 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalMoE: A Billion-Scale Multimodal Foundation Model for Granger Causal Discovery with Pattern-Routed Heterogeneous Experts
Jun 11, 2026Granger Causal Discovery (GCD) is fundamental for analyzing temporal dependencies in complex systems. However, existing neural GCD methods predominantly rely on a "one-size-fits-all" paradigm, struggling to capture distribution shifts and dynamic regime changes inherent in real-world time series. This often leads to entangled representations and spurious causal graphs. In this paper, we propose CausalMoE, a billion-scale multimodal Granger causal foundation model that explicitly models patch-level heterogeneity. CausalMoE introduces a Pattern-Routed Mixture of Heterogeneous Experts, which dynamically identifies latent temporal patterns and routes patches to specialized domain experts, effectively decoupling regime-specific mechanisms from shared dynamics. To ensure interpretable graph recovery, we design a Causality-Aware Self-Attention mechanism operating across variables, yielding sparse Granger causal graphs via proximal optimization. Furthermore, CausalMoE is the first to integrate LLMs and VLMs to align numerical signals with textual and visual priors, regularizing causal estimation in complex scenarios. Extensive experiments demonstrate that CausalMoE establishes a new state-of-the-art on fully supervised benchmarks, while effectively generalizing to few-shot settings where traditional methods fail.
Expressive Music Data Processing and Generation
Mar 14, 2025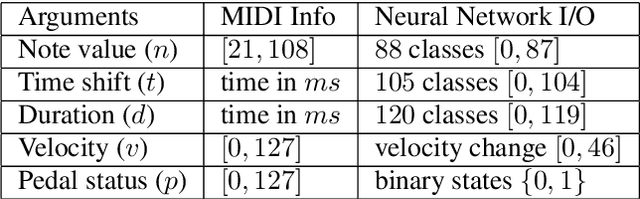
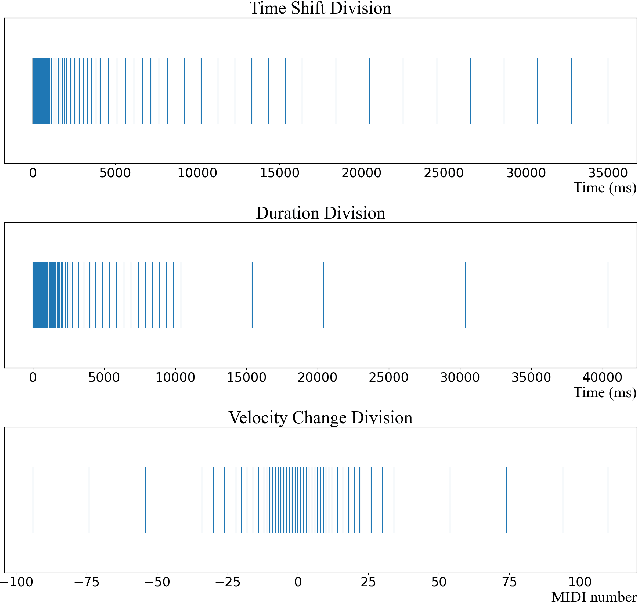
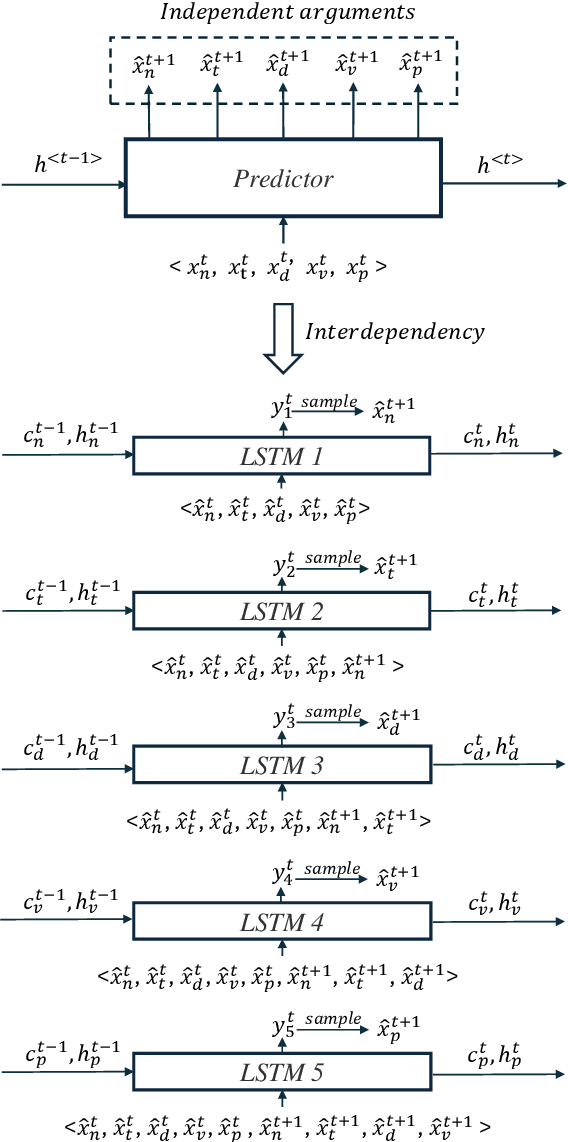
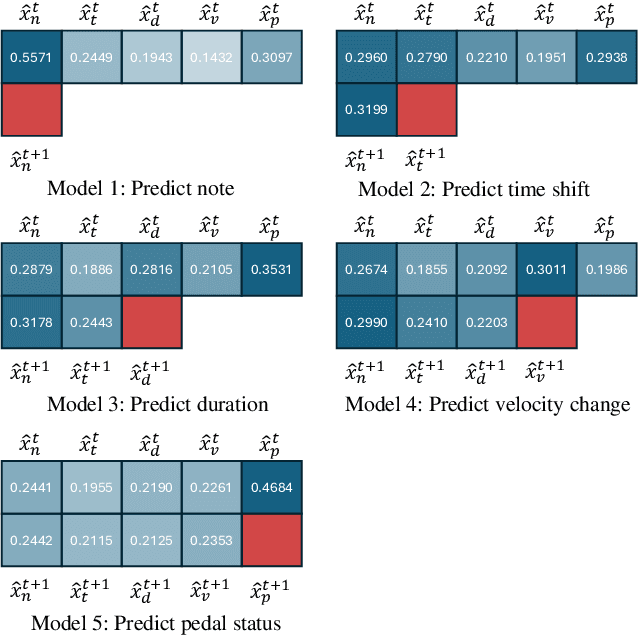
