 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressive Music Data Processing and Generation
Paper and Code
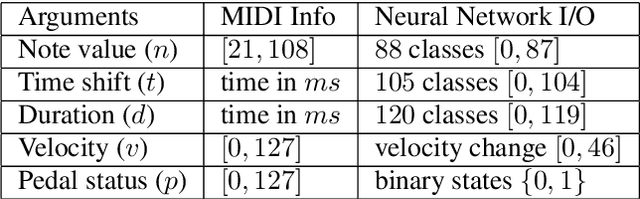
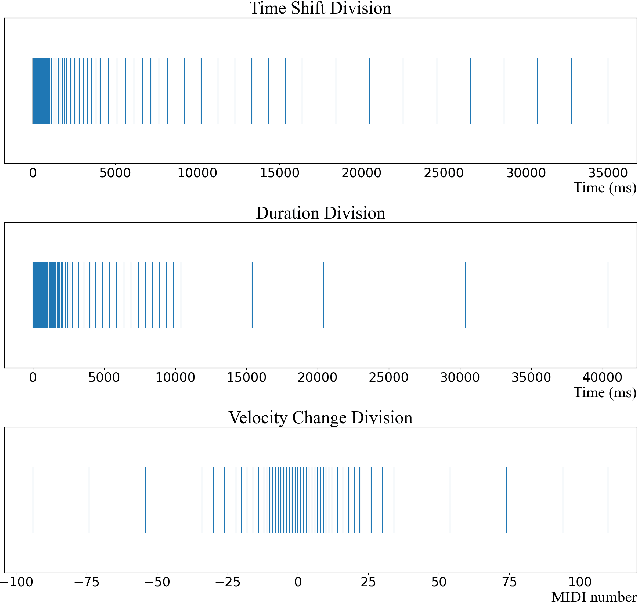
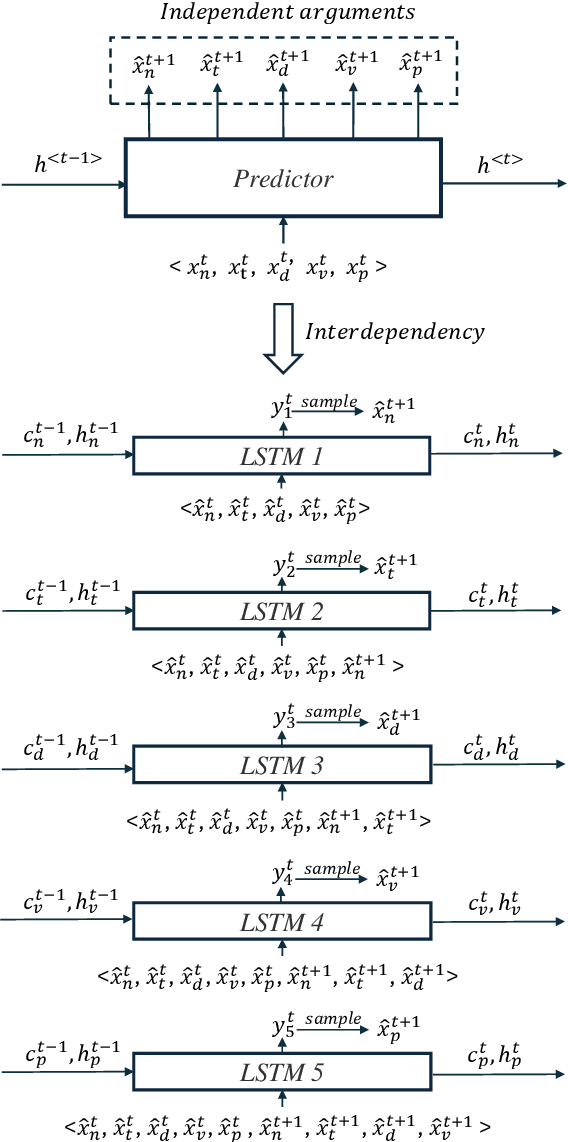
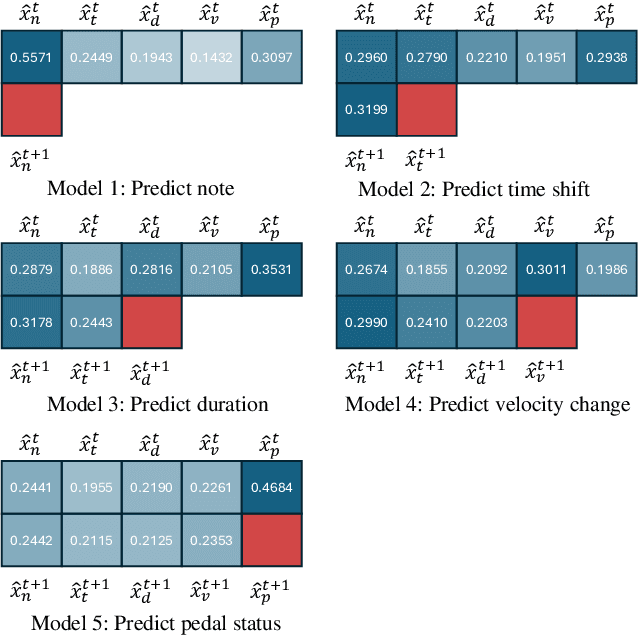
Musical expressivity and coherence are indispensable in music composition and performance, while often neglected in modern AI generative models. In this work, we introduce a listening-based data-processing technique that captures the expressivity in musical performance. This technique derived from Weber's law reflects the human perceptual truth of listening and preserves musical subtlety and expressivity in the training input. To facilitate musical coherence, we model the output interdependencies among multiple arguments in the music data such as pitch, duration, velocity, etc. in the neural networks based on the probabilistic chain rule. In practice, we decompose the multi-output sequential model into single-output submodels and condition previously sampled outputs on the subsequent submodels to induce conditional distributions. Finally, to select eligible sequences from all generations, a tentative measure based on the output entropy was proposed. The entropy sequence is set as a criterion to select predictable and stable generations, which is further studied under the context of informational aesthetic measures to quantify musical pleasure and information gain along the music tendency.