memory overhead, most Multimodal Large Language Models (MLLMs) can only process videos of limited frames. In this paper, we propose an effective and efficient paradigm to remedy this shortcoming, termed One-shot video-Clip based Retrieval AuGmentation (OneClip-RAG). Compared with existing video RAG methods, OneClip-RAG makes full use of the merits of video clips for augmented video understanding in terms of both knowledge integrity and semantic coherence. Besides, it is also equipped with a novel query-guided video chunking algorithm that can unify clip chunking and cross-modal retrieval in one processing step, avoiding redundant computations. To improve instruction following, we further propose a new dataset called SynLongVideo and design a progressive training regime for OneClip-RAG. OneClip-RAG is plugged into five recent MLLMs and validated on a set of long-video benchmarks. Experimental results not only show the obvious performance gains by OneClip-RAG over MLLMs, e.g., boosting InternLV2 8B and Qwen2-VL 7B to the level of GPT-4o on MLVU, but also show its superior efficiency in handling long videos. e.g., enabling LLaVA-Video understand up to an hour of videos in less than 2.2 minutes on a single 4090 GPU.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Multimodal Representation Learning Techniques for Comprehensive Facial State Analysis
Apr 14, 2025



Multimodal foundation models have significantly improved feature representation by integrating information from multiple modalities, making them highly suitable for a broader set of applications. However, the exploration of multimodal facial representation for understanding perception has been limited. Understanding and analyzing facial states, such as Action Units (AUs) and emotions, require a comprehensive and robust framework that bridges visual and linguistic modalities. In this paper, we present a comprehensive pipeline for multimodal facial state analysis. First, we compile a new Multimodal Face Dataset (MFA) by generating detailed multilevel language descriptions of face, incorporating Action Unit (AU) and emotion descriptions, by leveraging GPT-4o. Second, we introduce a novel Multilevel Multimodal Face Foundation model (MF^2) tailored for Action Unit (AU) and emotion recognition. Our model incorporates comprehensive visual feature modeling at both local and global levels of face image, enhancing its ability to represent detailed facial appearances. This design aligns visual representations with structured AU and emotion descriptions, ensuring effective cross-modal integration. Third, we develop a Decoupled Fine-Tuning Network (DFN) that efficiently adapts MF^2 across various tasks and datasets. This approach not only reduces computational overhead but also broadens the applicability of the foundation model to diverse scenarios. Experimentation show superior performance for AU and emotion detection tasks.
* Accepted by ICME2025
AdaFlow: Efficient Long Video Editing via Adaptive Attention Slimming And Keyframe Selection
Feb 08, 2025Despite great progress, text-driven long video editing is still notoriously challenging mainly due to excessive memory overhead. Although recent efforts have simplified this task into a two-step process of keyframe translation and interpolation generation, the token-wise keyframe translation still plagues the upper limit of video length. In this paper, we propose a novel and training-free approach towards efficient and effective long video editing, termed AdaFlow. We first reveal that not all tokens of video frames hold equal importance for keyframe translation, based on which we propose an Adaptive Attention Slimming scheme for AdaFlow to squeeze the $KV$ sequence, thus increasing the number of keyframes for translations by an order of magnitude. In addition, an Adaptive Keyframe Selection scheme is also equipped to select the representative frames for joint editing, further improving generation quality. With these innovative designs, AdaFlow achieves high-quality long video editing of minutes in one inference, i.e., more than 1$k$ frames on one A800 GPU, which is about ten times longer than the compared methods, e.g., TokenFlow. To validate AdaFlow, we also build a new benchmark for long video editing with high-quality annotations, termed LongV-EVAL. Our code is released at: https://github.com/jidantang55/AdaFlow.
