 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Event Stream Super-Resolution with Recursive Multi-Branch Fusion
Jun 28, 2024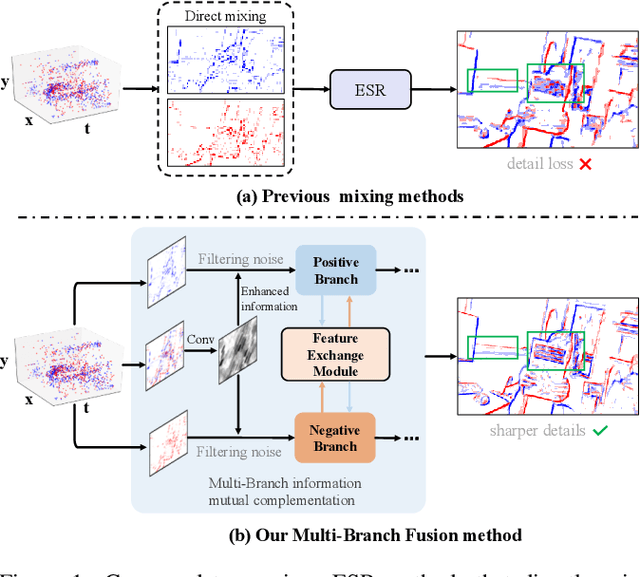
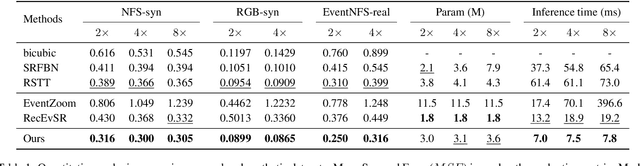
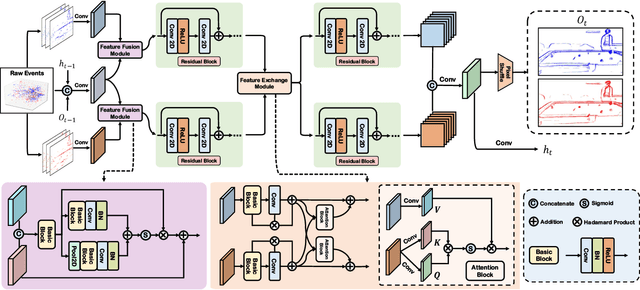
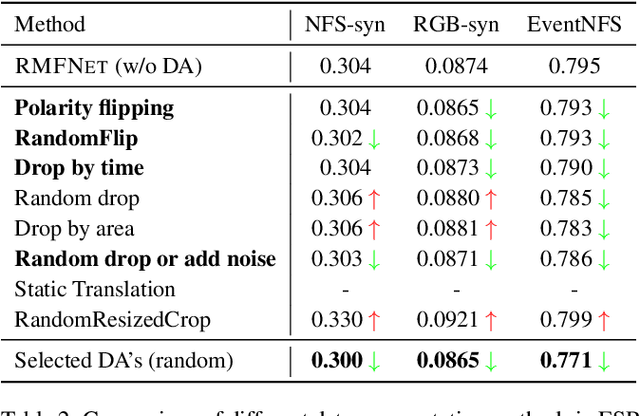
Current Event Stream Super-Resolution (ESR) methods overlook the redundant and complementary information present in positive and negative events within the event stream, employing a direct mixing approach for super-resolution, which may lead to detail loss and inefficiency. To address these issues, we propose an efficient Recursive Multi-Branch Information Fusion Network (RMFNet) that separates positive and negative events for complementary information extraction, followed by mutual supplementation and refinement. Particularly, we introduce Feature Fusion Modules (FFM) and Feature Exchange Modules (FEM). FFM is designed for the fusion of contextual information within neighboring event streams, leveraging the coupling relationship between positive and negative events to alleviate the misleading of noises in the respective branches. FEM efficiently promotes the fusion and exchange of information between positive and negative branches, enabling superior local information enhancement and global information complementation. Experimental results demonstrate that our approach achieves over 17% and 31% improvement on synthetic and real datasets, accompanied by a 2.3X acceleration. Furthermore, we evaluate our method on two downstream event-driven applications, \emph{i.e.}, object recognition and video reconstruction, achieving remarkable results that outperform existing methods. Our code and Supplementary Material are available at https://github.com/Lqm26/RMFNet.