Musical expressivity and coherence are indispensable in music composition and performance, while often neglected in modern AI generative models. In this work, we introduce a listening-based data-processing technique that captures the expressivity in musical performance. This technique derived from Weber's law reflects the human perceptual truth of listening and preserves musical subtlety and expressivity in the training input. To facilitate musical coherence, we model the output interdependencies among multiple arguments in the music data such as pitch, duration, velocity, etc. in the neural networks based on the probabilistic chain rule. In practice, we decompose the multi-output sequential model into single-output submodels and condition previously sampled outputs on the subsequent submodels to induce conditional distributions. Finally, to select eligible sequences from all generations, a tentative measure based on the output entropy was proposed. The entropy sequence is set as a criterion to select predictable and stable generations, which is further studied under the context of informational aesthetic measures to quantify musical pleasure and information gain along the music tendency.
Unfaithful Probability Distributions in Binary Triple of Causality Directed Acyclic Graph
Jan 30, 2025

Faithfulness is the foundation of probability distribution and graph in causal discovery and causal inference. In this paper, several unfaithful probability distribution examples are constructed in three--vertices binary causality directed acyclic graph (DAG) structure, which are not faithful to causal DAGs described in J.M.,Robins,et al. Uniform consistency in causal inference. Biometrika (2003),90(3): 491--515. And the general unfaithful probability distribution with multiple independence and conditional independence in binary triple causal DAG is given.
