 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiT as Real-Time Rerenderer: Streaming Video Stylization with Autoregressive Diffusion Transformer
Apr 15, 2026Recent advances in video generation models has significantly accelerated video generation and related downstream tasks. Among these, video stylization holds important research value in areas such as immersive applications and artistic creation, attracting widespread attention. However, existing diffusion-based video stylization methods struggle to maintain stability and consistency when processing long videos, and their high computational cost and multi-step denoising make them difficult to apply in practical scenarios. In this work, we propose RTR-DiT (DiT as Real-Time Rerenderer), a steaming video stylization framework built upon Diffusion Transformer. We first fine-tune a bidirectional teacher model on a curated video stylization dataset, supporting both text-guided and reference-guided video stylization tasks, and subsequently distill it into a few-step autoregressive model via post-training with Self Forcing and Distribution Matching Distillation. Furthermore, we propose a reference-preserving KV cache update strategy that not only enables stable and consistent processing of long videos, but also supports real-time switching between text prompts and reference images. Experimental results show that RTR-DiT outperforms existing methods in both text-guided and reference-guided video stylization tasks, in terms of quantitative metrics and visual quality, and demonstrates excellent performance in real-time long video stylization and interactive style-switching applications.
Generative Frontiers: Why Evaluation Matters for Diffusion Language Models
Apr 03, 2026Diffusion language models have seen exciting recent progress, offering far more flexibility in generative trajectories than autoregressive models. This flexibility has motivated a growing body of research into new approaches to diffusion language modeling, which typically begins at the scale of GPT-2 small (150 million parameters). However, these advances introduce new issues with evaluation methodology. In this technical note, we discuss the limitations of current methodology and propose principled augmentations to ensure reliable comparisons. We first discuss why OpenWebText has become the standard benchmark, and why alternatives such as LM1B are inherently less meaningful. We then discuss the limitations of likelihood evaluations for diffusion models, and explain why relying on generative perplexity alone as a metric can lead to uninformative results. To address this, we show that generative perplexity and entropy are two components of the KL divergence to a reference distribution. This decomposition explains generative perplexity's sensitivity to entropy, and naturally suggests generative frontiers as a principled method for evaluating model generative quality. We conclude with empirical observations on model quality at this scale. We include a blog post with interactive content to illustrate the argument at https://patrickpynadath1.github.io/blog/eval_methodology/.
CoMo: Compositional Motion Customization for Text-to-Video Generation
Oct 27, 2025While recent text-to-video models excel at generating diverse scenes, they struggle with precise motion control, particularly for complex, multi-subject motions. Although methods for single-motion customization have been developed to address this gap, they fail in compositional scenarios due to two primary challenges: motion-appearance entanglement and ineffective multi-motion blending. This paper introduces CoMo, a novel framework for $\textbf{compositional motion customization}$ in text-to-video generation, enabling the synthesis of multiple, distinct motions within a single video. CoMo addresses these issues through a two-phase approach. First, in the single-motion learning phase, a static-dynamic decoupled tuning paradigm disentangles motion from appearance to learn a motion-specific module. Second, in the multi-motion composition phase, a plug-and-play divide-and-merge strategy composes these learned motions without additional training by spatially isolating their influence during the denoising process. To facilitate research in this new domain, we also introduce a new benchmark and a novel evaluation metric designed to assess multi-motion fidelity and blending. Extensive experiments demonstrate that CoMo achieves state-of-the-art performance, significantly advancing the capabilities of controllable video generation. Our project page is at https://como6.github.io/.