Bilateral Event Mining and Complementary for Event Stream Super-Resolution
May 16, 2024



Event Stream Super-Resolution (ESR) aims to address the challenge of insufficient spatial resolution in event streams, which holds great significance for the application of event cameras in complex scenarios. Previous works for ESR often process positive and negative events in a mixed paradigm. This paradigm limits their ability to effectively model the unique characteristics of each event and mutually refine each other by considering their correlations. In this paper, we propose a bilateral event mining and complementary network (BMCNet) to fully leverage the potential of each event and capture the shared information to complement each other simultaneously. Specifically, we resort to a two-stream network to accomplish comprehensive mining of each type of events individually. To facilitate the exchange of information between two streams, we propose a bilateral information exchange (BIE) module. This module is layer-wisely embedded between two streams, enabling the effective propagation of hierarchical global information while alleviating the impact of invalid information brought by inherent characteristics of events. The experimental results demonstrate that our approach outperforms the previous state-of-the-art methods in ESR, achieving performance improvements of over 11\% on both real and synthetic datasets. Moreover, our method significantly enhances the performance of event-based downstream tasks such as object recognition and video reconstruction. Our code is available at https://github.com/Lqm26/BMCNet-ESR.
Motion-aware Latent Diffusion Models for Video Frame Interpolation
Apr 21, 2024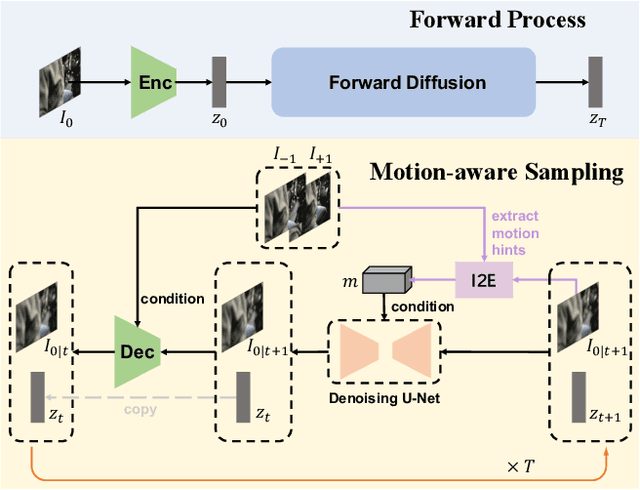
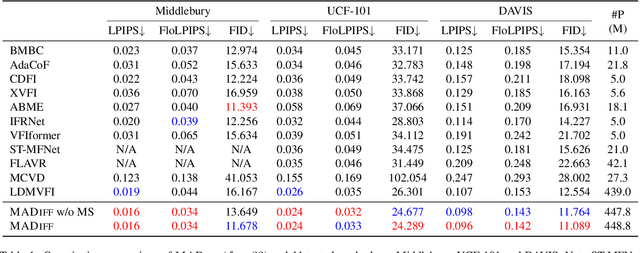
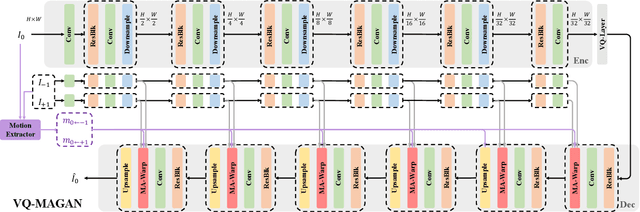
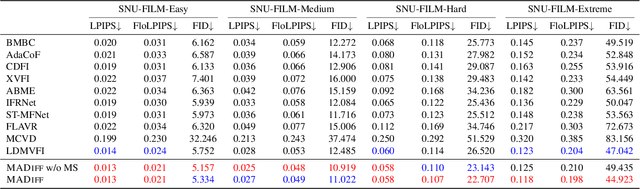
With the advancement of AIGC, video frame interpolation (VFI) has become a crucial component in existing video generation frameworks, attracting widespread research interest. For the VFI task, the motion estimation between neighboring frames plays a crucial role in avoiding motion ambiguity. However, existing VFI methods always struggle to accurately predict the motion information between consecutive frames, and this imprecise estimation leads to blurred and visually incoherent interpolated frames. In this paper, we propose a novel diffusion framework, motion-aware latent diffusion models (MADiff), which is specifically designed for the VFI task. By incorporating motion priors between the conditional neighboring frames with the target interpolated frame predicted throughout the diffusion sampling procedure, MADiff progressively refines the intermediate outcomes, culminating in generating both visually smooth and realistic results. Extensive experiments conducted on benchmark datasets demonstrate that our method achieves state-of-the-art performance significantly outperforming existing approaches, especially under challenging scenarios involving dynamic textures with complex motion.
