 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalMoE: A Billion-Scale Multimodal Foundation Model for Granger Causal Discovery with Pattern-Routed Heterogeneous Experts
Jun 11, 2026Granger Causal Discovery (GCD) is fundamental for analyzing temporal dependencies in complex systems. However, existing neural GCD methods predominantly rely on a "one-size-fits-all" paradigm, struggling to capture distribution shifts and dynamic regime changes inherent in real-world time series. This often leads to entangled representations and spurious causal graphs. In this paper, we propose CausalMoE, a billion-scale multimodal Granger causal foundation model that explicitly models patch-level heterogeneity. CausalMoE introduces a Pattern-Routed Mixture of Heterogeneous Experts, which dynamically identifies latent temporal patterns and routes patches to specialized domain experts, effectively decoupling regime-specific mechanisms from shared dynamics. To ensure interpretable graph recovery, we design a Causality-Aware Self-Attention mechanism operating across variables, yielding sparse Granger causal graphs via proximal optimization. Furthermore, CausalMoE is the first to integrate LLMs and VLMs to align numerical signals with textual and visual priors, regularizing causal estimation in complex scenarios. Extensive experiments demonstrate that CausalMoE establishes a new state-of-the-art on fully supervised benchmarks, while effectively generalizing to few-shot settings where traditional methods fail.
Learn-to-learn on Arbitrary Textual Conditioning: A Hypernetwork-Driven Meta-Gated LLM
May 03, 2026Conventional LLMs may suffer from corpus heterogeneity and subtle condition changes. While finetuning can create the catastrophe forgetting issue, application of meta-learning on LLMs is also limited due to its complexity and scalability. In this paper, we activate the meta-signal of $β$ within the SwiGLU blocks, resulting in a meta-gating mechanism that adaptively adjusts the nonlinearity of FFN. A hypernetwork is employed which dynamically produces $β$ on textual conditions, providing meta-controllability on LLMs. By testing on different condition types such as task, domain, persona, and style, our method outperforms finetuning and meta-learning baselines, and can generalize reasonably on unseen tasks, condition types, or instructions. Our code can be found in https://github.com/AaronJi/MeGan.
Efficient Rationale-based Retrieval: On-policy Distillation from Generative Rerankers based on JEPA
Apr 25, 2026Unlike traditional fact-based retrieval, rationale-based retrieval typically necessitates cross-encoding of query-document pairs using large language models, incurring substantial computational costs. To address this limitation, we propose Rabtriever, which independently encodes queries and documents, while providing comparable cross query-document comprehension capabilities to rerankers. We start from training a LLM-based generative reranker, which puts the document prior to the query and prompts the LLM to generate the relevance score by log probabilities. We then employ it as the teacher of an on-policy distillation framework, with Rabtriever as the student to reconstruct the teacher's contextual-aware query embedding. To achieve this effect, Rabtriever is first initialized from the teacher, with parameters frozen. The Joint-Embedding Predictive Architecture (JEPA) paradigm is then adopted, which integrates a lightweight, trainable predictor between LLM layers and heads, projecting the query embedding into a new hidden space, with the document embedding as the latent vector. JEPA then minimizes the distribution difference between this projected embedding and the teacher embedding. To strengthen the sampling efficiency of on-policy distillation, we also add an auxiliary loss on the reverse KL of LLM logits, to reshape the student's logit distribution. Rabtriever optimizes the teacher's quadratic complexity on the document length to linear, verified both theoretically and empirically. Experiments show that Rabtriever outperforms different retriever baselines across diverse rationale-based tasks, including empathetic conversations and robotic manipulations, with minor accuracy degradation from the reranker. Rabtriever also generalizes well on traditional retrieval benchmarks such as MS MARCO and BEIR, with comparable performance to the best retriever baseline.
ChemCLIP: Bridging Organic and Inorganic Anticancer Compounds Through Contrastive Learning
Mar 30, 2026The discovery of anticancer therapeutics has traditionally treated organic small molecules and metal-based coordination complexes as separate chemical domains, limiting knowledge transfer despite their shared biological objectives. This disparity is particularly pronounced in available data, with extensive screening databases for organic compounds compared to only a few thousand characterized metal complexes. Here, we introduce ChemCLIP, a dual-encoder contrastive learning framework that bridges this organic-inorganic divide by learning unified representations based on shared anticancer activities rather than structural similarity. We compiled complementary datasets comprising 44,854 unique organic compounds and 5,164 unique metal complexes, standardized across 60 cancer cell lines. By training parallel encoders with activity-aware hard negative mining, we mapped structurally distinct compounds into a shared 256-dimensional embedding space where biologically similar compounds cluster together regardless of chemical class. We systematically evaluated four molecular encoding strategies: Morgan fingerprints, ChemBERTa, MolFormer, and Chemprop, through quantitative alignment metrics, embedding visualizations, and downstream classification tasks. Morgan fingerprints achieved superior performance with an average alignment ratio of 0.899 and downstream classification AUCs of 0.859 (inorganic) and 0.817 (organic). This work establishes contrastive learning as an effective strategy for unifying disparate chemical domains and provides empirical guidance for encoder selection in multi-modal chemistry applications, with implications extending beyond anticancer drug discovery to any scenario requiring cross-domain chemical knowledge transfer.
