 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Personalized Understanding, Generating and Editing
Jan 11, 2026Unified large multimodal models (LMMs) have achieved remarkable progress in general-purpose multimodal understanding and generation. However, they still operate under a ``one-size-fits-all'' paradigm and struggle to model user-specific concepts (e.g., generate a photo of \texttt{<maeve>}) in a consistent and controllable manner. Existing personalization methods typically rely on external retrieval, which is inefficient and poorly integrated into unified multimodal pipelines. Recent personalized unified models introduce learnable soft prompts to encode concept information, yet they either couple understanding and generation or depend on complex multi-stage training, leading to cross-task interference and ultimately to fuzzy or misaligned personalized knowledge. We present \textbf{OmniPersona}, an end-to-end personalization framework for unified LMMs that, for the first time, integrates personalized understanding, generation, and image editing within a single architecture. OmniPersona introduces structurally decoupled concept tokens, allocating dedicated subspaces for different tasks to minimize interference, and incorporates an explicit knowledge replay mechanism that propagates personalized attribute knowledge across tasks, enabling consistent personalized behavior. To systematically evaluate unified personalization, we propose \textbf{\texttt{OmniPBench}}, extending the public UnifyBench concept set with personalized editing tasks and cross-task evaluation protocols integrating understanding, generation, and editing. Experimental results demonstrate that OmniPersona delivers competitive and robust performance across diverse personalization tasks. We hope OmniPersona will serve as a strong baseline and spur further research on controllable, unified personalization.
$\text{H}^2$em: Learning Hierarchical Hyperbolic Embeddings for Compositional Zero-Shot Learning
Dec 23, 2025Compositional zero-shot learning (CZSL) aims to recognize unseen state-object compositions by generalizing from a training set of their primitives (state and object). Current methods often overlook the rich hierarchical structures, such as the semantic hierarchy of primitives (e.g., apple fruit) and the conceptual hierarchy between primitives and compositions (e.g, sliced apple apple). A few recent efforts have shown effectiveness in modeling these hierarchies through loss regularization within Euclidean space. In this paper, we argue that they fail to scale to the large-scale taxonomies required for real-world CZSL: the space's polynomial volume growth in flat geometry cannot match the exponential structure, impairing generalization capacity. To this end, we propose H2em, a new framework that learns Hierarchical Hyperbolic EMbeddings for CZSL. H2em leverages the unique properties of hyperbolic geometry, a space naturally suited for embedding tree-like structures with low distortion. However, a naive hyperbolic mapping may suffer from hierarchical collapse and poor fine-grained discrimination. We further design two learning objectives to structure this space: a Dual-Hierarchical Entailment Loss that uses hyperbolic entailment cones to enforce the predefined hierarchies, and a Discriminative Alignment Loss with hard negative mining to establish a large geodesic distance between semantically similar compositions. Furthermore, we devise Hyperbolic Cross-Modal Attention to realize instance-aware cross-modal infusion within hyperbolic geometry. Extensive ablations on three benchmarks demonstrate that H2em establishes a new state-of-the-art in both closed-world and open-world scenarios. Our codes will be released.
CoMo: Compositional Motion Customization for Text-to-Video Generation
Oct 27, 2025While recent text-to-video models excel at generating diverse scenes, they struggle with precise motion control, particularly for complex, multi-subject motions. Although methods for single-motion customization have been developed to address this gap, they fail in compositional scenarios due to two primary challenges: motion-appearance entanglement and ineffective multi-motion blending. This paper introduces CoMo, a novel framework for $\textbf{compositional motion customization}$ in text-to-video generation, enabling the synthesis of multiple, distinct motions within a single video. CoMo addresses these issues through a two-phase approach. First, in the single-motion learning phase, a static-dynamic decoupled tuning paradigm disentangles motion from appearance to learn a motion-specific module. Second, in the multi-motion composition phase, a plug-and-play divide-and-merge strategy composes these learned motions without additional training by spatially isolating their influence during the denoising process. To facilitate research in this new domain, we also introduce a new benchmark and a novel evaluation metric designed to assess multi-motion fidelity and blending. Extensive experiments demonstrate that CoMo achieves state-of-the-art performance, significantly advancing the capabilities of controllable video generation. Our project page is at https://como6.github.io/.