Retrieval-Augmented Diffusion Models for Time Series Forecasting
Oct 24, 2024
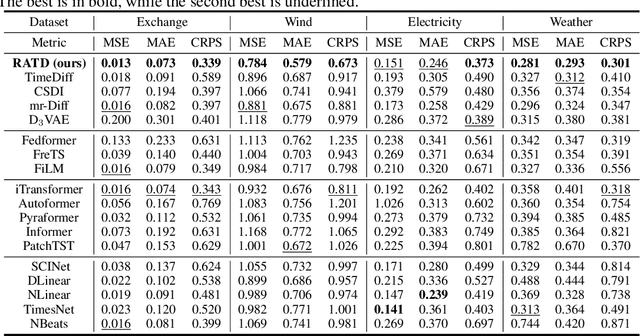
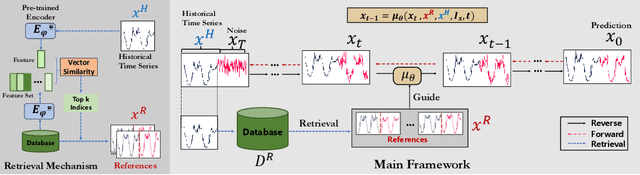

While time series diffusion models have received considerable focus from many recent works, the performance of existing models remains highly unstable. Factors limiting time series diffusion models include insufficient time series datasets and the absence of guidance. To address these limitations, we propose a Retrieval- Augmented Time series Diffusion model (RATD). The framework of RATD consists of two parts: an embedding-based retrieval process and a reference-guided diffusion model. In the first part, RATD retrieves the time series that are most relevant to historical time series from the database as references. The references are utilized to guide the denoising process in the second part. Our approach allows leveraging meaningful samples within the database to aid in sampling, thus maximizing the utilization of datasets. Meanwhile, this reference-guided mechanism also compensates for the deficiencies of existing time series diffusion models in terms of guidance. Experiments and visualizations on multiple datasets demonstrate the effectiveness of our approach, particularly in complicated prediction tasks.
Expressive MIDI-format Piano Performance Generation
Aug 01, 2024
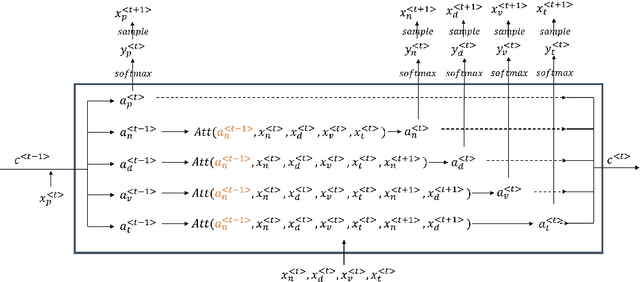
This work presents a generative neural network that's able to generate expressive piano performance in MIDI format. The musical expressivity is reflected by vivid micro-timing, rich polyphonic texture, varied dynamics, and the sustain pedal effects. This model is innovative from many aspects of data processing to neural network design. We claim that this symbolic music generation model overcame the common critics of symbolic music and is able to generate expressive music flows as good as, if not better than generations with raw audio. One drawback is that, due to the limited time for submission, the model is not fine-tuned and sufficiently trained, thus the generation may sound incoherent and random at certain points. Despite that, this model shows its powerful generative ability to generate expressive piano pieces.