CANDI: Hybrid Discrete-Continuous Diffusion Models
Oct 26, 2025While continuous diffusion has shown remarkable success in continuous domains such as image generation, its direct application to discrete data has underperformed compared to purely discrete formulations. This gap is counterintuitive, given that continuous diffusion learns score functions that enable joint evolution across multiple positions. To understand this gap, we introduce token identifiability as an analytical framework for understanding how Gaussian noise corrupts discrete data through two mechanisms: discrete identity corruption and continuous rank degradation. We reveal that these mechanisms scale differently with vocabulary size, creating a temporal dissonance: at noise levels where discrete corruption preserves enough structure for conditional learning, continuous denoising is trivial; at noise levels where continuous denoising is meaningful, discrete corruption destroys nearly all conditional structure. To solve this, we propose CANDI (Continuous ANd DIscrete diffusion), a hybrid framework that decouples discrete and continuous corruption, enabling simultaneous learning of both conditional structure and continuous geometry. We empirically validate the temporal dissonance phenomenon and demonstrate that CANDI successfully avoids it. This unlocks the benefits of continuous diffusion for discrete spaces: on controlled generation, CANDI enables classifier-based guidance with off-the-shelf classifiers through simple gradient addition; on text generation, CANDI outperforms masked diffusion at low NFE, demonstrating the value of learning continuous gradients for discrete spaces.
Learning-Order Autoregressive Models with Application to Molecular Graph Generation
Mar 07, 2025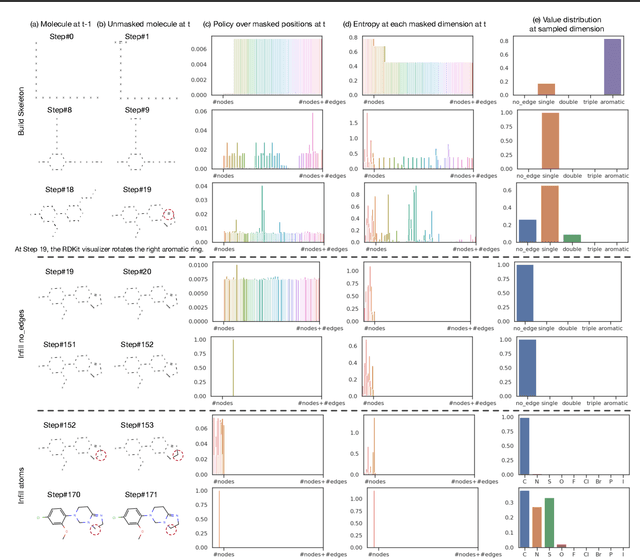
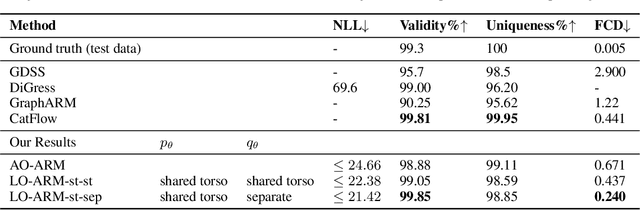
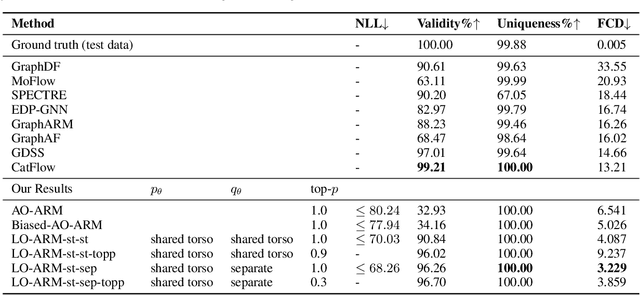
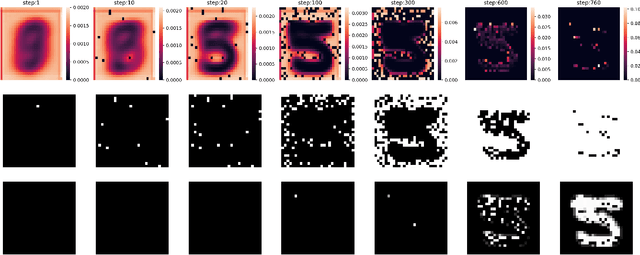
Autoregressive models (ARMs) have become the workhorse for sequence generation tasks, since many problems can be modeled as next-token prediction. While there appears to be a natural ordering for text (i.e., left-to-right), for many data types, such as graphs, the canonical ordering is less obvious. To address this problem, we introduce a variant of ARM that generates high-dimensional data using a probabilistic ordering that is sequentially inferred from data. This model incorporates a trainable probability distribution, referred to as an \emph{order-policy}, that dynamically decides the autoregressive order in a state-dependent manner. To train the model, we introduce a variational lower bound on the exact log-likelihood, which we optimize with stochastic gradient estimation. We demonstrate experimentally that our method can learn meaningful autoregressive orderings in image and graph generation. On the challenging domain of molecular graph generation, we achieve state-of-the-art results on the QM9 and ZINC250k benchmarks, evaluated using the Fr\'{e}chet ChemNet Distance (FCD).