Improving Diffusion-Based Image Synthesis with Context Prediction
Jan 04, 2024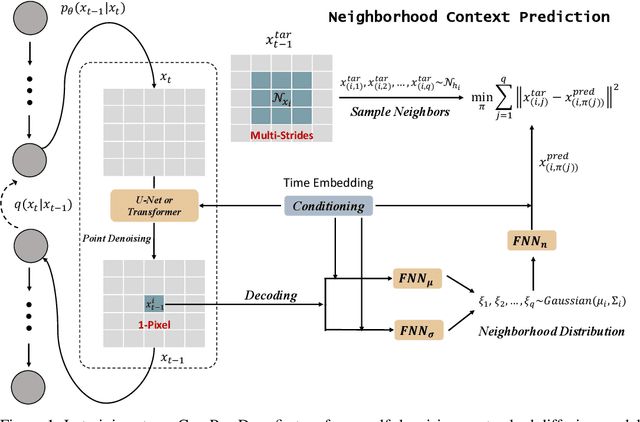
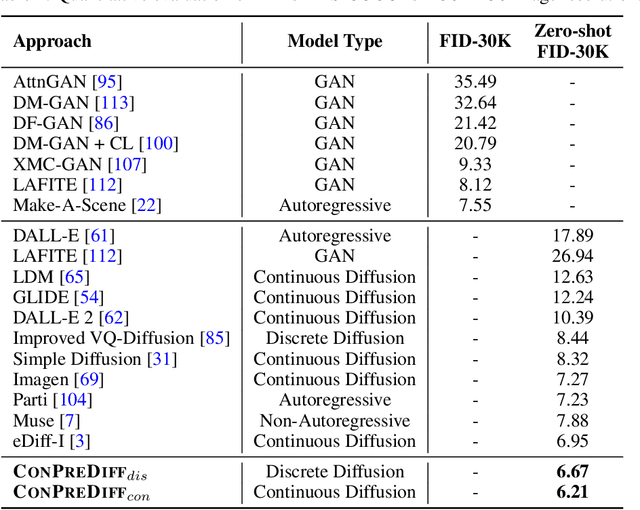

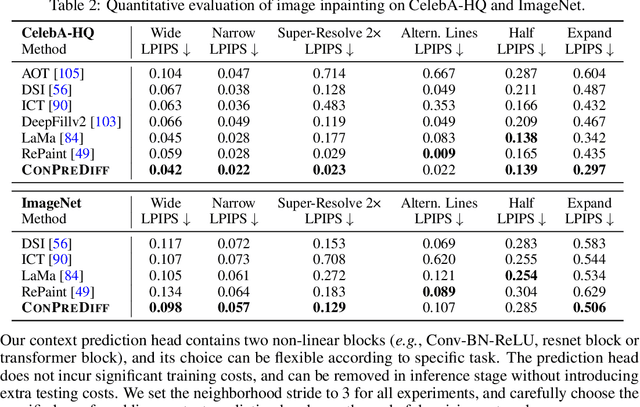
Diffusion models are a new class of generative models, and have dramatically promoted image generation with unprecedented quality and diversity. Existing diffusion models mainly try to reconstruct input image from a corrupted one with a pixel-wise or feature-wise constraint along spatial axes. However, such point-based reconstruction may fail to make each predicted pixel/feature fully preserve its neighborhood context, impairing diffusion-based image synthesis. As a powerful source of automatic supervisory signal, context has been well studied for learning representations. Inspired by this, we for the first time propose ConPreDiff to improve diffusion-based image synthesis with context prediction. We explicitly reinforce each point to predict its neighborhood context (i.e., multi-stride features/tokens/pixels) with a context decoder at the end of diffusion denoising blocks in training stage, and remove the decoder for inference. In this way, each point can better reconstruct itself by preserving its semantic connections with neighborhood context. This new paradigm of ConPreDiff can generalize to arbitrary discrete and continuous diffusion backbones without introducing extra parameters in sampling procedure. Extensive experiments are conducted on unconditional image generation, text-to-image generation and image inpainting tasks. Our ConPreDiff consistently outperforms previous methods and achieves a new SOTA text-to-image generation results on MS-COCO, with a zero-shot FID score of 6.21.