MieDB-100k: A Comprehensive Dataset for Medical Image Editing
Feb 10, 2026The scarcity of high-quality data remains a primary bottleneck in adapting multimodal generative models for medical image editing. Existing medical image editing datasets often suffer from limited diversity, neglect of medical image understanding and inability to balance quality with scalability. To address these gaps, we propose MieDB-100k, a large-scale, high-quality and diverse dataset for text-guided medical image editing. It categorizes editing tasks into perspectives of Perception, Modification and Transformation, considering both understanding and generation abilities. We construct MieDB-100k via a data curation pipeline leveraging both modality-specific expert models and rule-based data synthetic methods, followed by rigorous manual inspection to ensure clinical fidelity. Extensive experiments demonstrate that model trained with MieDB-100k consistently outperform both open-source and proprietary models while exhibiting strong generalization ability. We anticipate that this dataset will serve as a cornerstone for future advancements in specialized medical image editing.
ECG-R1: Protocol-Guided and Modality-Agnostic MLLM for Reliable ECG Interpretation
Feb 04, 2026Electrocardiography (ECG) serves as an indispensable diagnostic tool in clinical practice, yet existing multimodal large language models (MLLMs) remain unreliable for ECG interpretation, often producing plausible but clinically incorrect analyses. To address this, we propose ECG-R1, the first reasoning MLLM designed for reliable ECG interpretation via three innovations. First, we construct the interpretation corpus using \textit{Protocol-Guided Instruction Data Generation}, grounding interpretation in measurable ECG features and monograph-defined quantitative thresholds and diagnostic logic. Second, we present a modality-decoupled architecture with \textit{Interleaved Modality Dropout} to improve robustness and cross-modal consistency when either the ECG signal or ECG image is missing. Third, we present \textit{Reinforcement Learning with ECG Diagnostic Evidence Rewards} to strengthen evidence-grounded ECG interpretation. Additionally, we systematically evaluate the ECG interpretation capabilities of proprietary, open-source, and medical MLLMs, and provide the first quantitative evidence that severe hallucinations are widespread, suggesting that the public should not directly trust these outputs without independent verification. Code and data are publicly available at \href{https://github.com/PKUDigitalHealth/ECG-R1}{here}, and an online platform can be accessed at \href{http://ai.heartvoice.com.cn/ECG-R1/}{here}.
ECGFlowCMR: Pretraining with ECG-Generated Cine CMR Improves Cardiac Disease Classification and Phenotype Prediction
Jan 28, 2026Cardiac Magnetic Resonance (CMR) imaging provides a comprehensive assessment of cardiac structure and function but remains constrained by high acquisition costs and reliance on expert annotations, limiting the availability of large-scale labeled datasets. In contrast, electrocardiograms (ECGs) are inexpensive, widely accessible, and offer a promising modality for conditioning the generative synthesis of cine CMR. To this end, we propose ECGFlowCMR, a novel ECG-to-CMR generative framework that integrates a Phase-Aware Masked Autoencoder (PA-MAE) and an Anatomy-Motion Disentangled Flow (AMDF) to address two fundamental challenges: (1) the cross-modal temporal mismatch between multi-beat ECG recordings and single-cycle CMR sequences, and (2) the anatomical observability gap due to the limited structural information inherent in ECGs. Extensive experiments on the UK Biobank and a proprietary clinical dataset demonstrate that ECGFlowCMR can generate realistic cine CMR sequences from ECG inputs, enabling scalable pretraining and improving performance on downstream cardiac disease classification and phenotype prediction tasks.
ActErase: A Training-Free Paradigm for Precise Concept Erasure via Activation Patching
Jan 01, 2026Recent advances in text-to-image diffusion models have demonstrated remarkable generation capabilities, yet they raise significant concerns regarding safety, copyright, and ethical implications. Existing concept erasure methods address these risks by removing sensitive concepts from pre-trained models, but most of them rely on data-intensive and computationally expensive fine-tuning, which poses a critical limitation. To overcome these challenges, inspired by the observation that the model's activations are predominantly composed of generic concepts, with only a minimal component can represent the target concept, we propose a novel training-free method (ActErase) for efficient concept erasure. Specifically, the proposed method operates by identifying activation difference regions via prompt-pair analysis, extracting target activations and dynamically replacing input activations during forward passes. Comprehensive evaluations across three critical erasure tasks (nudity, artistic style, and object removal) demonstrates that our training-free method achieves state-of-the-art (SOTA) erasure performance, while effectively preserving the model's overall generative capability. Our approach also exhibits strong robustness against adversarial attacks, establishing a new plug-and-play paradigm for lightweight yet effective concept manipulation in diffusion models.