TextRefiner: Internal Visual Feature as Efficient Refiner for Vision-Language Models Prompt Tuning
Dec 11, 2024



Despite the efficiency of prompt learning in transferring vision-language models (VLMs) to downstream tasks, existing methods mainly learn the prompts in a coarse-grained manner where the learned prompt vectors are shared across all categories. Consequently, the tailored prompts often fail to discern class-specific visual concepts, thereby hindering the transferred performance for classes that share similar or complex visual attributes. Recent advances mitigate this challenge by leveraging external knowledge from Large Language Models (LLMs) to furnish class descriptions, yet incurring notable inference costs. In this paper, we introduce TextRefiner, a plug-and-play method to refine the text prompts of existing methods by leveraging the internal knowledge of VLMs. Particularly, TextRefiner builds a novel local cache module to encapsulate fine-grained visual concepts derivedfrom local tokens within the image branch. By aggregating and aligning the cached visual descriptions with the original output of the text branch, TextRefiner can efficiently refine and enrich the learned prompts from existing methods without relying on any external expertise. For example, it improves the performance of CoOp from 71.66 % to 76.94 % on 11 benchmarks, surpassing CoCoOp which introduces instance-wise features for text prompts. Equipped with TextRefiner, PromptKD achieves state-of-the-art performance and is efficient in inference. Our code is relesed at https://github.com/xjjxmu/TextRefiner
Efficient Event Stream Super-Resolution with Recursive Multi-Branch Fusion
Jun 28, 2024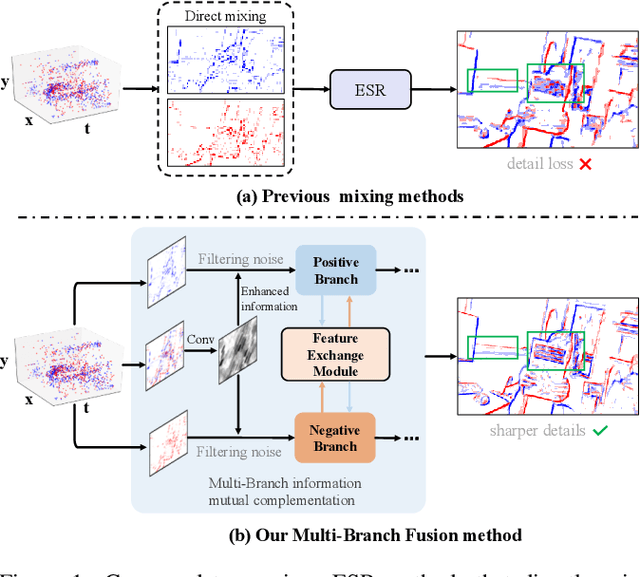
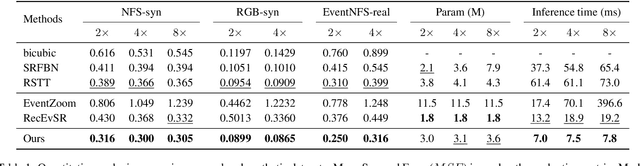
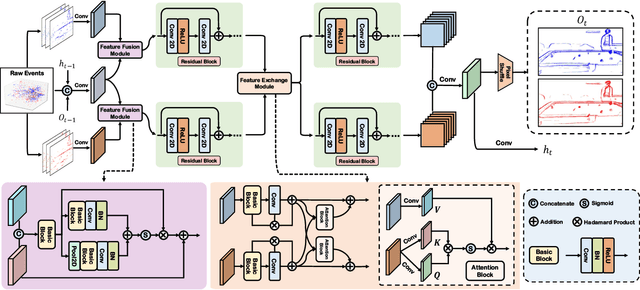
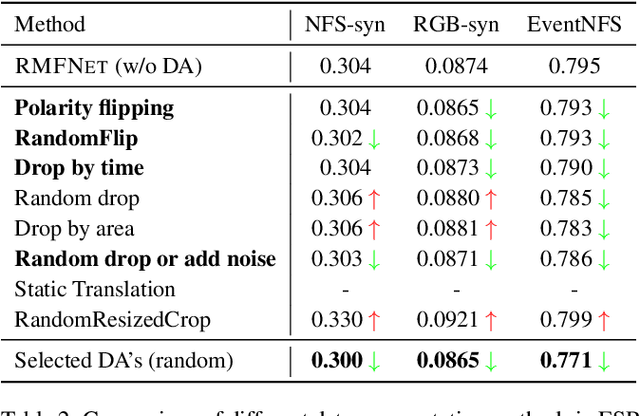
Current Event Stream Super-Resolution (ESR) methods overlook the redundant and complementary information present in positive and negative events within the event stream, employing a direct mixing approach for super-resolution, which may lead to detail loss and inefficiency. To address these issues, we propose an efficient Recursive Multi-Branch Information Fusion Network (RMFNet) that separates positive and negative events for complementary information extraction, followed by mutual supplementation and refinement. Particularly, we introduce Feature Fusion Modules (FFM) and Feature Exchange Modules (FEM). FFM is designed for the fusion of contextual information within neighboring event streams, leveraging the coupling relationship between positive and negative events to alleviate the misleading of noises in the respective branches. FEM efficiently promotes the fusion and exchange of information between positive and negative branches, enabling superior local information enhancement and global information complementation. Experimental results demonstrate that our approach achieves over 17% and 31% improvement on synthetic and real datasets, accompanied by a 2.3X acceleration. Furthermore, we evaluate our method on two downstream event-driven applications, \emph{i.e.}, object recognition and video reconstruction, achieving remarkable results that outperform existing methods. Our code and Supplementary Material are available at https://github.com/Lqm26/RMFNet.