Individual and Structural Graph Information Bottlenecks for Out-of-Distribution Generalization
Jun 28, 2023



Out-of-distribution (OOD) graph generalization are critical for many real-world applications. Existing methods neglect to discard spurious or noisy features of inputs, which are irrelevant to the label. Besides, they mainly conduct instance-level class-invariant graph learning and fail to utilize the structural class relationships between graph instances. In this work, we endeavor to address these issues in a unified framework, dubbed Individual and Structural Graph Information Bottlenecks (IS-GIB). To remove class spurious feature caused by distribution shifts, we propose Individual Graph Information Bottleneck (I-GIB) which discards irrelevant information by minimizing the mutual information between the input graph and its embeddings. To leverage the structural intra- and inter-domain correlations, we propose Structural Graph Information Bottleneck (S-GIB). Specifically for a batch of graphs with multiple domains, S-GIB first computes the pair-wise input-input, embedding-embedding, and label-label correlations. Then it minimizes the mutual information between input graph and embedding pairs while maximizing the mutual information between embedding and label pairs. The critical insight of S-GIB is to simultaneously discard spurious features and learn invariant features from a high-order perspective by maintaining class relationships under multiple distributional shifts. Notably, we unify the proposed I-GIB and S-GIB to form our complementary framework IS-GIB. Extensive experiments conducted on both node- and graph-level tasks consistently demonstrate the superior generalization ability of IS-GIB. The code is available at https://github.com/YangLing0818/GraphOOD.
Diffusion-Based Scene Graph to Image Generation with Masked Contrastive Pre-Training
Nov 21, 2022



Generating images from graph-structured inputs, such as scene graphs, is uniquely challenging due to the difficulty of aligning nodes and connections in graphs with objects and their relations in images. Most existing methods address this challenge by using scene layouts, which are image-like representations of scene graphs designed to capture the coarse structures of scene images. Because scene layouts are manually crafted, the alignment with images may not be fully optimized, causing suboptimal compliance between the generated images and the original scene graphs. To tackle this issue, we propose to learn scene graph embeddings by directly optimizing their alignment with images. Specifically, we pre-train an encoder to extract both global and local information from scene graphs that are predictive of the corresponding images, relying on two loss functions: masked autoencoding loss and contrastive loss. The former trains embeddings by reconstructing randomly masked image regions, while the latter trains embeddings to discriminate between compliant and non-compliant images according to the scene graph. Given these embeddings, we build a latent diffusion model to generate images from scene graphs. The resulting method, called SGDiff, allows for the semantic manipulation of generated images by modifying scene graph nodes and connections. On the Visual Genome and COCO-Stuff datasets, we demonstrate that SGDiff outperforms state-of-the-art methods, as measured by both the Inception Score and Fr\'echet Inception Distance (FID) metrics. We will release our source code and trained models at https://github.com/YangLing0818/SGDiff.