MICAS: Multi-grained In-Context Adaptive Sampling for 3D Point Cloud Processing
Nov 25, 2024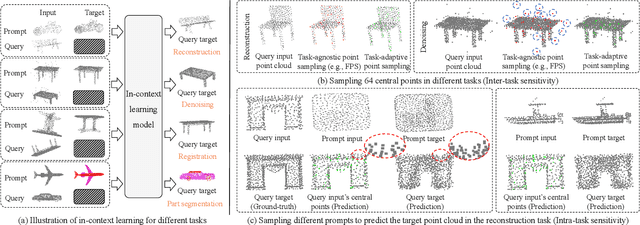
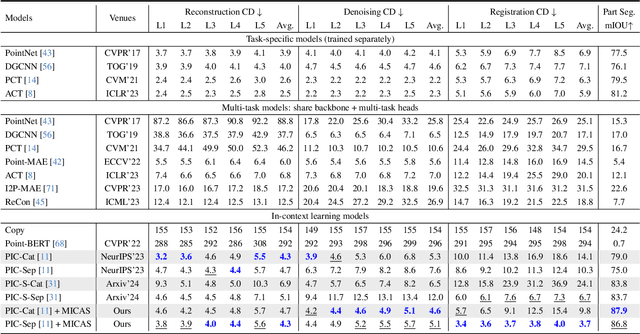
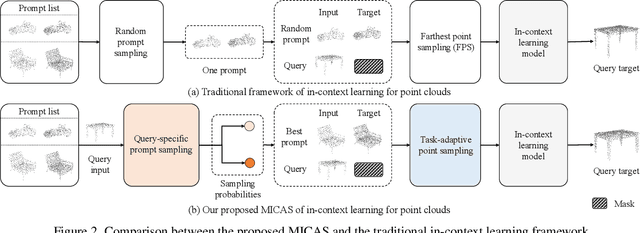
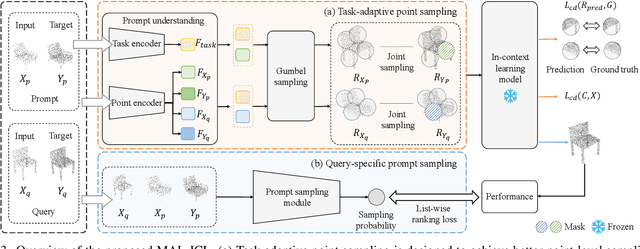
Point cloud processing (PCP) encompasses tasks like reconstruction, denoising, registration, and segmentation, each often requiring specialized models to address unique task characteristics. While in-context learning (ICL) has shown promise across tasks by using a single model with task-specific demonstration prompts, its application to PCP reveals significant limitations. We identify inter-task and intra-task sensitivity issues in current ICL methods for PCP, which we attribute to inflexible sampling strategies lacking context adaptation at the point and prompt levels. To address these challenges, we propose MICAS, an advanced ICL framework featuring a multi-grained adaptive sampling mechanism tailored for PCP. MICAS introduces two core components: task-adaptive point sampling, which leverages inter-task cues for point-level sampling, and query-specific prompt sampling, which selects optimal prompts per query to mitigate intra-task sensitivity. To our knowledge, this is the first approach to introduce adaptive sampling tailored to the unique requirements of point clouds within an ICL framework. Extensive experiments show that MICAS not only efficiently handles various PCP tasks but also significantly outperforms existing methods. Notably, it achieves a remarkable $4.1\%$ improvement in the part segmentation task and delivers consistent gains across various PCP applications.
Mitigating Biased Activation in Weakly-supervised Object Localization via Counterfactual Learning
May 24, 2023In this paper, we focus on an under-explored issue of biased activation in prior weakly-supervised object localization methods based on Class Activation Mapping (CAM). We analyze the cause of this problem from a causal view and attribute it to the co-occurring background confounders. Following this insight, we propose a novel Counterfactual Co-occurring Learning (CCL) paradigm to synthesize the counterfactual representations via coupling constant foreground and unrealized backgrounds in order to cut off their co-occurring relationship. Specifically, we design a new network structure called Counterfactual-CAM, which embeds the counterfactual representation perturbation mechanism into the vanilla CAM-based model. This mechanism is responsible for decoupling foreground as well as background and synthesizing the counterfactual representations. By training the detection model with these synthesized representations, we compel the model to focus on the constant foreground content while minimizing the influence of distracting co-occurring background. To our best knowledge, it is the first attempt in this direction. Extensive experiments on several benchmarks demonstrate that Counterfactual-CAM successfully mitigates the biased activation problem, achieving improved object localization accuracy.