CodeContests+: High-Quality Test Case Generation for Competitive Programming
Jun 06, 2025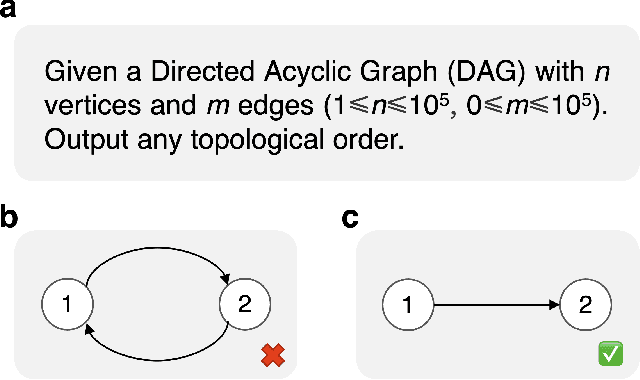
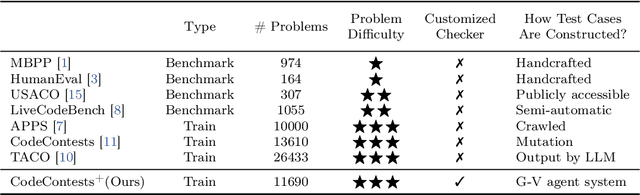
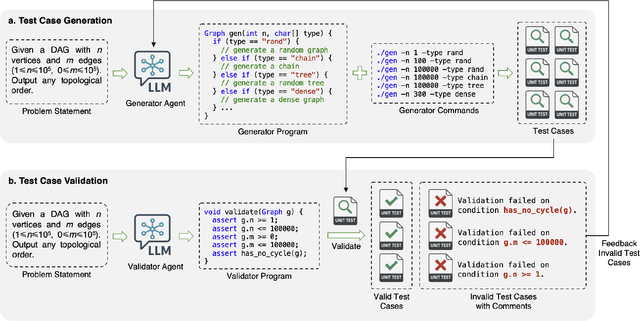
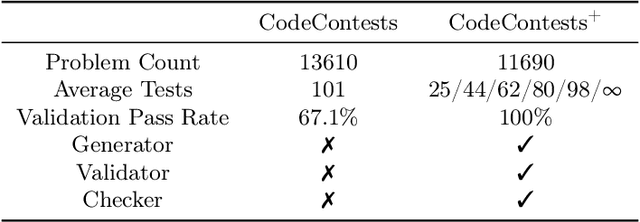
Competitive programming, due to its high reasoning difficulty and precise correctness feedback, has become a key task for both training and evaluating the reasoning capabilities of large language models (LLMs). However, while a large amount of public problem data, such as problem statements and solutions, is available, the test cases of these problems are often difficult to obtain. Therefore, test case generation is a necessary task for building large-scale datasets, and the quality of the test cases directly determines the accuracy of the evaluation. In this paper, we introduce an LLM-based agent system that creates high-quality test cases for competitive programming problems. We apply this system to the CodeContests dataset and propose a new version with improved test cases, named CodeContests+. We evaluated the quality of test cases in CodeContestsPlus. First, we used 1.72 million submissions with pass/fail labels to examine the accuracy of these test cases in evaluation. The results indicated that CodeContests+ achieves significantly higher accuracy than CodeContests, particularly with a notably higher True Positive Rate (TPR). Subsequently, our experiments in LLM Reinforcement Learning (RL) further confirmed that improvements in test case quality yield considerable advantages for RL.
T2S: High-resolution Time Series Generation with Text-to-Series Diffusion Models
May 05, 2025Text-to-Time Series generation holds significant potential to address challenges such as data sparsity, imbalance, and limited availability of multimodal time series datasets across domains. While diffusion models have achieved remarkable success in Text-to-X (e.g., vision and audio data) generation, their use in time series generation remains in its nascent stages. Existing approaches face two critical limitations: (1) the lack of systematic exploration of general-proposed time series captions, which are often domain-specific and struggle with generalization; and (2) the inability to generate time series of arbitrary lengths, limiting their applicability to real-world scenarios. In this work, we first categorize time series captions into three levels: point-level, fragment-level, and instance-level. Additionally, we introduce a new fragment-level dataset containing over 600,000 high-resolution time series-text pairs. Second, we propose Text-to-Series (T2S), a diffusion-based framework that bridges the gap between natural language and time series in a domain-agnostic manner. T2S employs a length-adaptive variational autoencoder to encode time series of varying lengths into consistent latent embeddings. On top of that, T2S effectively aligns textual representations with latent embeddings by utilizing Flow Matching and employing Diffusion Transformer as the denoiser. We train T2S in an interleaved paradigm across multiple lengths, allowing it to generate sequences of any desired length. Extensive evaluations demonstrate that T2S achieves state-of-the-art performance across 13 datasets spanning 12 domains.