Region-aware Attention for Image Inpainting
Apr 03, 2022
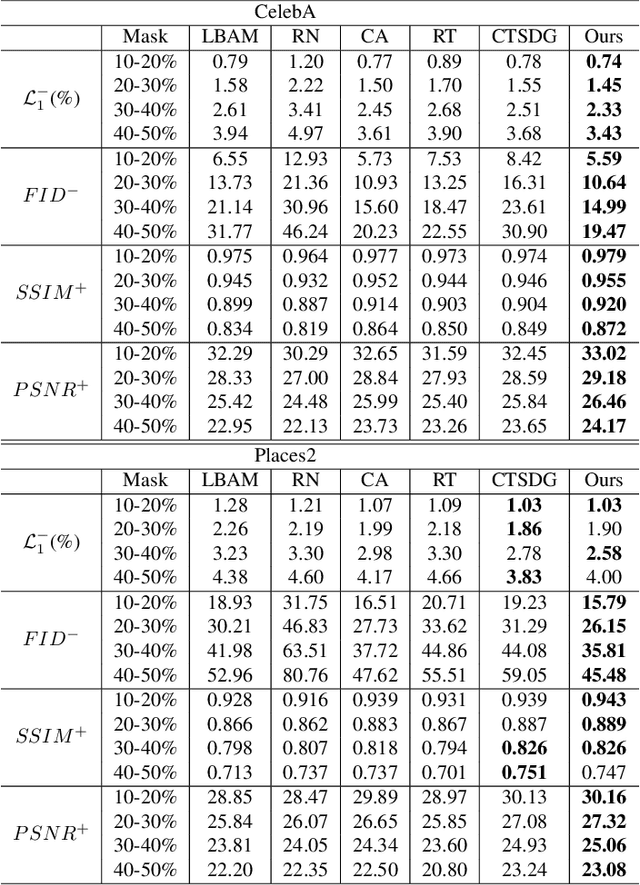
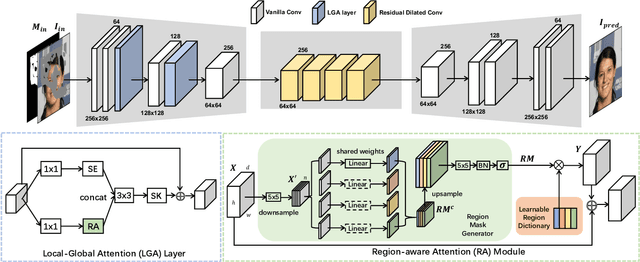
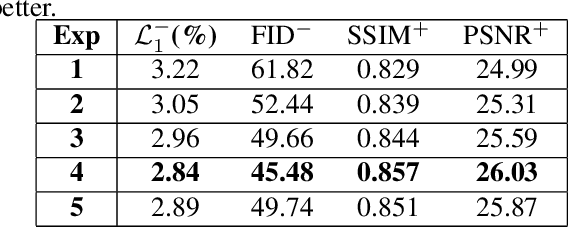
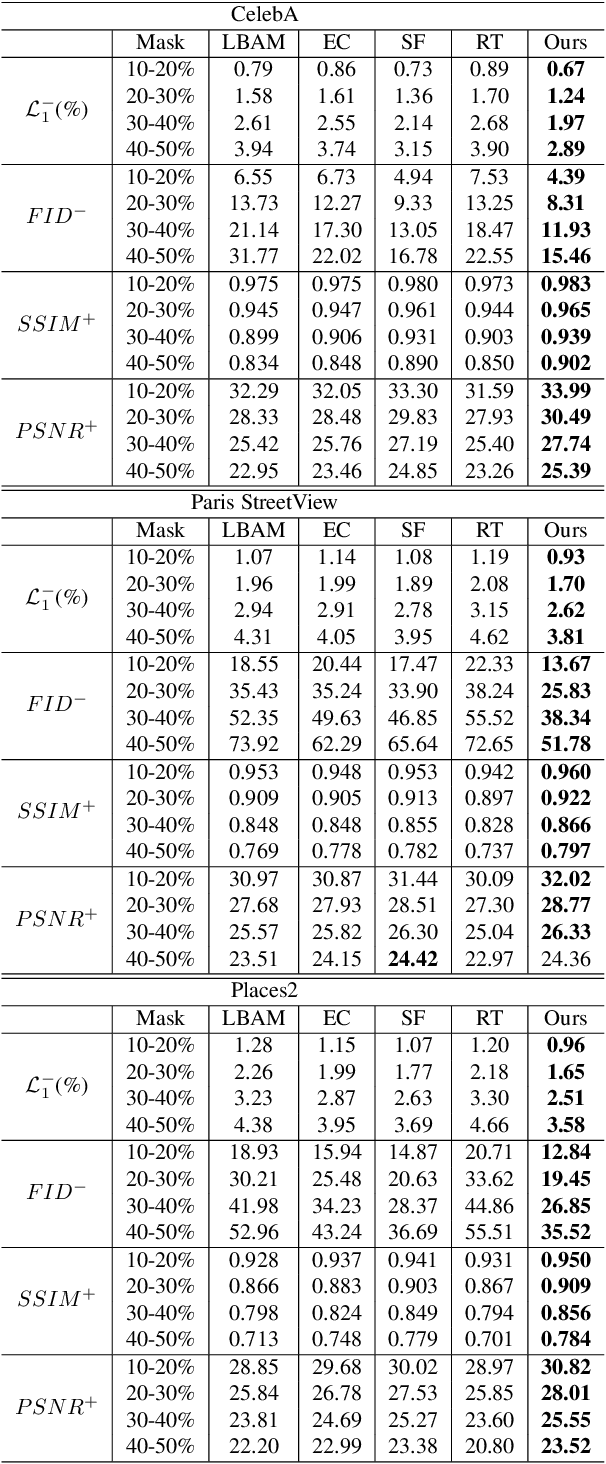
Recent attention-based image inpainting methods have made inspiring progress by modeling long-range dependencies within a single image. However, they tend to generate blurry contents since the correlation between each pixel pairs is always misled by ill-predicted features in holes. To handle this problem, we propose a novel region-aware attention (RA) module. By avoiding the directly calculating corralation between each pixel pair in a single samples and considering the correlation between different samples, the misleading of invalid information in holes can be avoided. Meanwhile, a learnable region dictionary (LRD) is introduced to store important information in the entire dataset, which not only simplifies correlation modeling, but also avoids information redundancy. By applying RA in our architecture, our methodscan generate semantically plausible results with realistic details. Extensive experiments on CelebA, Places2 and Paris StreetView datasets validate the superiority of our method compared with existing methods.
Structure-aware Image Inpainting with Two Parallel Streams
Nov 05, 2021