Further Improving Weakly-supervised Object Localization via Causal Knowledge Distillation
Jan 03, 2023



Weakly-supervised object localization aims to indicate the category as well as the scope of an object in an image given only the image-level labels. Most of the existing works are based on Class Activation Mapping (CAM) and endeavor to enlarge the discriminative area inside the activation map to perceive the whole object, yet ignore the co-occurrence confounder of the object and context (e.g., fish and water), which makes the model inspection hard to distinguish object boundaries. Besides, the use of CAM also brings a dilemma problem that the classification and localization always suffer from a performance gap and can not reach their highest accuracy simultaneously. In this paper, we propose a casual knowledge distillation method, dubbed KD-CI-CAM, to address these two under-explored issues in one go. More specifically, we tackle the co-occurrence context confounder problem via causal intervention (CI), which explores the causalities among image features, contexts, and categories to eliminate the biased object-context entanglement in the class activation maps. Based on the de-biased object feature, we additionally propose a multi-teacher causal distillation framework to balance the absorption of classification knowledge and localization knowledge during model training. Extensive experiments on several benchmarks demonstrate the effectiveness of KD-CI-CAM in learning clear object boundaries from confounding contexts and addressing the dilemma problem between classification and localization performance.
Active Learning for Point Cloud Semantic Segmentation via Spatial-Structural Diversity Reasoning
Feb 25, 2022
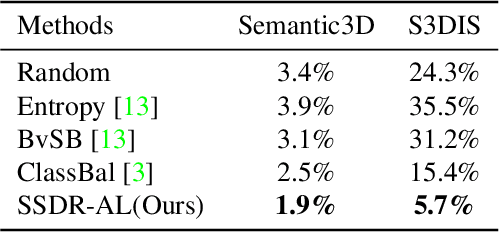
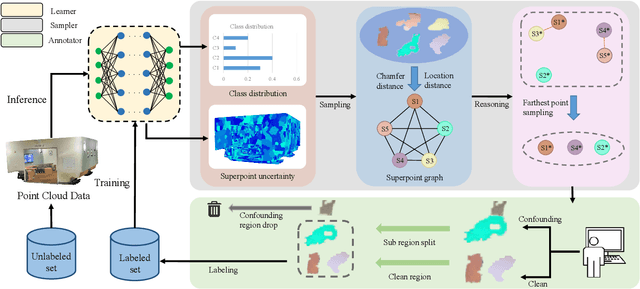

The expensive annotation cost is notoriously known as a main constraint for the development of the point cloud semantic segmentation technique. In this paper, we propose a novel active learning-based method to tackle this problem. Dubbed SSDR-AL, our method groups the original point clouds into superpoints and selects the most informative and representative ones for label acquisition. We achieve the selection mechanism via a graph reasoning network that considers both the spatial and structural diversity of the superpoints. To deploy SSDR-AL in a more practical scenario, we design a noise aware iterative labeling scheme to confront the "noisy annotation" problem introduced by previous dominant labeling methods in superpoints. Extensive experiments on two point cloud benchmarks demonstrate the effectiveness of SSDR-AL in the semantic segmentation task. Particularly, SSDR-AL significantly outperforms the baseline method when the labeled sets are small, where SSDR-AL requires only $5.7\%$ and $1.9\%$ annotation costs to achieve the performance of $90\%$ fully supervised learning on S3DIS and Semantic3D datasets, respectively.
