 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByteLoom: Weaving Geometry-Consistent Human-Object Interactions through Progressive Curriculum Learning
Dec 28, 2025Human-object interaction (HOI) video generation has garnered increasing attention due to its promising applications in digital humans, e-commerce, advertising, and robotics imitation learning. However, existing methods face two critical limitations: (1) a lack of effective mechanisms to inject multi-view information of the object into the model, leading to poor cross-view consistency, and (2) heavy reliance on fine-grained hand mesh annotations for modeling interaction occlusions. To address these challenges, we introduce ByteLoom, a Diffusion Transformer (DiT)-based framework that generates realistic HOI videos with geometrically consistent object illustration, using simplified human conditioning and 3D object inputs. We first propose an RCM-cache mechanism that leverages Relative Coordinate Maps (RCM) as a universal representation to maintain object's geometry consistency and precisely control 6-DoF object transformations in the meantime. To compensate HOI dataset scarcity and leverage existing datasets, we further design a training curriculum that enhances model capabilities in a progressive style and relaxes the demand of hand mesh. Extensive experiments demonstrate that our method faithfully preserves human identity and the object's multi-view geometry, while maintaining smooth motion and object manipulation.
DreamSwapV: Mask-guided Subject Swapping for Any Customized Video Editing
Aug 20, 2025With the rapid progress of video generation, demand for customized video editing is surging, where subject swapping constitutes a key component yet remains under-explored. Prevailing swapping approaches either specialize in narrow domains--such as human-body animation or hand-object interaction--or rely on some indirect editing paradigm or ambiguous text prompts that compromise final fidelity. In this paper, we propose DreamSwapV, a mask-guided, subject-agnostic, end-to-end framework that swaps any subject in any video for customization with a user-specified mask and reference image. To inject fine-grained guidance, we introduce multiple conditions and a dedicated condition fusion module that integrates them efficiently. In addition, an adaptive mask strategy is designed to accommodate subjects of varying scales and attributes, further improving interactions between the swapped subject and its surrounding context. Through our elaborate two-phase dataset construction and training scheme, our DreamSwapV outperforms existing methods, as validated by comprehensive experiments on VBench indicators and our first introduced DreamSwapV-Benchmark.
Bidirectional Self-Training with Multiple Anisotropic Prototypes for Domain Adaptive Semantic Segmentation
Apr 16, 2022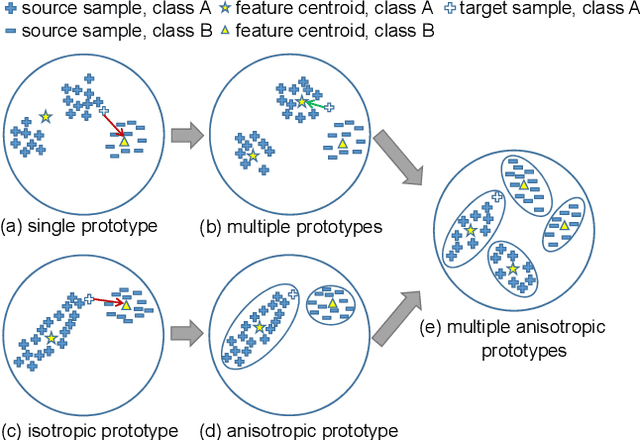
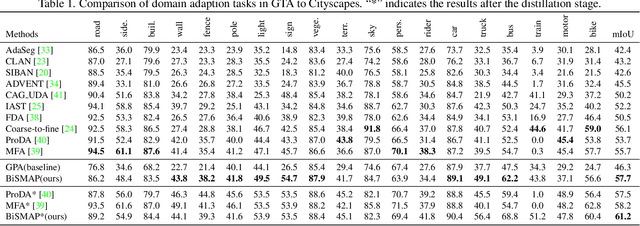
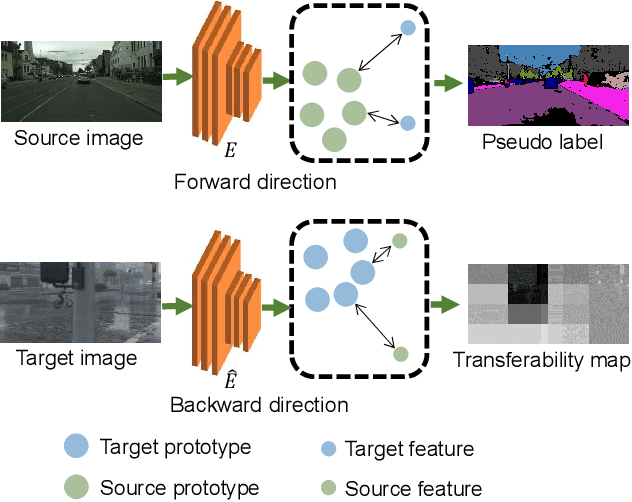