Cross-Modal Contextualized Diffusion Models for Text-Guided Visual Generation and Editing
Mar 04, 2024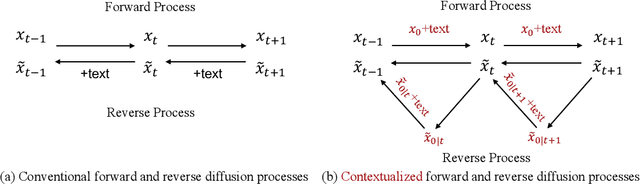
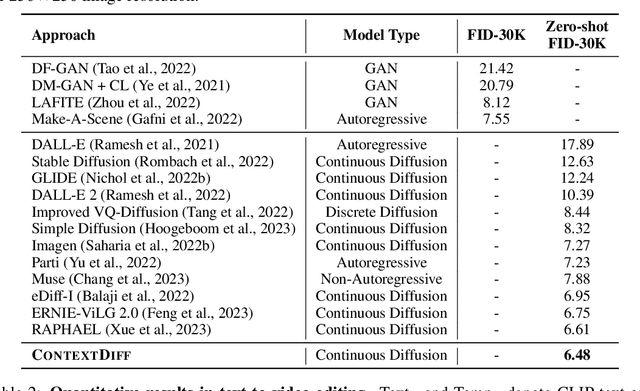

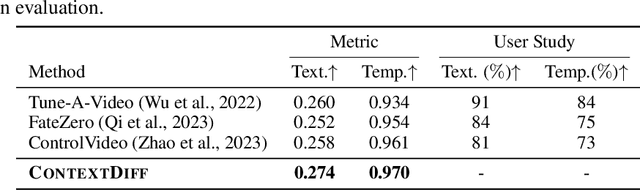
Conditional diffusion models have exhibited superior performance in high-fidelity text-guided visual generation and editing. Nevertheless, prevailing text-guided visual diffusion models primarily focus on incorporating text-visual relationships exclusively into the reverse process, often disregarding their relevance in the forward process. This inconsistency between forward and reverse processes may limit the precise conveyance of textual semantics in visual synthesis results. To address this issue, we propose a novel and general contextualized diffusion model (ContextDiff) by incorporating the cross-modal context encompassing interactions and alignments between text condition and visual sample into forward and reverse processes. We propagate this context to all timesteps in the two processes to adapt their trajectories, thereby facilitating cross-modal conditional modeling. We generalize our contextualized diffusion to both DDPMs and DDIMs with theoretical derivations, and demonstrate the effectiveness of our model in evaluations with two challenging tasks: text-to-image generation, and text-to-video editing. In each task, our ContextDiff achieves new state-of-the-art performance, significantly enhancing the semantic alignment between text condition and generated samples, as evidenced by quantitative and qualitative evaluations. Our code is available at https://github.com/YangLing0818/ContextDiff
Structure-Guided Adversarial Training of Diffusion Models
Mar 04, 2024



Diffusion models have demonstrated exceptional efficacy in various generative applications. While existing models focus on minimizing a weighted sum of denoising score matching losses for data distribution modeling, their training primarily emphasizes instance-level optimization, overlooking valuable structural information within each mini-batch, indicative of pair-wise relationships among samples. To address this limitation, we introduce Structure-guided Adversarial training of Diffusion Models (SADM). In this pioneering approach, we compel the model to learn manifold structures between samples in each training batch. To ensure the model captures authentic manifold structures in the data distribution, we advocate adversarial training of the diffusion generator against a novel structure discriminator in a minimax game, distinguishing real manifold structures from the generated ones. SADM substantially improves existing diffusion transformers (DiT) and outperforms existing methods in image generation and cross-domain fine-tuning tasks across 12 datasets, establishing a new state-of-the-art FID of 1.58 and 2.11 on ImageNet for class-conditional image generation at resolutions of 256x256 and 512x512, respectively.