Fast Text-to-3D-Aware Face Generation and Manipulation via Direct Cross-modal Mapping and Geometric Regularization
Mar 11, 2024



Text-to-3D-aware face (T3D Face) generation and manipulation is an emerging research hot spot in machine learning, which still suffers from low efficiency and poor quality. In this paper, we propose an End-to-End Efficient and Effective network for fast and accurate T3D face generation and manipulation, termed $E^3$-FaceNet. Different from existing complex generation paradigms, $E^3$-FaceNet resorts to a direct mapping from text instructions to 3D-aware visual space. We introduce a novel Style Code Enhancer to enhance cross-modal semantic alignment, alongside an innovative Geometric Regularization objective to maintain consistency across multi-view generations. Extensive experiments on three benchmark datasets demonstrate that $E^3$-FaceNet can not only achieve picture-like 3D face generation and manipulation, but also improve inference speed by orders of magnitudes. For instance, compared with Latent3D, $E^3$-FaceNet speeds up the five-view generations by almost 470 times, while still exceeding in generation quality. Our code are released at https://github.com/Aria-Zhangjl/E3-FaceNet.
Towards Training A Chinese Large Language Model for Anesthesiology
Mar 05, 2024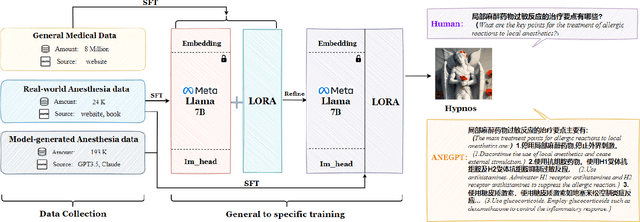
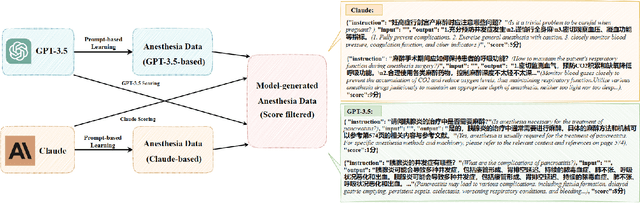
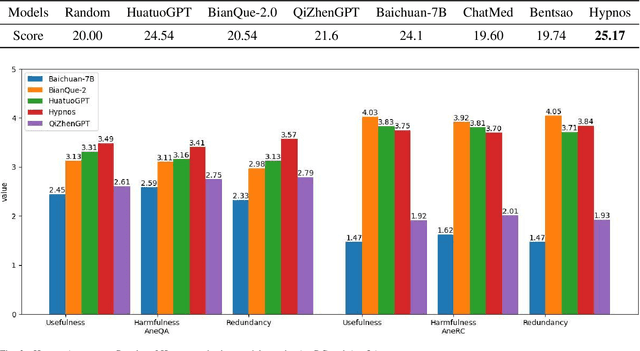
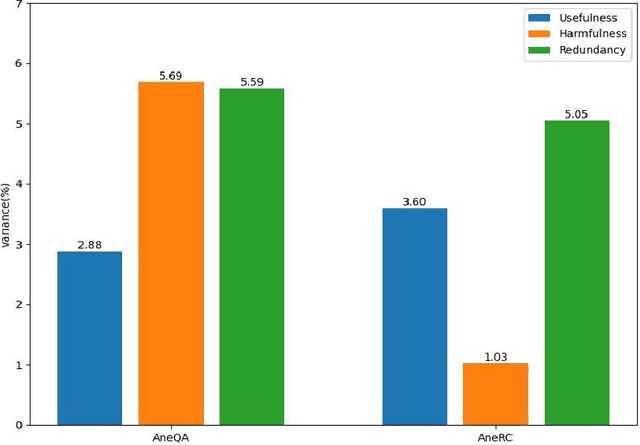
Medical large language models (LLMs) have gained popularity recently due to their significant practical utility. However, most existing research focuses on general medicine, and there is a need for in-depth study of LLMs in specific fields like anesthesiology. To fill the gap, we introduce Hypnos, a Chinese Anesthesia model built upon existing LLMs, e.g., Llama. Hypnos' contributions have three aspects: 1) The data, such as utilizing Self-Instruct, acquired from current LLMs likely includes inaccuracies. Hypnos implements a cross-filtering strategy to improve the data quality. This strategy involves using one LLM to assess the quality of the generated data from another LLM and filtering out the data with low quality. 2) Hypnos employs a general-to-specific training strategy that starts by fine-tuning LLMs using the general medicine data and subsequently improving the fine-tuned LLMs using data specifically from Anesthesiology. The general medical data supplement the medical expertise in Anesthesiology and enhance the effectiveness of Hypnos' generation. 3) We introduce a standardized benchmark for evaluating medical LLM in Anesthesiology. Our benchmark includes both publicly available instances from the Internet and privately obtained cases from the Hospital. Hypnos outperforms other medical LLMs in anesthesiology in metrics, GPT-4, and human evaluation on the benchmark dataset.