Test-time regression: a unifying framework for designing sequence models with associative memory
Jan 21, 2025


Sequences provide a remarkably general way to represent and process information. This powerful abstraction has placed sequence modeling at the center of modern deep learning applications, inspiring numerous architectures from transformers to recurrent networks. While this fragmented development has yielded powerful models, it has left us without a unified framework to understand their fundamental similarities and explain their effectiveness. We present a unifying framework motivated by an empirical observation: effective sequence models must be able to perform associative recall. Our key insight is that memorizing input tokens through an associative memory is equivalent to performing regression at test-time. This regression-memory correspondence provides a framework for deriving sequence models that can perform associative recall, offering a systematic lens to understand seemingly ad-hoc architectural choices. We show numerous recent architectures -- including linear attention models, their gated variants, state-space models, online learners, and softmax attention -- emerge naturally as specific approaches to test-time regression. Each architecture corresponds to three design choices: the relative importance of each association, the regressor function class, and the optimization algorithm. This connection leads to new understanding: we provide theoretical justification for QKNorm in softmax attention, and we motivate higher-order generalizations of softmax attention. Beyond unification, our work unlocks decades of rich statistical tools that can guide future development of more powerful yet principled sequence models.
LoRA of Change: Learning to Generate LoRA for the Editing Instruction from A Single Before-After Image Pair
Nov 28, 2024In this paper, we propose the LoRA of Change (LoC) framework for image editing with visual instructions, i.e., before-after image pairs. Compared to the ambiguities, insufficient specificity, and diverse interpretations of natural language, visual instructions can accurately reflect users' intent. Building on the success of LoRA in text-based image editing and generation, we dynamically learn an instruction-specific LoRA to encode the "change" in a before-after image pair, enhancing the interpretability and reusability of our model. Furthermore, generalizable models for image editing with visual instructions typically require quad data, i.e., a before-after image pair, along with query and target images. Due to the scarcity of such quad data, existing models are limited to a narrow range of visual instructions. To overcome this limitation, we introduce the LoRA Reverse optimization technique, enabling large-scale training with paired data alone. Extensive qualitative and quantitative experiments demonstrate that our model produces high-quality images that align with user intent and support a broad spectrum of real-world visual instructions.
Ca2-VDM: Efficient Autoregressive Video Diffusion Model with Causal Generation and Cache Sharing
Nov 25, 2024With the advance of diffusion models, today's video generation has achieved impressive quality. To extend the generation length and facilitate real-world applications, a majority of video diffusion models (VDMs) generate videos in an autoregressive manner, i.e., generating subsequent clips conditioned on the last frame(s) of the previous clip. However, existing autoregressive VDMs are highly inefficient and redundant: The model must re-compute all the conditional frames that are overlapped between adjacent clips. This issue is exacerbated when the conditional frames are extended autoregressively to provide the model with long-term context. In such cases, the computational demands increase