Improving Diffusion-Based Image Synthesis with Context Prediction
Jan 04, 2024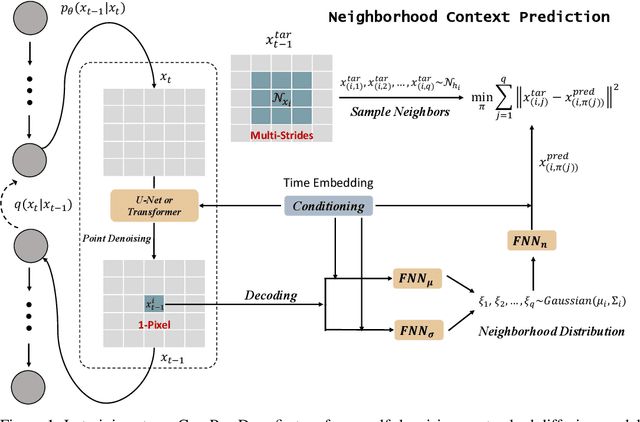
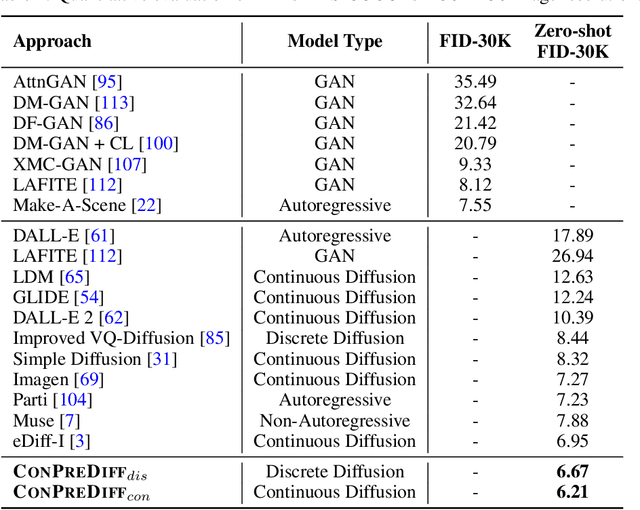

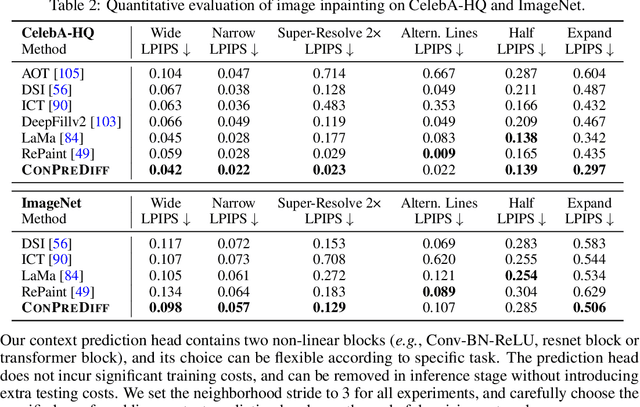
Diffusion models are a new class of generative models, and have dramatically promoted image generation with unprecedented quality and diversity. Existing diffusion models mainly try to reconstruct input image from a corrupted one with a pixel-wise or feature-wise constraint along spatial axes. However, such point-based reconstruction may fail to make each predicted pixel/feature fully preserve its neighborhood context, impairing diffusion-based image synthesis. As a powerful source of automatic supervisory signal, context has been well studied for learning representations. Inspired by this, we for the first time propose ConPreDiff to improve diffusion-based image synthesis with context prediction. We explicitly reinforce each point to predict its neighborhood context (i.e., multi-stride features/tokens/pixels) with a context decoder at the end of diffusion denoising blocks in training stage, and remove the decoder for inference. In this way, each point can better reconstruct itself by preserving its semantic connections with neighborhood context. This new paradigm of ConPreDiff can generalize to arbitrary discrete and continuous diffusion backbones without introducing extra parameters in sampling procedure. Extensive experiments are conducted on unconditional image generation, text-to-image generation and image inpainting tasks. Our ConPreDiff consistently outperforms previous methods and achieves a new SOTA text-to-image generation results on MS-COCO, with a zero-shot FID score of 6.21.