A thriving trend for domain adaptive segmentation endeavors to generate the high-quality pseudo labels for target domain and retrain the segmentor on them. Under this self-training paradigm, some competitive methods have sought to the latent-space information, which establishes the feature centroids (a.k.a prototypes) of the semantic classes and determines the pseudo label candidates by their distances from these centroids. In this paper, we argue that the latent space contains more information to be exploited thus taking one step further to capitalize on it. Firstly, instead of merely using the source-domain prototypes to determine the target pseudo labels as most of the traditional methods do, we bidirectionally produce the target-domain prototypes to degrade those source features which might be too hard or disturbed for the adaptation. Secondly, existing attempts simply model each category as a single and isotropic prototype while ignoring the variance of the feature distribution, which could lead to the confusion of similar categories. To cope with this issue, we propose to represent each category with multiple and anisotropic prototypes via Gaussian Mixture Model, in order to fit the de facto distribution of source domain and estimate the likelihood of target samples based on the probability density. We apply our method on GTA5->Cityscapes and Synthia->Cityscapes tasks and achieve 61.2 and 62.8 respectively in terms of mean IoU, substantially outperforming other competitive self-training methods. Noticeably, in some categories which severely suffer from the categorical confusion such as "truck" and "bus", our method achieves 56.4 and 68.8 respectively, which further demonstrates the effectiveness of our design.
Active Learning for Point Cloud Semantic Segmentation via Spatial-Structural Diversity Reasoning
Feb 25, 2022
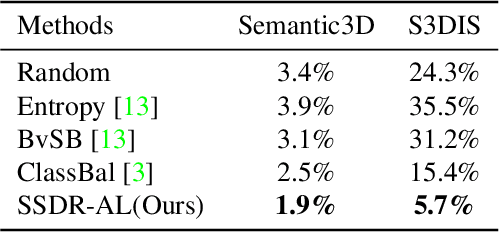
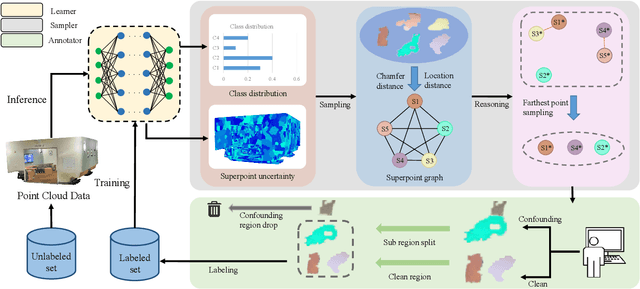

The expensive annotation cost is notoriously known as a main constraint for the development of the point cloud semantic segmentation technique. In this paper, we propose a novel active learning-based method to tackle this problem. Dubbed SSDR-AL, our method groups the original point clouds into superpoints and selects the most informative and representative ones for label acquisition. We achieve the selection mechanism via a graph reasoning network that considers both the spatial and structural diversity of the superpoints. To deploy SSDR-AL in a more practical scenario, we design a noise aware iterative labeling scheme to confront the "noisy annotation" problem introduced by previous dominant labeling methods in superpoints. Extensive experiments on two point cloud benchmarks demonstrate the effectiveness of SSDR-AL in the semantic segmentation task. Particularly, SSDR-AL significantly outperforms the baseline method when the labeled sets are small, where SSDR-AL requires only $5.7\%$ and $1.9\%$ annotation costs to achieve the performance of $90\%$ fully supervised learning on S3DIS and Semantic3D datasets, respectively.