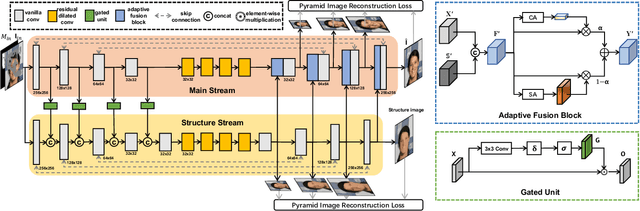
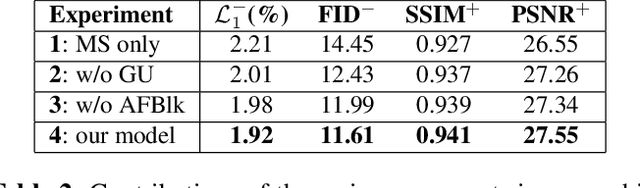
Recent works in image inpainting have shown that structural information plays an important role in recovering visually pleasing results. In this paper, we propose an end-to-end architecture composed of two parallel UNet-based streams: a main stream (MS) and a structure stream (SS). With the assistance of SS, MS can produce plausible results with reasonable structures and realistic details. Specifically, MS reconstructs detailed images by inferring missing structures and textures simultaneously, and SS restores only missing structures by processing the hierarchical information from the encoder of MS. By interacting with SS in the training process, MS can be implicitly encouraged to exploit structural cues. In order to help SS focus on structures and prevent textures in MS from being affected, a gated unit is proposed to depress structure-irrelevant activations in the information flow between MS and SS. Furthermore, the multi-scale structure feature maps in SS are utilized to explicitly guide the structure-reasonable image reconstruction in the decoder of MS through the fusion block. Extensive experiments on CelebA, Paris StreetView and Places2 datasets demonstrate that our proposed method outperforms state-of-the-art methods.