significantly (i.e., with a quadratic complexity w.r.t. the autoregression step). In this paper, we propose Ca2-VDM, an efficient autoregressive VDM with Causal generation and Cache sharing. For causal generation, it introduces unidirectional feature computation, which ensures that the cache of conditional frames can be precomputed in previous autoregression steps and reused in every subsequent step, eliminating redundant computations. For cache sharing, it shares the cache across all denoising steps to avoid the huge cache storage cost. Extensive experiments demonstrated that our Ca2-VDM achieves state-of-the-art quantitative and qualitative video generation results and significantly improves the generation speed. Code is available at https://github.com/Dawn-LX/CausalCache-VDM
Re-TASK: Revisiting LLM Tasks from Capability, Skill, and Knowledge Perspectives
Aug 13, 2024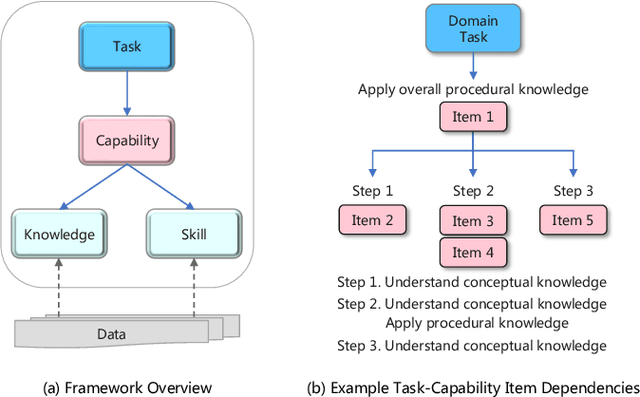
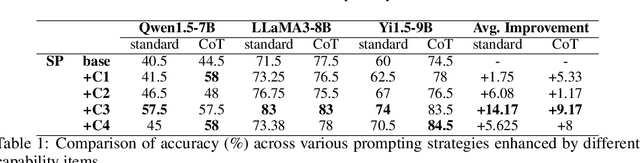

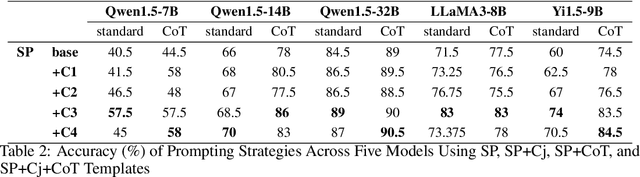
As large language models (LLMs) continue to scale, their enhanced performance often proves insufficient for solving domain-specific tasks. Systematically analyzing their failures and effectively enhancing their performance remain significant challenges. This paper introduces the Re-TASK framework, a novel theoretical model that Revisits LLM Tasks from cApability, Skill, Knowledge perspectives, guided by the principles of Bloom's Taxonomy and Knowledge Space Theory. The Re-TASK framework provides a systematic methodology to deepen our understanding, evaluation, and enhancement of LLMs for domain-specific tasks. It explores the interplay among an LLM's capabilities, the knowledge it processes, and the skills it applies, elucidating how these elements are interconnected and impact task performance. Our application of the Re-TASK framework reveals that many failures in domain-specific tasks can be attributed to insufficient knowledge or inadequate skill adaptation. With this insight, we propose structured strategies for enhancing LLMs through targeted knowledge injection and skill adaptation. Specifically, we identify key capability items associated with tasks and employ a deliberately designed prompting strategy to enhance task performance, thereby reducing the need for extensive fine-tuning. Alternatively, we fine-tune the LLM using capability-specific instructions, further validating the efficacy of our framework. Experimental results confirm the framework's effectiveness, demonstrating substantial improvements in both the performance and applicability of LLMs.
Informed Correctors for Discrete Diffusion Models
Jul 30, 2024Discrete diffusion modeling is a promising framework for modeling and generating data in discrete spaces. To sample from these models, different strategies present trade-offs between computation and sample quality. A predominant sampling strategy is predictor-corrector $\tau$-leaping, which simulates the continuous time generative process with discretized predictor steps and counteracts the accumulation of discretization error via corrector steps. However, for absorbing state diffusion, an important class of discrete diffusion models, the standard forward-backward corrector can be ineffective in fixing such errors, resulting in subpar sample quality. To remedy this problem, we propose a family of informed correctors that more reliably counteracts discretization error by leveraging information learned by the model. For further efficiency gains, we also propose $k$-Gillespie's, a sampling algorithm that better utilizes each model evaluation, while still enjoying the speed and flexibility of $\tau$-leaping. Across several real and synthetic datasets, we show that $k$-Gillespie's with informed correctors reliably produces higher quality samples at lower computational cost.