Local-Global Information Interaction Debiasing for Dynamic Scene Graph Generation
Aug 10, 2023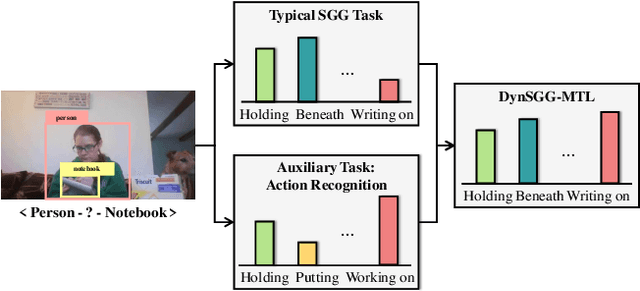
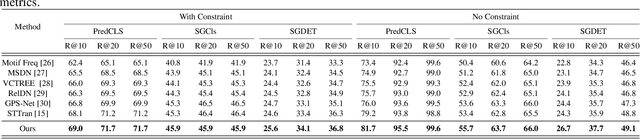
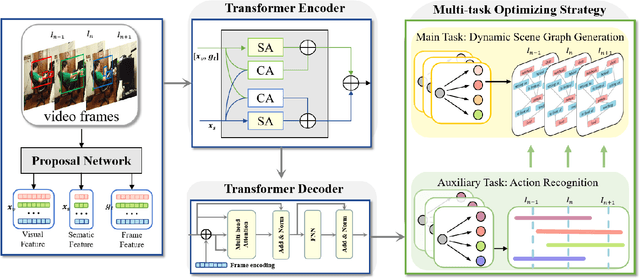
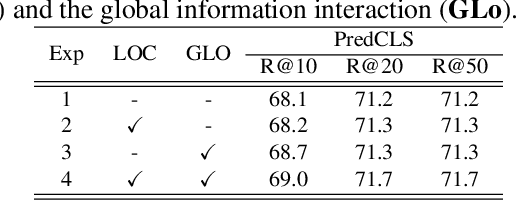
The task of dynamic scene graph generation (DynSGG) aims to generate scene graphs for given videos, which involves modeling the spatial-temporal information in the video. However, due to the long-tailed distribution of samples in the dataset, previous DynSGG models fail to predict the tail predicates. We argue that this phenomenon is due to previous methods that only pay attention to the local spatial-temporal information and neglect the consistency of multiple frames. To solve this problem, we propose a novel DynSGG model based on multi-task learning, DynSGG-MTL, which introduces the local interaction information and global human-action interaction information. The interaction between objects and frame features makes the model more fully understand the visual context of the single image. Long-temporal human actions supervise the model to generate multiple scene graphs that conform to the global constraints and avoid the model being unable to learn the tail predicates. Extensive experiments on Action Genome dataset demonstrate the efficacy of our proposed framework, which not only improves the dynamic scene graph generation but also alleviates the long-tail problem.
A Neural Network Implementation for Free Energy Principle
Jun 11, 2023The free energy principle (FEP), as an encompassing framework and a unified brain theory, has been widely applied to account for various problems in fields such as cognitive science, neuroscience, social interaction, and hermeneutics. As a computational model deeply rooted in math and statistics, FEP posits an optimization problem based on variational Bayes, which is solved either by dynamic programming or expectation maximization in practice. However, there seems to be a bottleneck in extending the FEP to machine learning and implementing such models with neural networks. This paper gives a preliminary attempt at bridging FEP and machine learning, via a classical neural network model, the Helmholtz machine. As a variational machine learning model, the Helmholtz machine is optimized by minimizing its free energy, the same objective as FEP. Although the Helmholtz machine is not temporal, it gives an ideal parallel to the vanilla FEP and the hierarchical model of the brain, under which the active inference and predictive coding could be formulated coherently. Besides a detailed theoretical discussion, the paper also presents a preliminary experiment to validate the hypothesis. By fine-tuning the trained neural network through active inference, the model performance is promoted to accuracy above 99\%. In the meantime, the data distribution is continuously deformed to a salience that conforms to the model representation, as a result of active sampling.