Deep Learning for Weakly-Supervised Object Detection and Object Localization: A Survey
May 26, 2021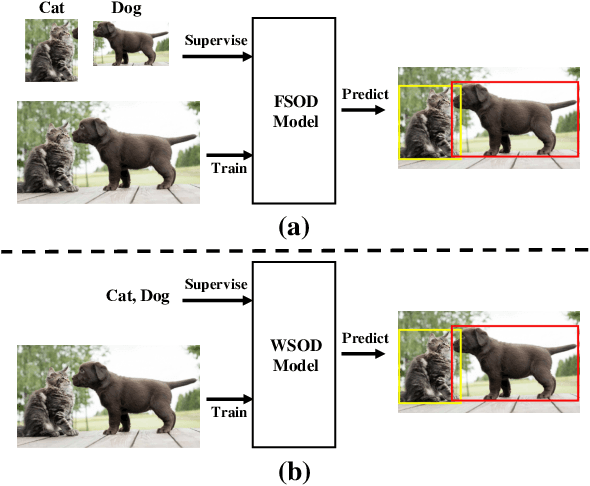
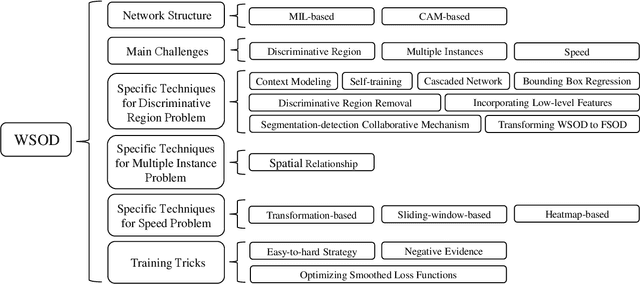

Weakly-Supervised Object Detection (WSOD) and Localization (WSOL), i.e., detecting multiple and single instances with bounding boxes in an image using image-level labels, are long-standing and challenging tasks in the CV community. With the success of deep neural networks in object detection, both WSOD and WSOL have received unprecedented attention. Hundreds of WSOD and WSOL methods and numerous techniques have been proposed in the deep learning era. To this end, in this paper, we consider WSOL is a sub-task of WSOD and provide a comprehensive survey of the recent achievements of WSOD. Specifically, we firstly describe the formulation and setting of the WSOD, including the background, challenges, basic framework. Meanwhile, we summarize and analyze all advanced techniques and training tricks for improving detection performance. Then, we introduce the widely-used datasets and evaluation metrics of WSOD. Lastly, we discuss the future directions of WSOD. We believe that these summaries can help pave a way for future research on WSOD and WSOL.
Improving Weakly-supervised Object Localization via Causal Intervention
Apr 21, 2021
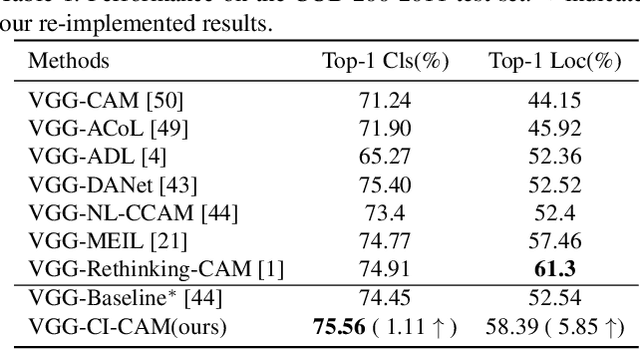
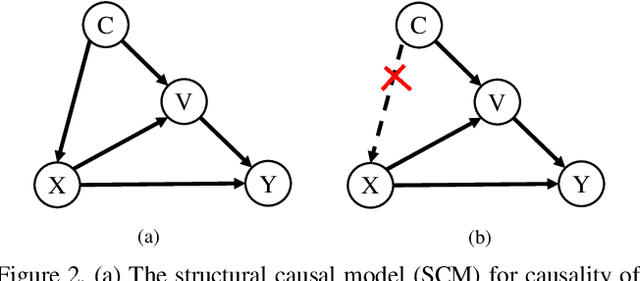
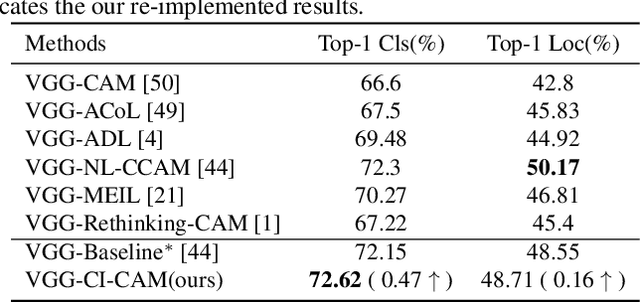
The recent emerged weakly supervised object localization (WSOL) methods can learn to localize an object in the image only using image-level labels. Previous works endeavor to perceive the interval objects from the small and sparse discriminative attention map, yet ignoring the co-occurrence confounder (e.g., bird and sky), which makes the model inspection (e.g., CAM) hard to distinguish between the object and context. In this paper, we make an early attempt to tackle this challenge via causal intervention (CI). Our proposed method, dubbed CI-CAM, explores the causalities among images, contexts, and categories to eliminate the biased co-occurrence in the class activation maps thus improving the accuracy of object localization. Extensive experiments on several benchmarks demonstrate the effectiveness of CI-CAM in learning the clear object boundaries from confounding contexts. Particularly, in CUB-200-2011 which severely suffers from the co-occurrence confounder, CI-CAM significantly outperforms the traditional CAM-based baseline (58.39% vs 52.4% in top-1 localization accuracy). While in more general scenarios such as ImageNet, CI-CAM can also perform on par with the state of the arts.